
分布式系统理论基础
一个分布式系统是一些独立的计算机集合,但是对这个系统的用户来说,系统就像一台计算机一样。
基础知识
分布式系统的主要特征
- 分布性
- 对等性: 没有主从之分, 即没有控制整个系统的主机, 也没有被控制的从机.
- 自治性
- 并发性
面临的问题
- 缺乏全局时钟
- 机器宕机
- 网络异常
- 分布式三态: 成功 , 失败, 超时(未知).
- 存储数据丢失.
衡量指标
- 性能: 这三个指标往往相互制约.
- 吞吐能力: 系统在某一时间可以处理的数据总量,通常可以用系统每秒处理的总的数据量来衡量
- 系统的并发能力,指系统可以同时完成某一功能的能力,通常也用QPS(query per second)来衡量
- 系统的响应延迟: 指系统完成某一功能需要使用的时间
- 可用性: 用系统停服务的时间与正常服务的时间的比例来衡量,也可以用某功能的失败次数与成功次数的比例来衡量
- 可拓展性: 过扩展集群机器规模提高系统性能(吞吐、延迟、并发)、存储容量、计算能力的特性。好的分布式系统总在追求“线性扩展性”,也就是使得系统的某一指标可以随着集群中的机器数量线性增长。
- 一致性
理论基础
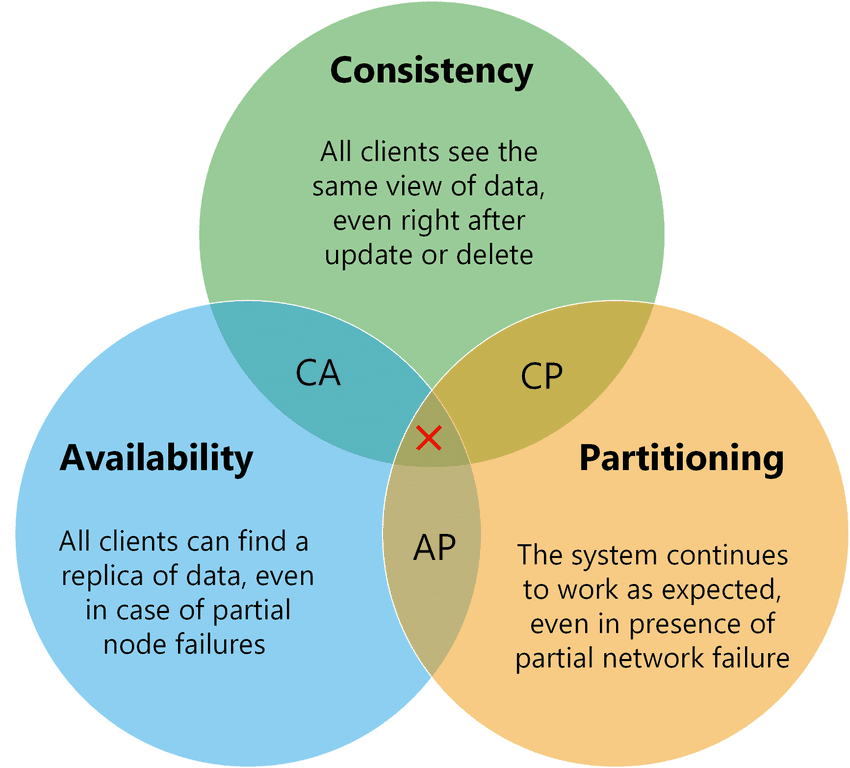
CAP理论
其中C代表一致性 (Consistency),A代表可用性 (Availability),P代表分区容错性 (Partition tolerance)。CAP理论告诉我们C、A、P三者不能同时满足,最多只能满足其中两个。
CAP三选二
- 一致性 (Consistency): 一个写操作返回成功,那么之后的读请求都必须读到这个新数据;如果返回失败,那么所有读操作都不能读到这个数据。所有节点访问同一份最新的数据。
- 可用性 (Availability): 对数据更新具备高可用性,请求能够及时处理,不会一直等待,即使出现节点失效。
- 分区容错性 (Partition tolerance): 能容忍网络分区,在网络断开的情况下,被分隔的节点仍能正常对外提供服务。
对CAP理论的理解
理解CAP理论最简单的方式是想象两个副本处于分区两侧,即两个副本之间的网络断开,不能通信。
- 如果允许其中一个副本更新,则会导致数据不一致,即丧失了C性质。
- 如果为了保证一致性,将分区某一侧的副本设置为不可用,那么又丧失了A性质。
- 除非两个副本可以互相通信,才能既保证C又保证A,这又会导致丧失P性质。
一般来说使用网络通信的分布式系统,无法舍弃P性质,那么就只能在一致性和可用性上做一个艰难的选择。
BASE理论
基本可用、软状态、最终一致性.
BASE 理论是对 CAP 理论的延伸,核心思想是即使无法做到强一致性(Strong Consistency,CAP 的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性(Eventual Consitency)。
一致性算法
- 一致性Hash算法
- Paxos算法
- Raft算法
- ZAB算法
全局唯一ID实现方案
介绍常见的分布式ID生成方式,大致分类的话可以分为两类:一种是类DB型的,根据设置不同起始值和步长来实现趋势递增,需要考虑服务的容错性和可用性; 另一种是类snowflake型,这种就是将64位划分为不同的段,每段代表不同的涵义,基本就是时间戳、机器ID和序列数。这种方案就是需要考虑时钟回拨的问题以及做一些 buffer的缓冲设计提高性能。
为什么需要
传统的单体架构的时候,我们基本是单库然后业务单表的结构。每个业务表的ID一般我们都是从1增,通过AUTO_INCREMENT=1设置自增起始值,但是在分布式服务架构模式下分库分表的设计,使得多个库或多个表存储相同的业务数据。这种情况根据数据库的自增ID就会产生相同ID的情况,不能保证主键的唯一性。
UUID
UUID (Universally Unique Identifier),通用唯一识别码的缩写。UUID是由一组32位数的16进制数字所构成,所以UUID理论上的总数为 1632=2128,约等于 3.4 x 10^38。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。
生成的UUID是由 8-4-4-4-12格式的数据组成,其中32个字符和4个连字符’ - ',一般我们使用的时候会将连字符删除 uuid.toString().replaceAll("-","")。
产生方式
- 基于时间的UUID: 般是通过当前时间,随机数,和本地Mac地址来计算出来. 由于使用了MAC地址,因此能够确保唯一性,但是同时也暴露了MAC地址,私密性不够好。
- DCE安全的UUID: 这个版本的UUID在实际中较少用到。
- 基于名字的UUID: 通过计算名字和名字空间的MD5散列值得到。相同名字空间中不同名字生成的UUID的唯一性;不同名字空间中的UUID的唯一性;相同名字空间中相同名字的UUID重复生成是相同的。
- 随机UUID: 根据随机数,或者伪随机数生成UUID。这种UUID产生重复的概率是可以计算出来的,但是重复的可能性可以忽略不计,因此该版本也是被经常使用的版本。JDK中使用的就是这个版本。
UUID缺点
- 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,暴露使用者的位置。
- 对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能,可以查阅 Mysql 索引原理 B+树的知识。
雪花算法
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割成多个部分,每个部分代表不同的含义。而 Java中64bit的整数是Long类型,所以在 Java 中 SnowFlake 算法生成的 ID 就是 long 来存储的。
- 第1位占用1bit,其值始终是0,可看做是符号位不使用。
- 第2位开始的41位是时间戳,41-bit位可表示2^41个数,每个数代表毫秒,那么雪花算法可用的时间年限是(1L<<41)/(1000L360024*365)=69 年的时间。
- 中间的10-bit位可表示机器数,即2^10 = 1024台机器,但是一般情况下我们不会部署这么台机器。如果我们对IDC(互联网数据中心)有需求,还可以将 10-bit 分 5-bit 给 IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,具体的划分可以根据自身需求定义。
- 最后12-bit位是自增序列,可表示2^12 = 4096个数。
这样的划分之后相当于在一毫秒一个数据中心的一台机器上可产生4096个有序的不重复的ID。但是我们 IDC 和机器数肯定不止一个,所以毫秒内能生成的有序ID数是翻倍的。
package com.jajian.demo.distribute;
/**
* Twitter_Snowflake<br>
* SnowFlake的结构如下(每部分用-分开):<br>
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br>
* 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0<br>
* 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)
* 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69<br>
* 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId<br>
* 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号<br>
* 加起来刚好64位,为一个Long型。<br>
* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。
*/
public class SnowflakeDistributeId {
// ==============================Fields===========================================
/**
* 开始时间截 (2015-01-01)
*/
private final long twepoch = 1420041600000L;
/**
* 机器id所占的位数
*/
private final long workerIdBits = 5L;
/**
* 数据标识id所占的位数
*/
private final long datacenterIdBits = 5L;
/**
* 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)
*/
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/**
* 支持的最大数据标识id,结果是31
*/
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/**
* 序列在id中占的位数
*/
private final long sequenceBits = 12L;
/**
* 机器ID向左移12位
*/
private final long workerIdShift = sequenceBits;
/**
* 数据标识id向左移17位(12+5)
*/
private final long datacenterIdShift = sequenceBits + workerIdBits;
/**
* 时间截向左移22位(5+5+12)
*/
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/**
* 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)
*/
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/**
* 工作机器ID(0~31)
*/
private long workerId;
/**
* 数据中心ID(0~31)
*/
private long datacenterId;
/**
* 毫秒内序列(0~4095)
*/
private long sequence = 0L;
/**
* 上次生成ID的时间截
*/
private long lastTimestamp = -1L;
//==============================Constructors=====================================
/**
* 构造函数
*
* @param workerId 工作ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public SnowflakeDistributeId(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
// ==============================Methods==========================================
/**
* 获得下一个ID (该方法是线程安全的)
*
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
*
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以毫秒为单位的当前时间
*
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
}
雪花算法提供了一个很好的设计思想,雪花算法生成的ID是趋势递增,不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的,而且可以根据自身业务特性分配bit位,非常灵活。
但是雪花算法强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。如果恰巧回退前生成过一些ID,而时间回退后,生成的ID就有可能重复。官方对于此并没有给出解决方案,而是简单的抛错处理,这样会造成在时间被追回之前的这段时间服务不可用。
美团Leaf
数据库方案
仍然依赖 DB的稳定性,需要采用主从备份的方式提高 DB的可用性,还有 Leaf-segment方案生成的ID是趋势递增的,这样ID号是可被计算的,例如订单ID生成场景,通过订单id号相减就能大致计算出公司一天的订单量,这个是不能忍受的。
snowflake方案
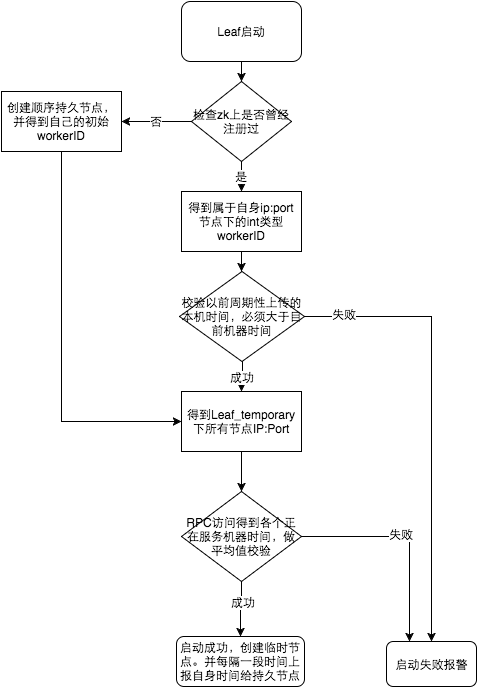
美团官方建议是由于强依赖时钟,对时间的要求比较敏感,在机器工作时NTP同步也会造成秒级别的回退,建议可以直接关闭NTP同步。要么在时钟回拨的时候直接不提供服务直接返回ERROR_CODE,等时钟追上即可。或者做一层重试,然后上报报警系统,更或者是发现有时钟回拨之后自动摘除本身节点并报警。
在性能上官方提供的数据目前 Leaf 的性能在4C8G 的机器上QPS能压测到近5w/s,TP999 1ms。
业务场景和要求
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一 ID 来标识一条数据或消息,数据库的自增 ID 显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一 ID 做标识。此时一个能够生成全局唯一ID 的系统是非常必要的。
要求
1、全局唯一性:不能出现重复的 ID 号,既然是唯一标识,这是最基本的要求;
2、趋势递增:在 MySQL InnoDB 引擎中使用的是聚集索引,由于多数 RDBMS 使用 B-tree 的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能;
3、单调递增:保证下一个 ID 一定大于上一个 ID,例如事务版本号、IM 增量消息、排序等特殊需求;
4、信息安全:如果 ID 是连续的,恶意用户的爬取工作就非常容易做了,直接按照顺序下载指定 URL 即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要 ID 无规则、不规则; 可以用“全局不重复,不可猜测且呈递增态势”这句话来概括描述要求。
分布式锁及实现方案
分布式锁的概念
- 线程锁: 主要用来给方法、代码块加锁。当某个方法或代码使用锁,在同一时刻仅有一个线程执行该方法或该代码段。线程锁只在同一JVM中有效果,因为线程锁的实现在根本上是依靠线程之间共享内存实现的,比如synchronized是共享对象头,显示锁Lock是共享某个变量(state)。
- 进程锁: 为了控制同一操作系统中多个进程访问某个共享资源,因为进程具有独立性,各个进程无法访问其他进程的资源,因此无法通过synchronized等线程锁实现进程锁。
- 分布式锁: 当多个进程不在同一个系统中(比如分布式系统中控制共享资源访问),用分布式锁控制多个进程对资源的访问。
分布式锁的设计原则
最小设计原则: 安全性和有效性.
Redis三个要求:
- 互斥(属于安全性): 在任何给定时刻,只有一个客户端可以持有锁。
- 无死锁(属于有效性): 即使锁定资源的客户端崩溃或被分区,也总是可以获得锁;通常通过超时机制实现。
- 容错性(属于有效性): 只要大多数 Redis 节点都启动,客户端就可以获取和释放锁。
除此之外, 还需要考虑: - 加锁解锁的同源性:A加的锁,不能被B解锁
- 获取锁是非阻塞的:如果获取不到锁,不能无限期等待;
- 高性能:加锁解锁是高性能的
常见的分布式锁的实现方式
基于数据库实现分布式锁
基于数据库表(锁表,很少使用)
乐观锁(基于版本号)
乐观锁机制往往基于系统中数据存储逻辑,因此也具备一定的局限性。由于乐观锁机制是在我们的系统中实现的,对于来自外部系统的用户数据更新操作不受我们系统的控制,因此可能会造成脏数据被更新到数据库中。在系统设计阶段,我们应该充分考虑到这些情况,并进行相应的调整(如将乐观锁策略在数据库存储过程中实现,对外只开放基于此存储过程的数据更新途径,而不是将数据库表直接对外公开)。
悲观锁(基于排它锁)
要使用悲观锁,我们必须关闭mysql数据库的自动提交属性,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。set autocommit=0;
基于Redis实现分布式锁
单个Redis实例:setnx(key,当前时间+过期时间) + Lua
文章链接
加锁: set NX PX + 重试 + 重试间隔
解锁:采用lua脚本
Redis集群模式:Redlock
假设有两个服务A、B都希望获得锁,有一个包含了5个redis master的Redis Cluster,执行过程大致如下:
- 客户端获取当前时间戳,单位: 毫秒
- 服务A轮寻每个master节点,尝试创建锁。(这里锁的过期时间比较短,一般就几十毫秒) RedLock算法会尝试在大多数节点上分别创建锁,假如节点总数为n,那么大多数节点指的是n/2+1。
- 客户端计算成功建立完锁的时间,如果建锁时间小于超时时间,就可以判定锁创建成功。如果锁创建失败,则依次(遍历master节点)删除锁。
- 只要有其它服务创建过分布式锁,那么当前服务就必须轮寻尝试获取锁。
基于Redis的客户端
这里Redis的客户端(Jedis, Redisson, Lettuce等)都是基于上述两类形式来实现分布式锁的,只是两类形式的封装以及一些优化(比如Redisson的watch dog)。
以基于Redisson实现分布式锁为例(支持了 单实例、Redis哨兵、redis cluster、redis master-slave等各种部署架构):
特色?
- redisson所有指令都通过lua脚本执行,保证了操作的原子性
- redisson设置了watchdog看门狗,“看门狗”的逻辑保证了没有死锁发生
- redisson支持Redlock的实现方式。
过程?
- 线程去获取锁,获取成功: 执行lua脚本,保存数据到redis数据库。
- 线程去获取锁,获取失败: 订阅了解锁消息,然后再尝试获取锁,获取成功后,执行lua脚本,保存数据到redis数据库。
互斥?
如果这个时候客户端B来尝试加锁,执行了同样的一段lua脚本。第一个if判断会执行“exists myLock”,发现myLock这个锁key已经存在。接着第二个if判断,判断myLock锁key的hash数据结构中,是否包含客户端B的ID,但明显没有,那么客户端B会获取到pttl myLock返回的一个数字,代表myLock这个锁key的剩余生存时间。此时客户端B会进入一个while循环,不听的尝试加锁。
watch dog自动延时机制?
客户端A加锁的锁key默认生存时间只有30秒,如果超过了30秒,客户端A还想一直持有这把锁,怎么办?其实只要客户端A一旦加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果客户端A还持有锁key,那么就会不断的延长锁key的生存时间。
可重入?
每次lock会调用incrby,每次unlock会减一
分布式事务及实现方案
事务是一个程序执行单元,里面的所有操作要么全部执行成功,要么全部执行失败。而分布式事务是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。
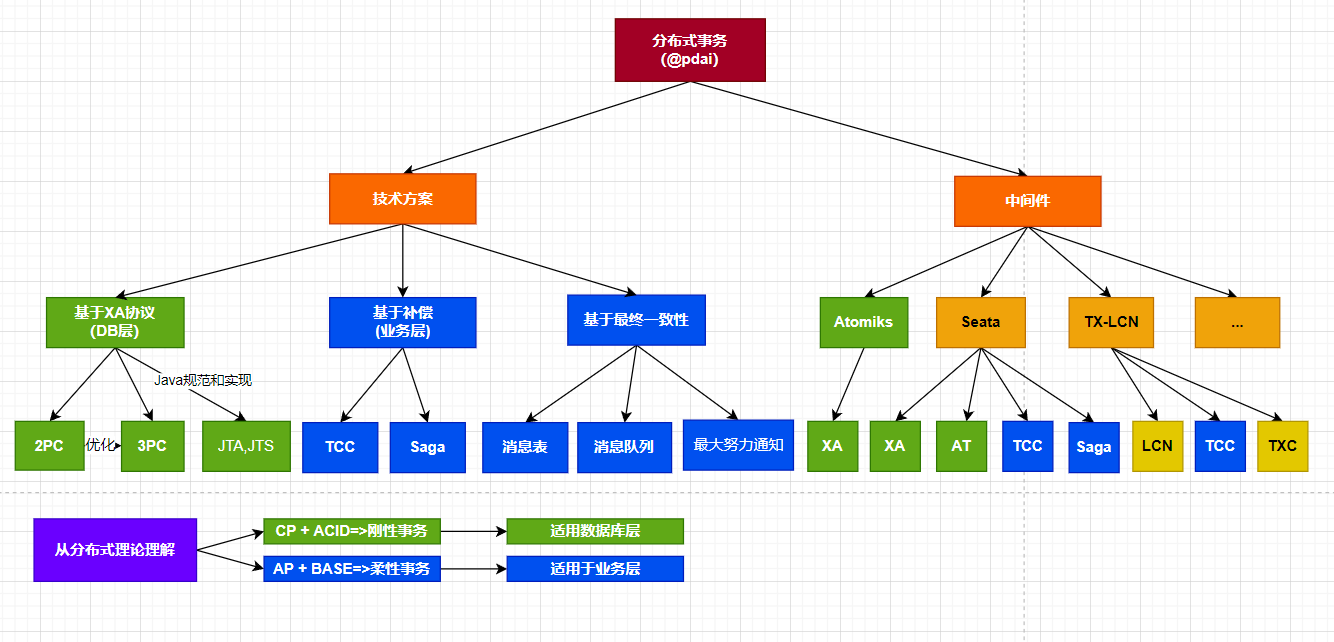
柔性事务
- 基于业务层
- TCC: TCC(Try-Confirm-Cancel)又被称补偿事务,TCC与2PC(两次提交)的思想很相似,事务处理流程也很相似,但2PC是应用于在DB层面,TCC则可以理解为在应用层面的2PC,是需要我们编写业务逻辑来实现。—TCC它的核心思想是:“针对每个操作都要注册一个与其对应的确认(Try)和补偿(Cancel)”。
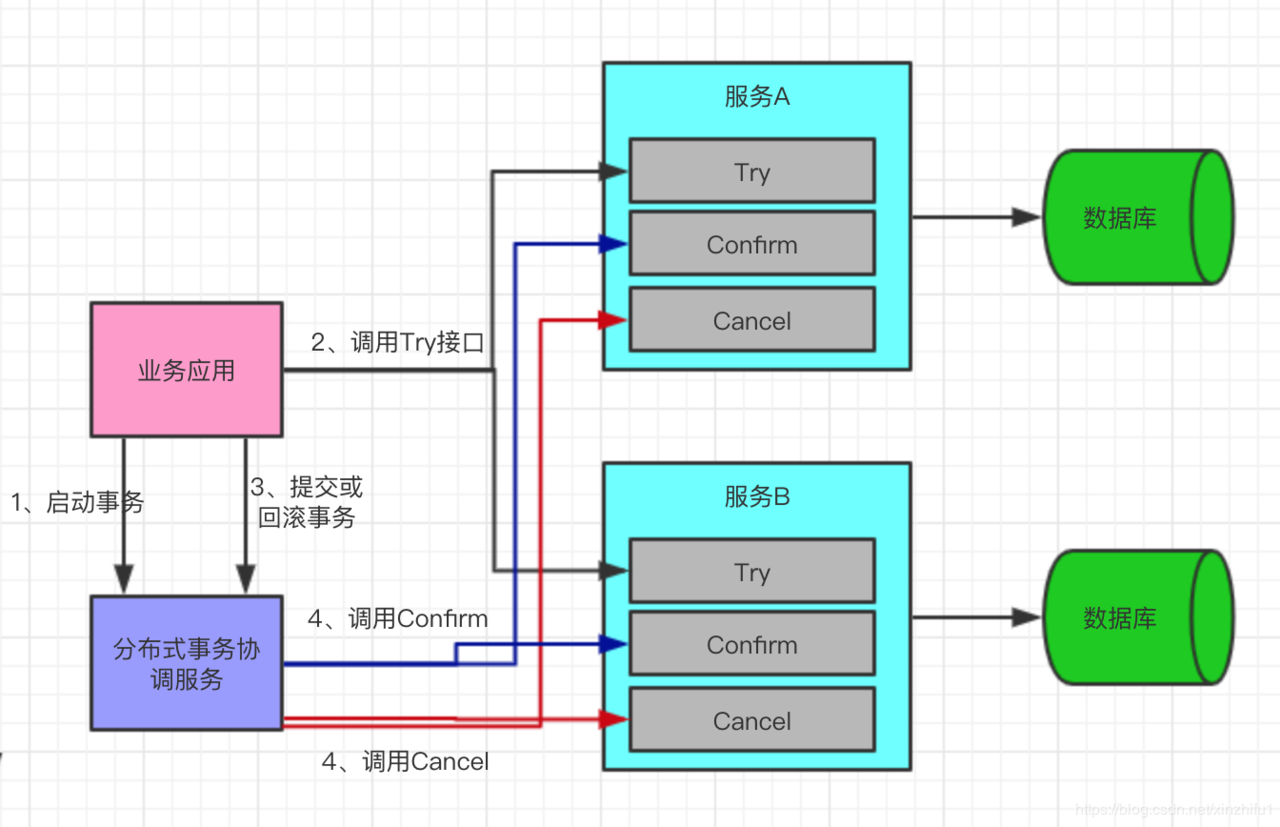
问题: 空回滚—全局事务ID和分支事务ID存入分支事务表, 幂等问题—分支事务表中增加事务执行状态, 悬挂问题. - SAGA:Saga是由一系列的本地事务构成。每一个本地事务在更新完数据库之后,会发布一条消息或者一个事件来触发Saga中的下一个本地事务的执行。如果一个本地事务因为某些业务规则无法满足而失败,Saga会执行在这个失败的事务之前成功提交的所有事务的补偿操作。Saga的实现有很多种方式,其中最流行的两种方式是:基于事件的方式和基于命令的方式。
- 最终一致性
- 消息表:本地消息表的方案最初是由 eBay 提出,核心思路是将分布式事务拆分成本地事务进行处理。
- 消息队列:基于 MQ 的分布式事务方案其实是对本地消息表的封装,将本地消息表基于 MQ 内部,其他方面的协议基本与本地消息表一致。
- 最大努力通知:最大努力通知也称为定期校对,是对MQ事务方案的进一步优化。它在事务主动方增加了消息校对的接口,如果事务被动方没有接收到消息,此时可以调用事务主动方提供的消息校对的接口主动获取。
分布式缓存及实现方案
指的是与应用分离的缓存组件或服务,其最大的优点是自身就是一个独立的应用,与本地应用隔离,多个应用可直接的共享缓存。
Redis缓存
Redis使用场景
- 在主页中显示最新的项目列表.
- 删除和过滤.
- 排行榜及相关问题.
- 按照用户投票和时间排序.
- 过期项目处理.
- 计数.
- 特定时间内的特定项目.
分布式缓存的实现技术–Redis
- 持久化: RDB和AOF机制.
- 消息传递: 发布订阅模式.
- 事务: 事件机制和事务.
- 高可用: 主从复制, 哨兵机制.
- 高可拓展: 分片技术.
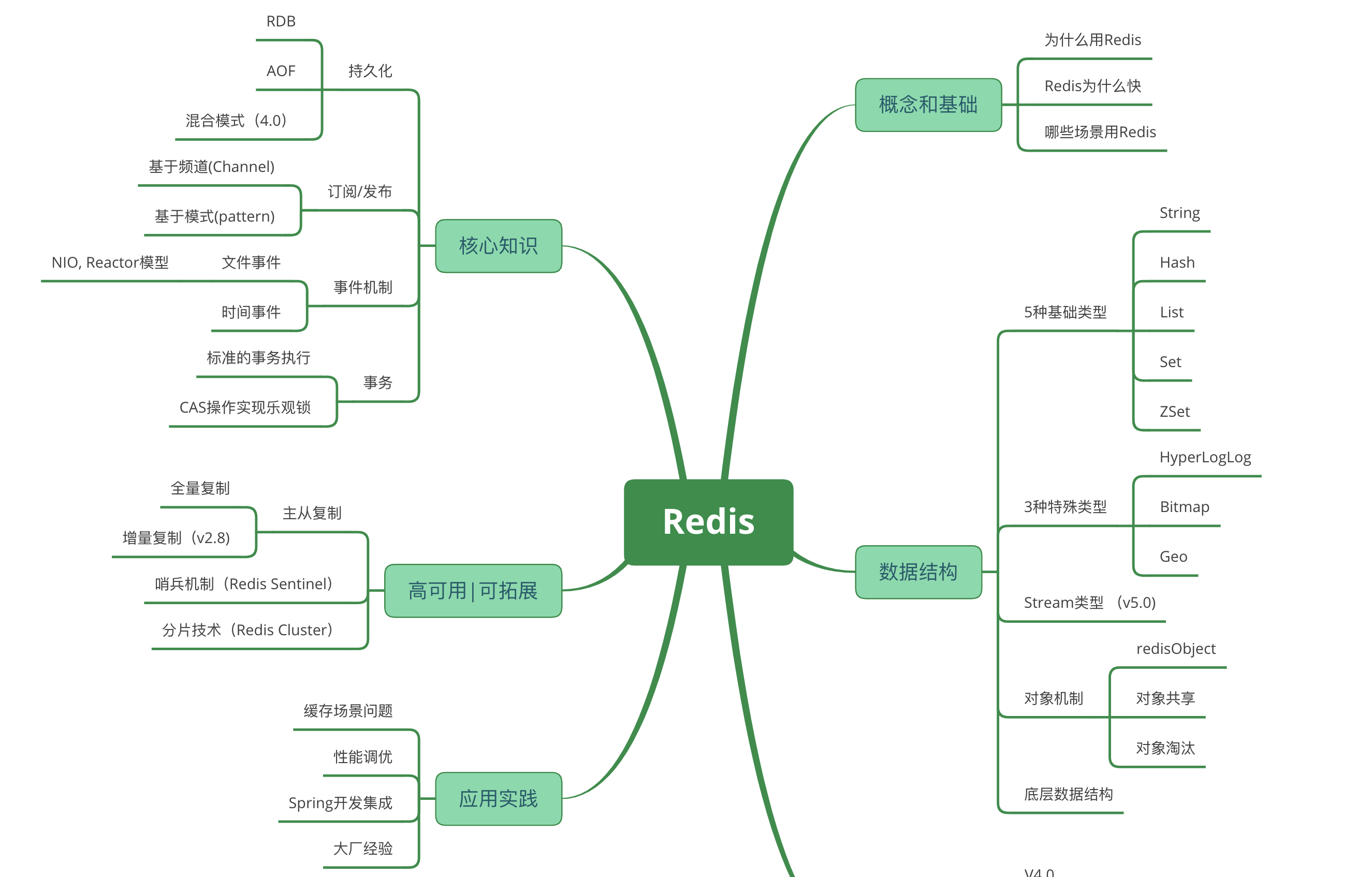
Redis知识体系
分布式缓存常见问题和解决方案
- 缓存穿透
- 缓存击穿
- 缓存雪崩
- 缓存污染
- 最大缓存设置多大
- 缓存淘汰策略
- 数据库和缓存一致性问题
- 4种相关模式
- Cache aside
- Read through
- Write through
- Write behind caching
- 方案: 队列+重试机制
- 方案: 异步更新缓存(基于订阅binlog的同步机制)
分布式任务及实现方案
介绍定时任务的基础和单体方式下定时任务方案的演化,以及常见的分布式任务方案(包括Quartz Cluster,ElasticJob,xxl-job等)和技术实现要点。
介绍
定时任务应用场景
比如每天/每周/每月生成日志汇总,定时发送推送信息,定时生成数据表格等
定时任务的基础
Cron表达式是定时任务的基础。Cron表达式是一个字符串,字符串以5或6个空格隔开,分为6或7个域,每一个域代表一个含义.
单体应用定时任务演化
- cron+脚本定时任务
- JDK内置之Timer: 很少用, Timer底层是使用一个单线来实现多个Timer任务处理的,所有任务都是由同一个线程来调度,所有任务都是串行执行,意味着同一时间只能有一个任务得到执行,而前一个任务的延迟或者异常会影响到之后的任务。
- JDK内置之ScheduleExecutorService, 基于线程池.
- Netty之HashedWheelTimer: 利用时间轮(在Linux内核中使用广泛,是Linux内核定时器的实现方法和基础之一). 在Netty中的一个典型应用场景是判断某个连接是否idle,如果idle(如客户端由于网络原因导致到服务器的心跳无法送达),则服务器会主动断开连接,释放资源。之所以采用时间轮(Timing Wheel)的结构还有一个很重要的原因是I/O超时这种类型的任务对时效性不需要非常精准。
- Spring Tasks
- Quartz: Quartz可以用来创建简单或为运行十个,百个,甚至是好几万个Jobs这样复杂的程序。Jobs可以做成标准的Java组件或 EJBs。
方案
常见的分布式任务的方案有:Quartz Cluster,XXL-Job,Elastic-Job等。综合代码质量,License, 维护方,拓展性等,选择的建议:
- 如果仅是小团队内部自用,可以采用XXL-Job
- 如果是稍大一点的团队,建议使用ElasticJob或者基于ElasticJob进行二次开发
- 如果是团队具备自研能力,可以参考后续的章节(分布式任务的技术要点)设计和自研
分布式会话及实现方案
无状态的token或者有状态的Session集中管理是目前最为常用的方案,主要讨论的有状态的分布式Session会话, 包括Session Stick, Session Replication, Session 数据集中存储, Cookie Based 以及Token方式等。
基础概念
为什么要产生Session
http协议本身是无状态的,客户端只需要向服务器请求下载内容,客户端和服务器都不记录彼此的历史信息,每一次请求都是独立的。
为什么是无状态的呢?因为浏览器与服务器是使用socke套接字进行通信,服务器将请求结果返回给浏览器之后,会关闭当前的socket链接,而且服务器也会在处理页面完毕之后销毁页面对象。
然而在Web应用的很多场景下需要维护用户状态才能正常工作(是否登录等),或者说提供便捷(记住密码,浏览历史等),状态的保持就是一个很重要的功能。因此在web应用开发里就出现了保持http链接状态的技术:一个是cookie技术,另一种是session技术。
会话技术的发展
- 单机: Session+Cookie
- 多机器: Session粘滞; Session数据同步
- 多机器, 集群: session集中管理,比如redis;目前方案上用的最多的是SpringSession.
- 无状态token, 比如JWT.
方案
Session Stick
为什么这种方案到目前还有很多项目使用呢?因为不需要在项目代码侧改动,而是只需要在负载均衡侧改动。
方案即将客户端的每次请求都转发至同一台服务器,这就需要负载均衡器能够根据每次请求的会话标识(SessionId)来进行请求转发,如下图所示。
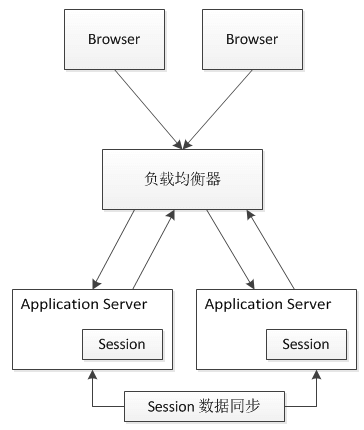
这种方案实现比较简单,对于Web服务器来说和单机的情况一样。但是可能会带来如下问题:
- 如果有一台服务器宕机或者重启,那么这台机器上的会话数据会全部丢失。
- 会话标识是应用层信息,那么负载均衡要将同一个会话的请求都保存到同一个Web服务器上的话,就需要进行应用层(第7层)的解析,这个开销比第4层大。
- 负载均衡器将变成一个有状态的节点,要将会话保存到具体Web服务器的映射。和无状态节点相比,内存消耗更大,容灾方面也会更麻烦。
Session数据集中存储
Session 数据集中存储方案则是将集群中的所有Session集中存储起来,Web服务器本身则并不存储Session数据,不同的Web服务器从同样的地方来获取Session,如下图所示。
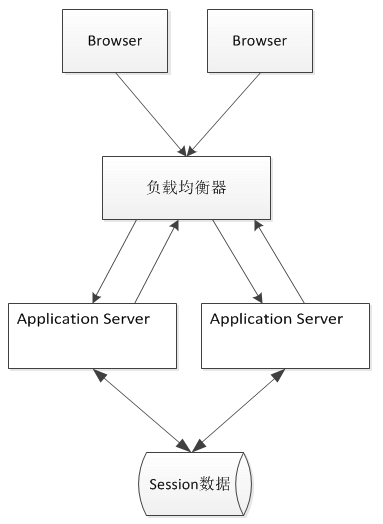
相对于Session Replication方案,此方案的Session数据将不保存在本机,并且Web服务器之间也没有了Session数据的复制,但是该方案存在的问题在于:
- 读写Session数据引入了网络操作,这相对于本机的数据读取来说,问题就在于存在时延和不稳定性,但是通信发生在内网,则问题不大。
- 如果集中存储Session的机器或集群出现问题,则会影响应用。
Cookie Based
Cookie Based 方案是将Session数据放在Cookie里,访问Web服务器的时候,再由Web服务器生成对应的Session数据,如下图所示。
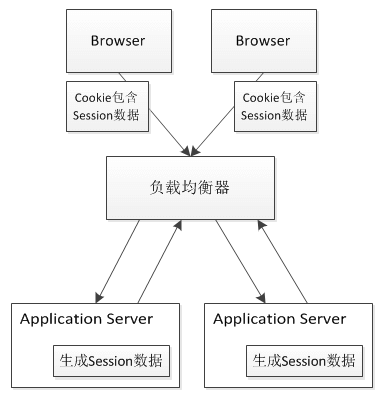
但是Cookie Based 方案依然存在不足:
- Cookie长度的限制。这会导致Session长度的限制。
- 安全性。Seesion数据本来是服务端数据,却被保存在了客户端,即使可以加密,但是依然存在不安全性。
- 带宽消耗。这里不是指内部Web服务器之间的宽带消耗,而是数据中心的整体外部带宽的消耗。
- 性能影响。每次HTTP请求和响应都带有Seesion数据,对Web服务器来说,在同样的处理情况下,响应的结果输出越少,支持的并发就会越高。
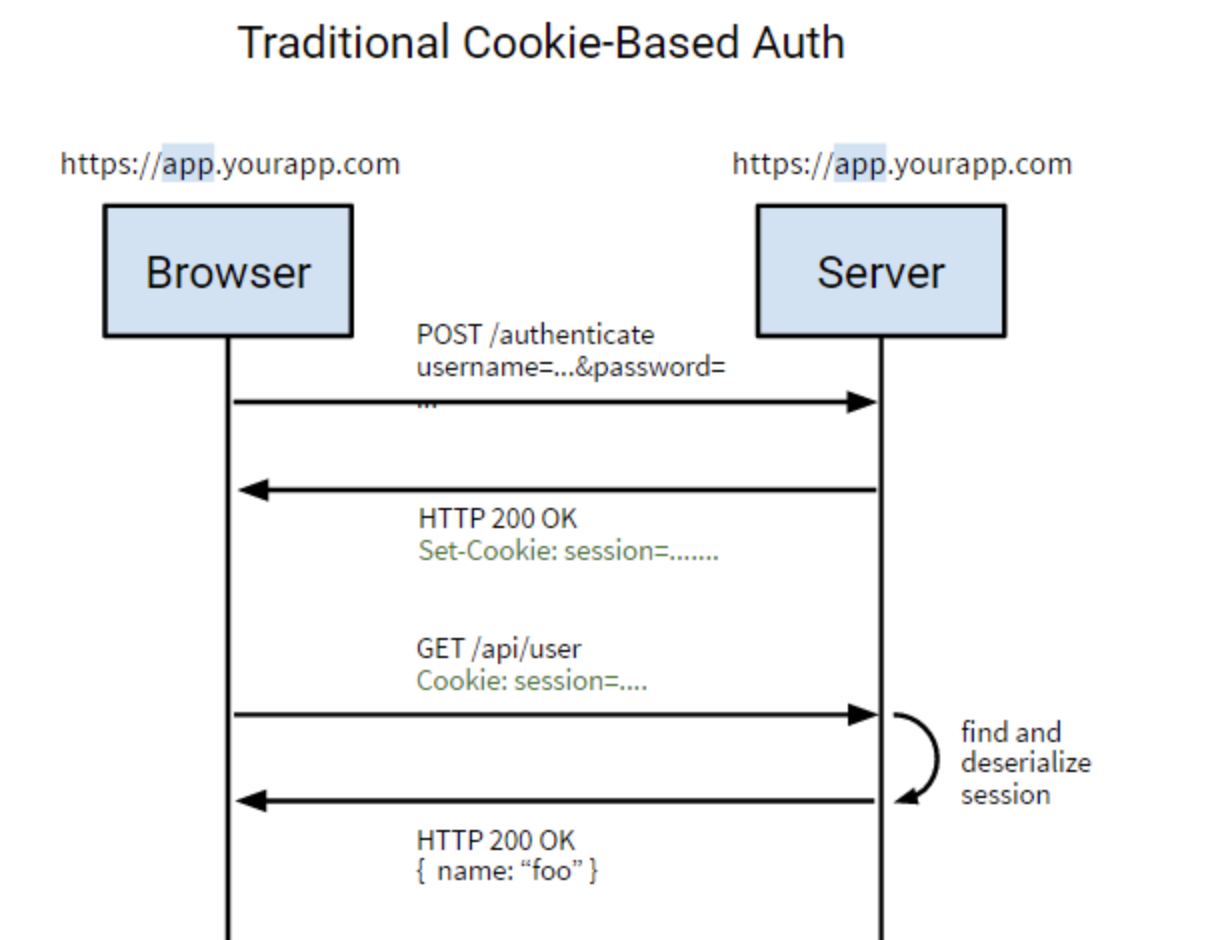
Token
JSON Web Token,一般用它来替换掉Session实现数据共享。 使用基于 Token 的身份验证方法,在服务端不需要存储用户的登录记录。大概的流程是这样的:
1、客户端通过用户名和密码登录服务器;
2、服务端对客户端身份进行验证;
3、服务端对该用户生成Token,返回给客户端;
4、客户端将Token保存到本地浏览器,一般保存到cookie中;
5、客户端发起请求,需要携带该Token;
6、服务端收到请求后,首先验证Token,之后返回数据。
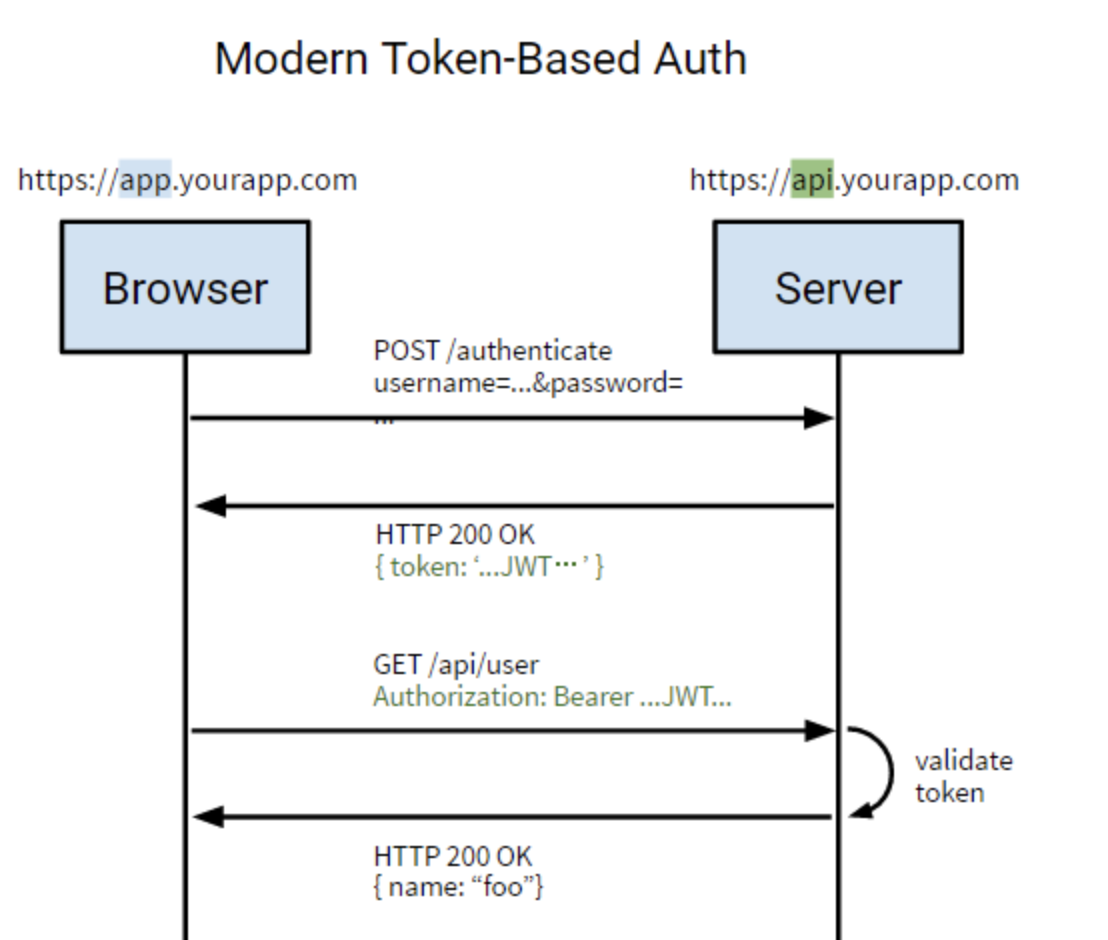
如上图为Token实现方式,浏览器第一次访问服务器,根据传过来的唯一标识userId,服务端会通过一些算法,如常用的HMAC-SHA256算法,然后加一个密钥,生成一个token,然后通过BASE64编码一下之后将这个token发送给客户端;客户端将token保存起来,下次请求时,带着token,服务器收到请求后,然后会用相同的算法和密钥去验证token,如果通过,执行业务操作,不通过,返回不通过信息。
优点:
- 无状态、可扩展 :在客户端存储的Token是无状态的,并且能够被扩展。基于这种无状态和不存储Session信息,负载均衡器能够将用户信息从一个服务传到其他服务器上。
- 安全:请求中发送token而不再是发送cookie能够防止CSRF(跨站请求伪造)。
- 可提供接口给第三方服务:使用token时,可以提供可选的权限给第三方应用程序。
- 多平台跨域
对应用程序和服务进行扩展的时候,需要介入各种各种的设备和应用程序。 假如我们的后端api服务器a.com只提供数据,而静态资源则存放在cdn 服务器b.com上。当我们从a.com请求b.com下面的资源时,由于触发浏览器的同源策略限制而被阻止。
我们通过CORS(跨域资源共享)标准和token来解决资源共享和安全问题。
// 第一行指定了允许访问该资源的外域 URI。
Access-Control-Allow-Origin: http://a.com
// 第二行指明了实际请求中允许携带的首部字段,这里加入了Authorization,用来存放token。
Access-Control-Allow-Headers: Authorization, X-Requested-With, Content-Type, Accept
// 第三行用于预检请求的响应。其指明了实际请求所允许使用的 HTTP 方法。
Access-Control-Allow-Methods: GET, POST, PUT,DELETE
// 然后用户从a.com携带有一个通过了验证的token访问B域名,数据和资源就能够在任何域上被请求到。
分布式服务链路追踪
注意
- 网络并不可靠. 您是否正在与第三方系统(支付网关,会计系统,CRM)集成?你在做网络服务电话吗?如果呼叫失败会发生什么?如果您要查询数据,则可以进行简单的重试。但是如果您发送命令会发生什么?
- 延迟并不为0. 带回可能需要的所有数据; 将DataCloser移动到客户端; 反转数据流.
- 带宽是有限的.
- 网络并不安全.
- 网络拓扑不断变化.
- 没有一个人知道一切.
- 运输成本不是0. 网络基础设施需要成本, 序列化/反序列化需要成本.著作权归https://pdai.tech所有。只能确保尽可能高效地使用它。SOAP或XML比JSON更昂贵。JSON比像Google的Protocol Buffers这样的二进制协议更昂贵。根据系统的类型,这可能或多或少重要。例如,对于与视频流或VoIP有关的应用,传输成本更为重要。
- 网络不是同质的. 您应该选择标准格式以避免供应商锁定。这可能意味着XML,JSON或协议缓冲区。有很多选择可供选择。
本文由 liyunfei 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jul 20,2022