
使用 CopyOnWrite 实现并发写操作
接下来我们会给大家详细的介绍 JUC 包中的 CopyOnWrite、ReadWriteLock、ConcurrentHashMap、BlockingQueue 和 CountDownLatch 等常用并发工具类,这些工具类是对多线程高级编程的重要支撑。我们先来看看使用 CopyOnWrite 是怎样实现并发写操作的。
我们先要理清的一个概念是同步容器类和并发容器类。先看几个同步容器类,比如 Hashtable、Vector、Stack,其中 Stack 继承于 Vector,同步容器类是一种串行化、线程安全的容器,在特定的情况下会对资源加锁。由于会加锁所以会在多线程的环境中降低应用的吞吐量。所以,同步容器类在早期设计时没有考虑一些并发问题,因此在使用时经常会出现 ConcurrentModificationException 等并发异常。
我们在终端中输入以下的命令先创建一个简单的项目结构:
mkdir demo demo/bin demo/lib demo/src
然后我们在路径 /demo/src 下面新建 TestCopyOnWriteArrayList.java 文件。
import java.util.Iterator;
import java.util.Vector;
public class TestCopyOnWriteArrayList {
public static void main(String[] args) {
Vector<String> names = new Vector<>() ;
names.add("zs") ;
names.add("ls") ;
names.add("ww") ;
Iterator<String> iter = names.iterator();
while(iter.hasNext()) {
System.out.println(iter.next());
names.add("x");
}
}
}
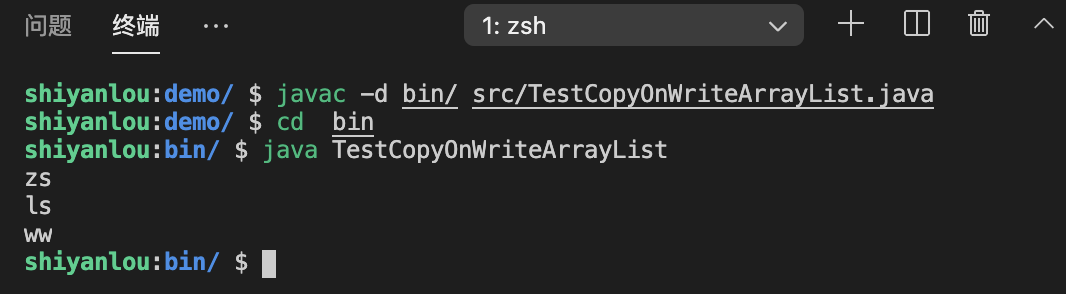
然后我们把终端中的路径切换到 demo 下,编译并运行上面的程序:
cd demo
javac -d bin/ src/TestCopyOnWriteArrayList.java
cd bin
java TestCopyOnWriteArrayList
然后得到抛出的异常 ConcurrentModificationException:

大家可以再试看看将程序中的 Vector 改成 ArrayList 会是什么结果,即将 Vector 替换成 ArrayList。
ArrayList<String> names = new ArrayList<>()
结果是还是会出现相同的异常。并且产生异常的原因和使用 Vector 是一致的,我们以 ArrayList 为例来阐述一下。
在 ArrayList 中有一个从父类 AbstractList 继承过来的全局变量 modCount,并且在 ArrayList 的内部类 Itr 中有一个 expectedModCount 变量。当我们对 ArrayList 进行迭代的时候,我们在上面有一个 iter.next()就是在对当前集合进行遍历,迭代器会先确保 modCount 和 expectedModCount 的值是保持一致的,如果不一致的话就会抛出 ConcurrentModificationException 异常。
之所以抛出了异常是因为我们在迭代的同时,又进行了写的操作(names.add(…)),而写的操作会改变 modCount 的值,因此就会导致了 modCount 和 expectedModCount 不一致,那么最终就会抛出 ConcurrentModificationException 这个异常。
另外在这里补充一点,我们将 modCount 和 expectedModCount 的值是否相等来确保数据一致性的方法称之为“fail-fast 策略”,这与 CAS 的思想有着异曲同工之处。
如何解决这样的问题呢,我们抛出这个问题,此时就会引进我们的另外一个工具,即并发容器类。JUC 提供了多种并发类容器来改善性能,并且也解决了上述异常。如果在多线程环境下编程,建议使用并发类容器来替代传统的同步类容器。
| 同步类容器 | 并发类容器 |
|---|---|
| HashTable | ConcurrentHashMap |
| Vector | copyOnWriteArrayList |
除了 ConcurrentHashMap 和 CopyOnWriteArryList 以外,JUC 还提供了 CopyonWriteArraySet、ConcurrentLinkedQueue、PriorityBlockingQueue 等并发类容器。
现在,我们把程序中的 Vector 改为 CopyOnWriteArrayList,即改为如下的代码就可以得到正常的输出。
CopyOnWriteArrayList<String> names = new CopyOnWriteArrayList<String>();
完整的修改过后的 TestCopyOnWriteArrayList.java 文件的内容如下所示:
import java.util.Iterator;
import java.util.concurrent.CopyOnWriteArrayList;
public class TestCopyOnWriteArrayList {
public static void main(String[] args) {
CopyOnWriteArrayList<String> names = new CopyOnWriteArrayList<String>();
names.add("zs") ;
names.add("ls") ;
names.add("ww") ;
Iterator<String> iter = names.iterator();
while(iter.hasNext()) {
System.out.println(iter.next());
names.add("x");
}
}
}
CopyOnWrite 容器(包含 CopyOnWriteArrayList 和 CopyOnWriteArraySet),正如它的名字一样:当遇到写操作(即增删改)时,就会将容器自身复制一份。以增加为例,当向一个 CopyOnWrite 容器增加元素的时候,会经历以下两步:
- 先将当前容器复制一份,然后向新的容器(复制后的容器)里添加元素(并不会直接向当前容器中增加元素)。
- 增加完元素之后,再将引用指向新的容器;原容器等待被 GC 收集。
实质上,CopyOnWrite 就是利用冗余实现了读写分离:在对容器进行写操作的同时(即容器已经复制了一份,但引用还没有改变指向的时候),原容器仍然可以处理用户的读请求。这样一来,既没有加锁,又以读写分离的形式处理了并发的读和写请求:在原容器中处理读请求,在新容器中处理写请求。
因此,如果对于“读多写少”的业务,就更适合使用 CopyOnWrite 容器;但如果是“写多读少”就不适合,因为容器的复制比较消耗性能。
使用 ReadWriteLock 实现读写锁
上面我们介绍了 CopyOnWrite 利用冗余实现了读写分离,为了更好的解决多个线程读写带来的并发问题,JUC 还提供了专门的读写锁 ReadWriteLock,可以用于分别对读操作或写操作进行加锁,ReadWriteLock 在 JDK 中的源码如下所示。
package java.util.concurrent.locks;
public interface ReadWriteLock {
Lock readLock();
Lock writeLock();
}
源码中 readLock()用和 writeLock()的含义如下所示。
- readLock():读锁。加了读锁的资源,可以在没有写锁的时候被多个线程共享。我们可以假设,如果存在一个 t1 线程已经获取了读锁,那么此时:如果另外一个 t2 线程要申请写锁,则 t2 会一直等待 t1 释放读锁;如果 t2 线程要申请读锁,则 t2 可以直接访问读锁,也就是说 t1 和 t2 可以共享资源,就和没加锁的效果一样。
- writeLock():写锁是一种独占锁。加了写锁的资源,不能再被其他线程读或写。换句话说,如果 t1 已经获取了写锁,那么此时无论线程 t2 要申请写锁或者读锁,都必须得等待 t1 释放写锁。
接下来我们通过一个具体的小 demo 来看看读写锁的作用。
我们继续在项目 demo 的 src 文件夹下面新建 TestReadWriteLock.java 文件。
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class TestReadWriteLock {
// 读写锁
private ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
public static void main(String[] args) {
TestReadWriteLock test = new TestReadWriteLock();
//t1线程
new Thread(() -> {
//读操作
test.myRead(Thread.currentThread());
//写操作
test.myWrite(Thread.currentThread());
}, "t1").start();
//t2线程
new Thread(() -> {
//读操作
test.myRead(Thread.currentThread());
//写操作
test.myWrite(Thread.currentThread());
}, "t2").start();
}
//用读锁来锁定读操作
public void myRead(Thread thread) {
rwl.readLock().lock();
try {
for (int i = 0; i < 6; i++) {
System.out.println(thread.getName() + "正在进行读操作");
}
System.out.println(thread.getName() + "===读操作完毕===");
} finally {
rwl.readLock().unlock();
}
}
//用写锁来锁定写操作
public void myWrite(Thread thread) {
rwl.writeLock().lock();
try {
for (int i = 0; i < 6; i++) {
System.out.println(thread.getName() + "正在进行写操作");
}
System.out.println(thread.getName() + "===写操作完毕===");
} finally {
rwl.writeLock().unlock();
}
}
}
然后我们在终端中输入下面的指令就可以实现编译运行并输出,需要注意我们执行 java 命令是要在 bin 目录下面。
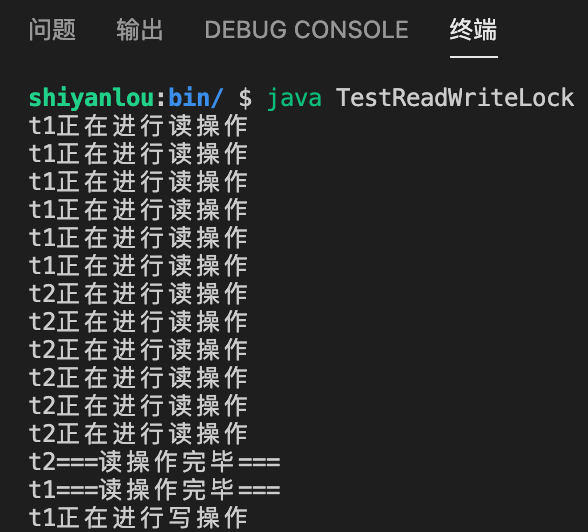
从结果我们可以看到,本程序有 2 个线程,如果一个线程获取了读锁 readLock().lock() ,那么与此同时,另一个线程也可以读取该读锁中的资源;但如果一个线程获取了写锁 writeLock().lock() ,那么另一个线程就必须等待写锁的释放之后才可以执行写的操作。
ConcurrentHashMap 的底层结构与演进过程
HashMap 相信大家应该都是使用过的,这里我们重点要给大家介绍并发包中的 ConcurrentHashMap,CopyOnWrite 容器可以解决 List 等单值集合的并发问题,与之类似的是 ConcurrentHashMap 可以用于解决 HashMap 等 key-value 集合的并发问题。在这里我们会讲解 JDK7 和 JDK8 两个重要版本中的 ConcurrentHashMap 底层结构,大家可以从中体验源码设计思路的演进。
JDK7 中的 ConcurrentHashMap
在介绍 ConcurrentHashMap 之前我们先回顾一下 HashMap,在 JDK8 以前,HashMap 是基于数组+链表的实现形式的,整体上看 HashMap 是一个数组,但是每一个数组元素又是一张链表。
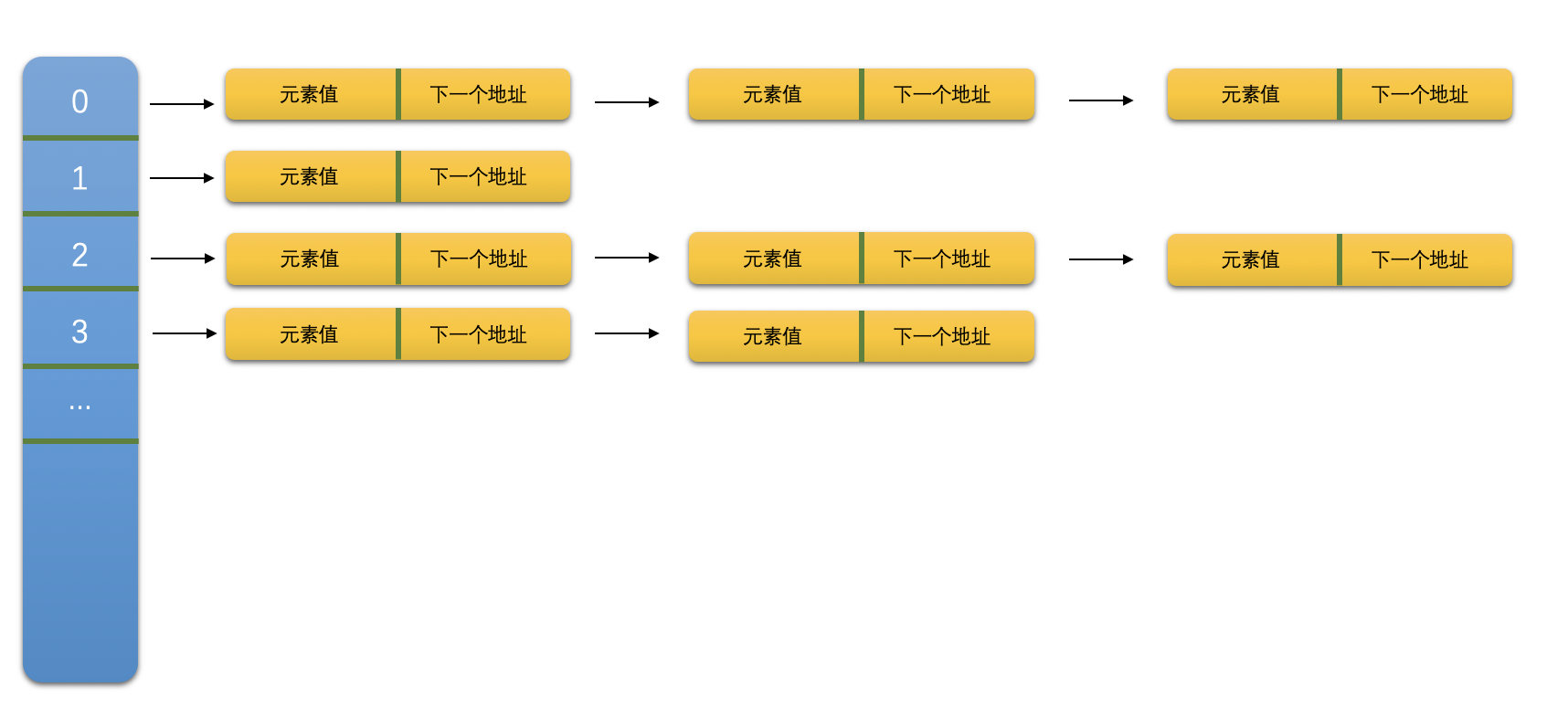
JDK8 以前的 ConcurrentHashMap 间接的实现了 Map<K,V>,并将每一个元素称为一个 segment,每个 segment 都是一个 HashEntry<K,V>数组(称为 table),table 的每个元素都是一个 HashEntry 的单向队列,如下图所示。
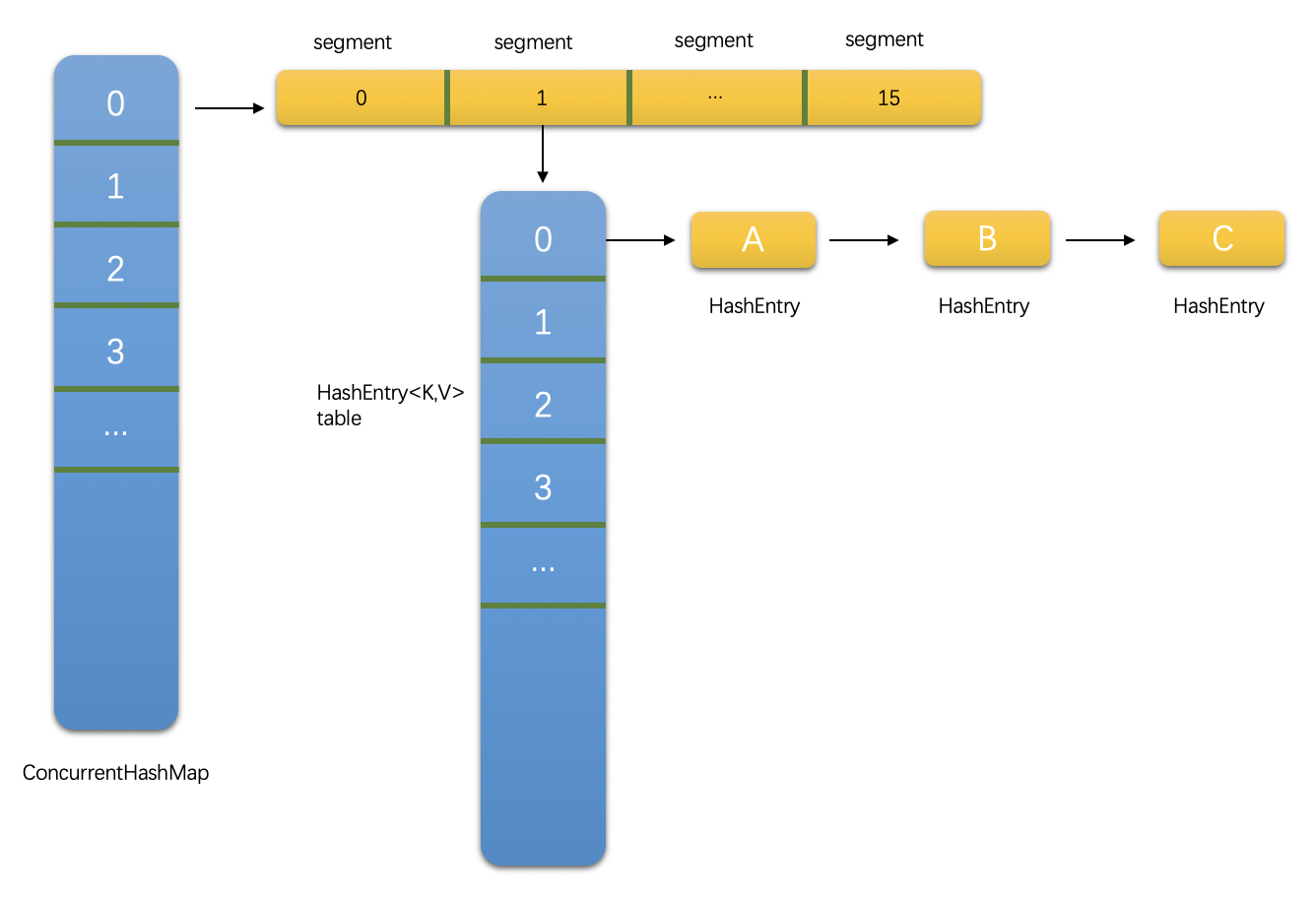
默认情况下此 ConcurrentHashMap 会生成 16 个 segment,采用此结构的 ConcurrentHashMap 解决并发问题的思路是以更加细粒度的给 map 加锁。我们知道 HashtMap 是非线程安全的,而线程安全的 Hashtable 在并发写环境下会给整个 Hashtable 容器加上锁。但是如果有多个线程同时修改 Hashtable,仍然会发生写冲突,从而导致并发异常。而 ConcurrentHashMap 不会给整个容器加锁,而是会给容器中的每个 segment 都加一把锁(即将一把“大锁”拆分成了多个“小锁”),即减小锁的粒度。这样一来,在第一个线程修改某个 segment 的同时,其他线程也可以修改其余的 segment,即只要各个线程同一时刻访问的是不同的 segment,就不会发生写冲突。
JDK8 中的 ConcurrentHashMap
从 JDK8 开始,HashMap/ConcurrentHashMap 的存储结构发生了改变:增加了条件性的“红黑树”。
为了优化查询,当链表中的元素超过 8 个时,HashMap 就会将该链表转换为红黑树,即采用了数组+链表/红黑树的存储结构,如下图所示:
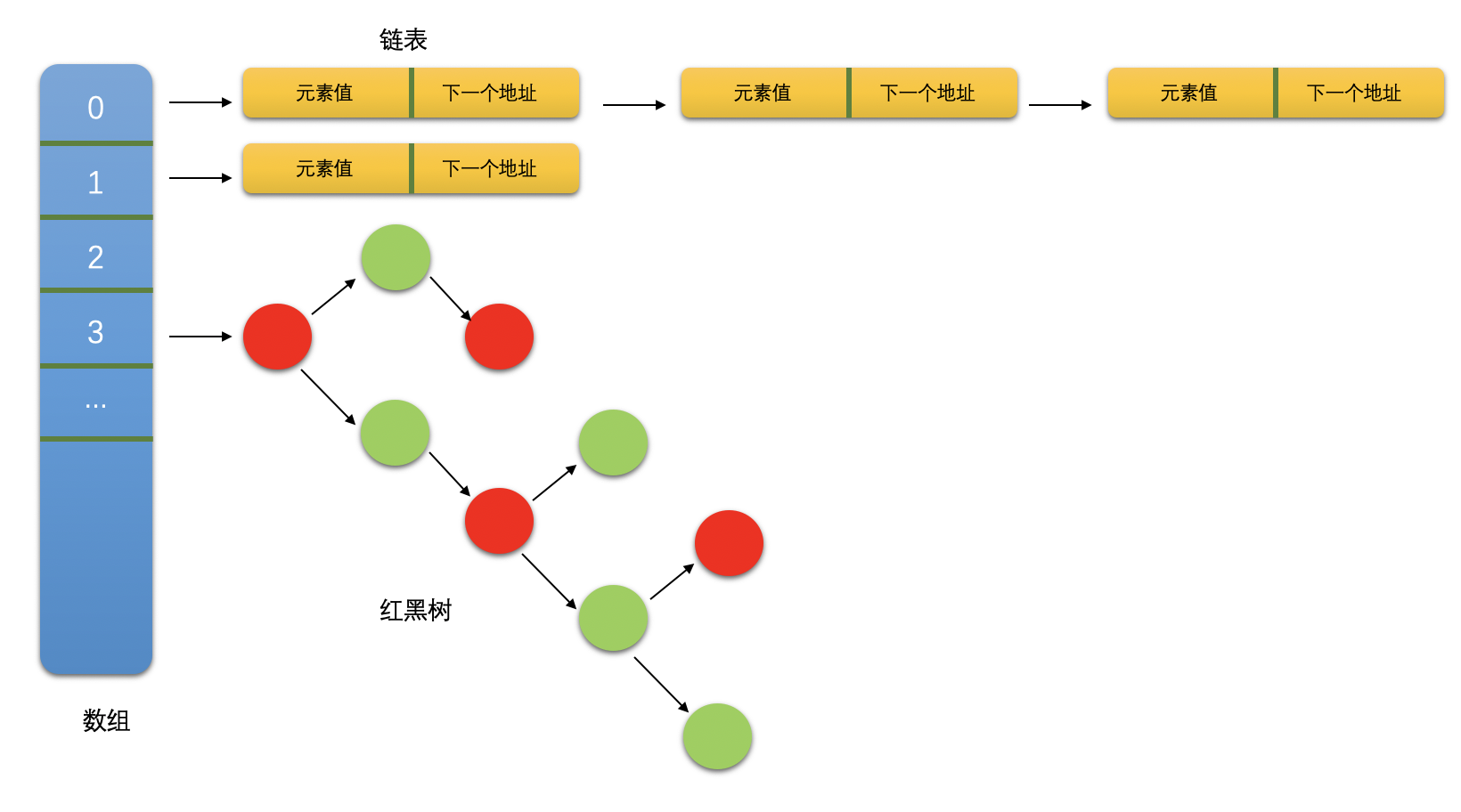
不仅仅是 HashMap,JDK8 中的 ConcurrentHashMap 也改为了数组+链表/红黑树的存储结构,并且废弃了 segment(即放弃了对 segment 的加锁操作),采用了比之前 segment 还要细粒度的“锁”:直接采用 volatile HashEntry<K,V>对象保存数据,即对每一条数据直接通过 volatile 避免冲突(即将 segment 的“小段锁”,改为了对每个元素进行一次 volatile)。此外,JDK8 中的 ConcurrentHashMap 还使用了大量的 synchronized 和 CAS 算法来保证线程安全。
虽然 ConcurrentHashMap 比 HashMap 更加适合高并发场合,但在 JDK8 中二者的结构图基本一致,读者可以用上面的 HashMap 结构图来理解 ConcurrentHashMap。
另外需要注意的是,ConcurrentHashMap 和 HashMap 是同一层次的,它俩都是 AbstractMap 的子类,二者之间没有继承关系。
接下来我们用一个基础的示例来说明一下 ConcurrentHashMap 的使用:
public class TestConcurrentHashMap {
public static void main(String[] args) {
ConcurrentHashMap<String, String> chm = new ConcurrentHashMap<>();
chm.put("key1", "value1");
chm.put("key2", "value2");
chm.put("key3", "value3");
chm.putIfAbsent("key3", "value3");//如果key已存在,则不再增加
chm.putIfAbsent("key4", "value4");//如果key不存在,则增加
System.out.println(chm);
}
}
我们在 src 文件夹下面新建一个 TestConcurrentHashMap.java 文件。并对其进行编译和运行,首先大家还是按照之前介绍的常规的步骤确保工作空间在 demo 目录下面:
javac -d bin/ src/TestConcurrentHashMap.java
cd bin
java TestConcurrentHashMap

使用 BlockingQueue 实现排序和定时任务
还记得吗,我们之前在 上一讲生产消费者程序中使用到的 BlockingQueue,也是 JUC 提供的一个用于控制线程同步的队列,BlockingQueue 还可以对队列中的元素排序以及实现定时任务等功能,其在 JDK 中的源码如下所示。我们可以去 java.util.concurrent 包中去看有关 BlockingQueue 的源码,它提供了很多方法,我们挑它其中的有关向队列中增加元素的一个方法来阐述一下。
向队列中增加元素的方法是 add()、put()和 offer(),具体如下所示。
- add():向 BlockingQueue 中增加元素;如果 BlockingQueue 中有剩余空间,则返回 true,否则抛出异常,通常与 poll()结合使用。
- offer():向 BlockingQueue 中增加元素;如果 BlockingQueue 中有剩余空间,则返回 true,否则返回 false,通常与 poll()结合使用。
- put():向 BlockingQueue 中增加元素;如果 BlockingQueue 已满,则当前线程一直等待,即满则阻塞线程,通常与 take()结合使用。
从队列中取出元素的方法是 poll()和 take(),具体如下面所示:
- poll():取出排在 BlockingQueue 队首的元素;若队列为空,则会持续等待一定时间,如果等待之后队列仍然为空则返回 null。
- take():取出排在 BlockingQueue 队首的元素;若队列为空,则当前线程一直等待,同 put()阻塞线程的效果一样。
我们再用一个表格来看一下 BlockingQueue 中操作队列元素的方法:
| 方法 | 简介 |
|---|---|
| remainingCapacity() | 返回队列的剩余容量。注意:当线程 A 调用此方法后,队列可能被其他线程进行了增减操作,因此线程 A 看到的数字不具备实时性。 |
| remove(Object o) | 删除队列中的 o 元素。 |
| contains(Object o) | 判断队列中是否包含 o 元素。 |
| drainTo(Collection c) | 将队列中的元素全部转移到集合 c 中。 |
| drainToCollection c, int maxElements) | 将队列中的前 maxElements 个元素,转移到集合 c 中。 |
关于 BlockingQueue 的种类,我们从它的实现类来看,主要分的有有界队列和无界队列两种,区别有界和无界主要是通过其中的元素的个数是否有限来区别的,BlockingQueue 的实现类主要有以下几种:
- ArrayBlockingQueue:由数组构成的有界阻塞队列,队列的大小由构造方法的参数指定。
- LinkedBlockingQueue:由链表结构组成的有界阻塞队列。可以通过构造方法的参数指定队列的大小;如果使用的是无参构造方法,则队列默认的大小是
Integer.MAX_VALUE。 - PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列,排序规则可以通过构造方法中的 Comparator 对象指定。
- DelayQueue:一个支持延迟存取的无界队列,例如队列中的某个元素必须在一定时间后才能被取出。
接下来我们通过一个具体的实例来看看其中的一种实现类 PriorityBlockingQueue,对队列中的对象进行排序。
在 src/ 目录下面目录下面新建 TestPriorityBlockingQueue.java 文件:
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.PriorityBlockingQueue;
public class TestPriorityBlockingQueue {
public static void main(String[] args) throws Exception{
//通过构造方法,传入一个实现了Comparable接口的MyJob类,在MyJob类中通过重写compareTo()定义了优先级规则
BlockingQueue<MyJob> priorityQueue = new PriorityBlockingQueue<MyJob>();
priorityQueue.add(new MyJob(3));
priorityQueue.add(new MyJob(2));
priorityQueue.add(new MyJob(1));
//注意:优先级的排序规则,会在第一次调用take()方法之后才生效
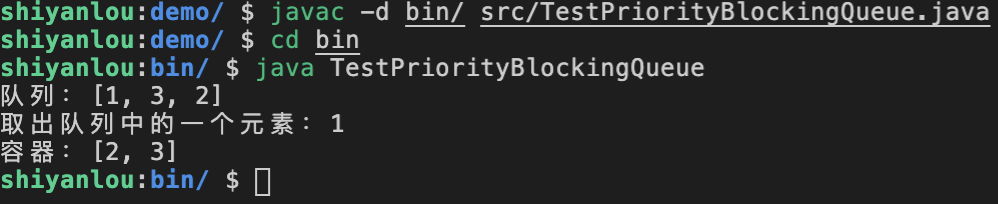
System.out.println("队列:"+ priorityQueue);//默认队中的顺序是3,2,1
//排序后,队中的顺序是1,2,3
System.out.println("取出队列中的一个元素:" +priorityQueue.take().getId());
System.out.println("容器:"+ priorityQueue);
}
}
class MyJob implements Comparable<MyJob> {
private int id;
public MyJob(int id) {
this.id = id;
}
//省略setter、getter
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
@Override
public int compareTo(MyJob job) {
return this.id > job.id ? 1 : (this.id < job.id ? -1 : 0);
}
@Override
public String toString() {
return String.valueOf(this.id);
}
}
我们可以看到运行的结果如下图所示:
接下来我们又来测试另外一个延迟阻塞队列,在路径 src/ 下面新建一个 TestNatatorium.java 文件。
import java.util.concurrent.DelayQueue;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
/* 测试类 */
public class TestNatatorium {
public static void main(String args[]) {
try {
Natatorium natatorium = new Natatorium();
Thread nataThread = new Thread(natatorium);
nataThread.start();
natatorium.addSwimmer("zs", 1);
natatorium.addSwimmer("ls", 2);
natatorium.addSwimmer("ww", 3);
} catch (Exception e) {
e.printStackTrace();
}
}
}
/* 游泳馆类 */
class Natatorium implements Runnable {
// 用延迟队列模拟多个Swimmer,每个Swimmer的getDelay()方法表示自己剩余的游泳时间
private DelayQueue<Swimmer> queue = new DelayQueue<Swimmer>();
// 标识游泳馆是否开业
private volatile boolean isOpen = true;
// 向DelayQueue中增加游泳者
public void addSwimmer(String name, int playTime) {
// 规定游泳的结束时间
long endTime = System.currentTimeMillis() + playTime * 1000 * 60;
Swimmer swimmer = new Swimmer(name, endTime);
System.out.println(swimmer.getName() + "进入游泳馆,可供游泳时间:"
+ playTime + "分");
this.queue.add(swimmer);
}
@Override
public void run() {
while (isOpen) {
try {
/*
* 注意:在DelayQueue中,take()并不会立刻取出元素。
* 只有当元素(Swimmer)所重写的getDelay()返回0或者负数时,才会真正取出该元素。
*/
Swimmer swimmer = queue.take();
System.out.println(swimmer.getName() + "游泳时间结束");
// 如果DelayQueue中的元素已被取完,则停止线程
if (queue.size() == 0) {
isOpen = false;
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
/* 游泳者类 */
class Swimmer implements Delayed {
private String name;
private long endTime;
public Swimmer(String name, long endTime) {
this.name = name;
this.endTime = endTime;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public long getEndTime() {
return endTime;
}
public void setEndTime(long endTime) {
this.endTime = endTime;
}
/*
获取剩余时间。
如果返回正数,代表剩余的时间;
如果返回0或者负数,说明已超时;当超时时,才会让DelayQueue的take()方法真正取出元素。
*/
@Override
public long getDelay(TimeUnit unit) {
return endTime - System.currentTimeMillis();
}
//线程(游泳者)之间,根据剩余时间的大小进行排序
@Override
public int compareTo(Delayed delayed) {
Swimmer swimmer = (Swimmer) delayed;
return this.getDelay(TimeUnit.SECONDS)
- swimmer.getDelay(TimeUnit.SECONDS) >0 ? 1 : 0;
}
}
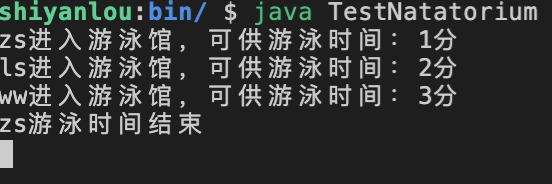
程序运行的结果如下:下面我们截取了在第一个游泳者 zs 游泳完的结果展示。
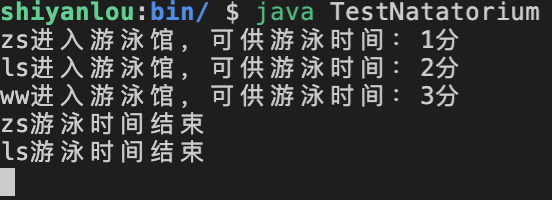
当然再等一分钟之后另外一个游泳者也会游泳完的,即当三位游泳者的游泳时间结束时,就会陆续收到提示。
上面程序中的游泳者 Swimmer 实现了 Delayed 接口,重写了里面的两个方法 getDelay()和 compareTo(),这样子就实现了当只有每个游泳者可以游泳的时间耗尽了之后才可以从 DelayQueue 中被取出来,然后会一直在 while(isOpen)的轮询中去检查下面这行代码是否可以取出一个 Swimmer 对象出来。
Swimmer swimmer = queue.take();
通过 CountDownLatch 实现多线程闭锁
CountDownLatch 是一个同步工具类,可以用来协调多个线程的执行时间。例如,可以让 A 线程在其他线程运行完毕后再执行;也就是说,如果其他线程没有执行完毕,则 A 线程就会一直等待。这种特性,也称为线程的闭锁。顾名思义,“闭锁”就是指一个被锁住了的门,就是指将线程 A 挡在了门外(等待执行),只有当门打开之后(其他线程执行完毕),门上的锁才会被打开,A 才能够继续执行。
闭锁通常用于以下场景:
- 确保某个计算,在其需要的所有资源都准备就绪后再执行;
- 确保某个服务,在其依赖的所有其他服务都已经启动之后再启动;
- 确保某个任务,在所有参与者都准备就绪之后再执行。
在 JUC 中,可以使用 CountDownLatch 实现闭锁。其原理是,CountDownLatch 在创建时,会指定一个计数器,表示等待线程的执行数量,之后其他每个线程在各自执行完毕时,分别调用一次 countDown()方法,用来递减计数器,表示有一个线程已经执行完毕了。与此同时,线程 A 可以调用 await()方法,用来等待计数器达到零。如果计数器的值大于零,那么 await 方法会一直阻塞;直到计数器为零时,线程 A 才会继续执行。特殊的,如果线程 A 一直无法等到计数器为 0,则会显示等待超时;当然也可以在线程 A 等待时,通过程序中断等待。下面我们用一段代码来展示一下线程闭锁的场景。只有当其他线程全部执行完毕之后,main 才可以继续执行。
我们在 src/ 文件夹下新建 TestCountDownLatch.java 文件。
import java.util.concurrent.CountDownLatch;
public class TestCountDownLatch {
public static void main(String[] args) {
//计数器为10
CountDownLatch countDownLatch = new CountDownLatch(10);
/*
将CountDownLatch对象传递到线程的run()方法中,当每个线程执行完
毕run()之后都会将计数器减1
*/
MyThread myThread = new MyThread(countDownLatch);
long start = System.currentTimeMillis();
//创建10个线程,并执行
for (int i = 0; i < 10; i++) {
new Thread(myThread).start();
}
try {
/*
主线程(main)等待:等待计数器减为0;即当CountDownLatch中的计数器为0时,
main线程才会继续执行。
*/
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start));
}
}
class MyThread implements Runnable {
private CountDownLatch latch;
public MyThread(CountDownLatch latch) {
this.latch = latch;
}
@Override
public void run() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//每个子线程执行完毕后,均触发一次countDown(),将计数器减1
latch.countDown();
}
}
}
然后在按照之前介绍的编译方法对我们的这个类文件编译运行可以得到下面的运行结果,截图包含了操作过程,注意下每一行的工作目录的变化。

现在让我们站在 main 线程的角度,它经历了以下的一些步骤:
- 在开始时记录了执行时间 start 。
- 在执行时创建了 10 个子线程,并通过 CountDownLatch 的 await()方法等待子线程执行完毕。
- 当子线程全部执行完毕后,main 线程结束了 await()等待,继续往下执行,继而记录了结束时间 end。
- 最后通过 end-start 计算出 main 线程的耗时时间。
使用 CyclicBarrier 在多线程中设置屏障
与 CountDownLatch 类似,CyclicBarrier 也可以用于解决多个线程之间的相互等待问题。CyclicBarrier 的使用场景是:每个线程在执行时,都会碰到屏障,该屏障会拦截所有线程的执行(通过 await()方法实现),当指定数量的线程全部就位时,所有的线程再跨过屏障同时执行。
现举例说明 CountDownLatch 和 CyclicBarrier 的区别:假设有 A、B、C 三个线程,其中 C 是最后一个加入的线程。
- 使用 CountDownLatch 可以实现:当 A 和 B 全部执行完毕后,C 再去执行。
- 使用 CyclicBarrier 可以实现:当 A、B 等到 C 就绪时即执行完毕时,A、B、C 三者再同时去执行。
我们具体使用一个业务场景来描述线程屏障的问题:
在路径 src/ 下面新建 TestCyclicBarrier.java 文件。
import java.io.IOException;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TestCyclicBarrier {
static class MyThread implements Runnable {
//用于控制会议开始的屏障
private CyclicBarrier barrier;
//参会人员
private String name;
public MyThread(CyclicBarrier barrier, String name) {
this.barrier = barrier;
this.name= name;
}
@Override
public void run() {
try {
Thread.sleep((int) (10000 * Math.random()));
System.out.println(this.name + " 已经到会...");
barrier.await();
} catch(InterruptedException e){
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println(this.name+ " 开始会议...");
}
}
public static void main(String[] args) throws IOException, InterruptedException {
//将屏障设置为3,即当有3个线程全部执行完await()时,再一起释放
CyclicBarrier barrier = new CyclicBarrier(3);
ExecutorService executor = Executors.newFixedThreadPool(3);
//三个人去开会
executor.submit(new MyThread(barrier, "zs"));
executor.submit(new MyThread(barrier, "ls"));
executor.submit(new MyThread(barrier, "ww"));
//executor.shutdown();
}
}
然后我们在终端中编译并运行上面的程序,可到运行的结果如下所示:
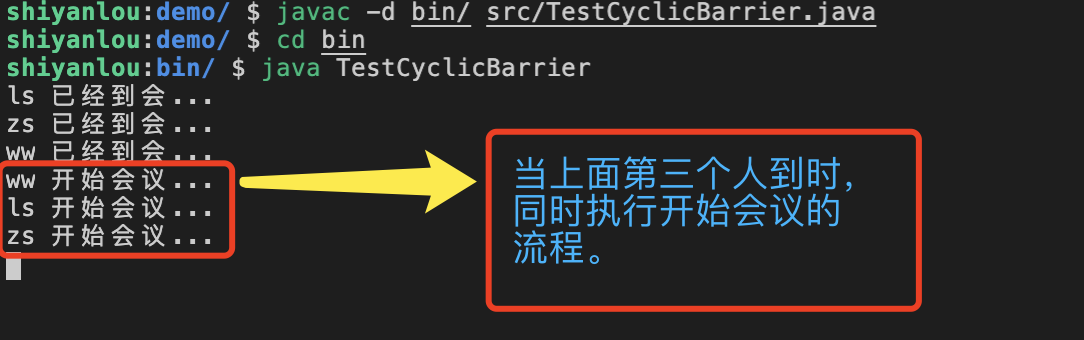
使用 Callable 和 FutureTask 实现多线程
我们知道,要创建一个线程,可以是继承自 Thread 类,或者实现 Runnable 接口。但 JUC 还提供了另外一种方式:通过 Callable 和 FutureTask 创建并使用线程。我们在这里先介绍一下 FutureTask 和 Callable 的核心用法。
FutureTask
Future 是 JDK 提供的用于处理多线程环境下异步问题的一种模式,而 FutureTask 就是对 Future 模式的一种实现。下面我们可以先通过一段对话了解一下什么是“Future 模式”。
老板:小王,把会议纪要整理好给我。
小王:好的,没问题。
随后,小王立刻开始整理,几分钟之后,小王将整理好的文件送给了老板。
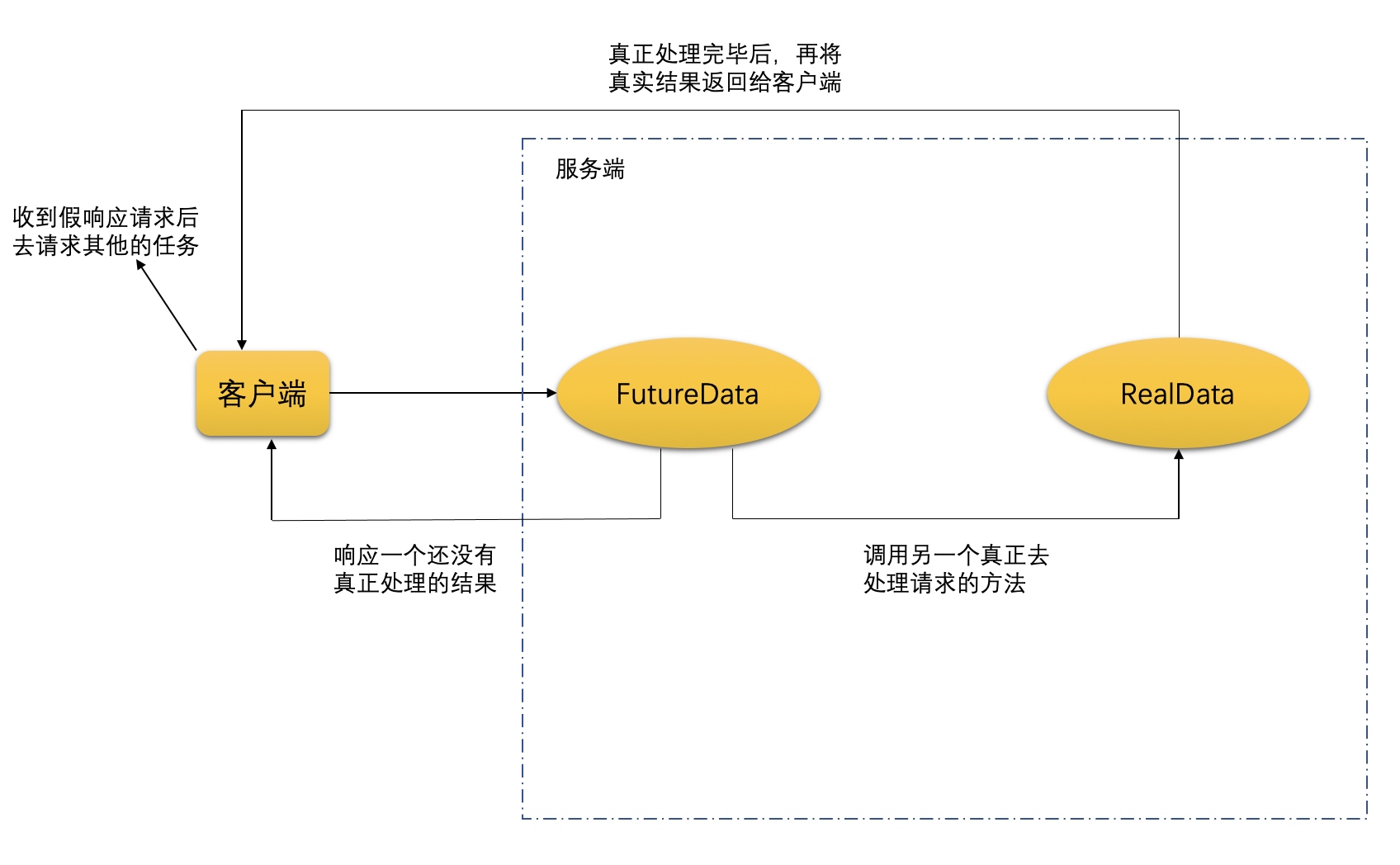
以上情景,在多线程之中就称之为“Future 模式”:当客户端(老板)向服务端(小王)发起一个请求时,服务端会立刻给客户端返回一个结果(“好的,没问题”),但实际上任务并没有开始执行。客户端在拿到“假的”响应结果的同时,服务端才会去真正执行任务,并在任务处理完毕后,将真正的结果再返回给客户端(“将整理好的文件送给了老板”)。Future 模式的处理流程如下图所示:
Callable
Callable 和 Runnable 类似,都是创建线程的上级接口。二者不同的是,在用 Runnable 方式创建线程时,需要重写 run()方法;而用 Callable 方式创建线程时,需要重写 call()方法。并且更重要的是:run()方法没有返回值,但 call()却有一个类型为泛型的返回值(即 call()的返回值可以是任意类型),而且可以通过 FutureTask 的 get()来接收此返回值。此外,get()方法也是一个闭锁式的阻塞式方法:该方法会一直等待,直到 call()方法执行完毕并且 return 返回值为止。最后注意,call()方法和 run()一样,也是通过 start()来调用的。
下面我们通过多线程求和的案例来加以展示:
我们在路径 src/ 下面新建 TestCallable.java 文件:
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class TestCallable {
public static void main(String[] args) {
//创建一个Callable类型的线程对象
MyCallableThread myThread = new MyCallableThread();
//将线程对象包装成FutureTask对象,并接收线程的返回值
FutureTask<Integer> result = new FutureTask<>(myThread);
//运行线程
new Thread(result).start();
//通过FutureTask的get()接收myThread的返回值
try {
Integer sum = result.get();//以闭锁的方式,获取线程的返回值
System.out.println(sum);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}
class MyCallableThread implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("线程运行中...计算1-100之和");
int sum = 0;
for (int i = 1; i <= 100; i++) {
sum += i;
}
return sum;
}
}
然后我们按照之前介绍的方法在终端中编译并运行上面的程序段得到的响应结果如下图所示:
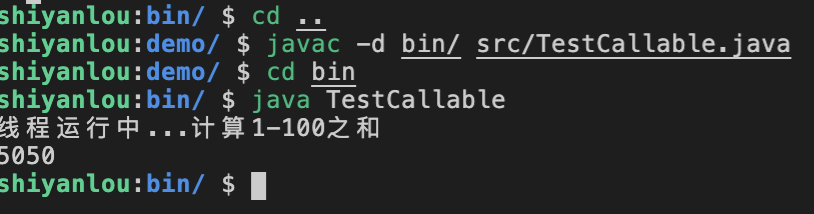
在代码中我们可以看到重写的方法 call 是带有一个 Integer 的返回值的。这也是和实现 Runnable 接口最主要的一个不同点所在。本次的实验内容就是上线介绍的这些,主要介绍了在 Java 中常用的并发编程类有哪些,希望大家在这些 demo 的模式中多总结,多去实际业务场景中使用并拓展。
本文由 liyunfei 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jul 22,2022