
Flink环境准备
开发工具及环境要求
首先我们需要在环境中搭建 Flink 运行环境,总共可以分为下面这几步:
- 安装 jdk 并配置环境变量
- 安装 scala 并配置环境变量
- 安装 maven 并修改中心仓库为阿里云地址
- 安装 IDEA 开发工具
IDE最好使用IntelliJ IDEA (eclipse存在插件不兼容的风险)
唯一的要求是使用 Maven3.0.4 和安装 Java 8.x(或更高版本)。
Maven依赖坐标
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>1.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
Flink入门程序
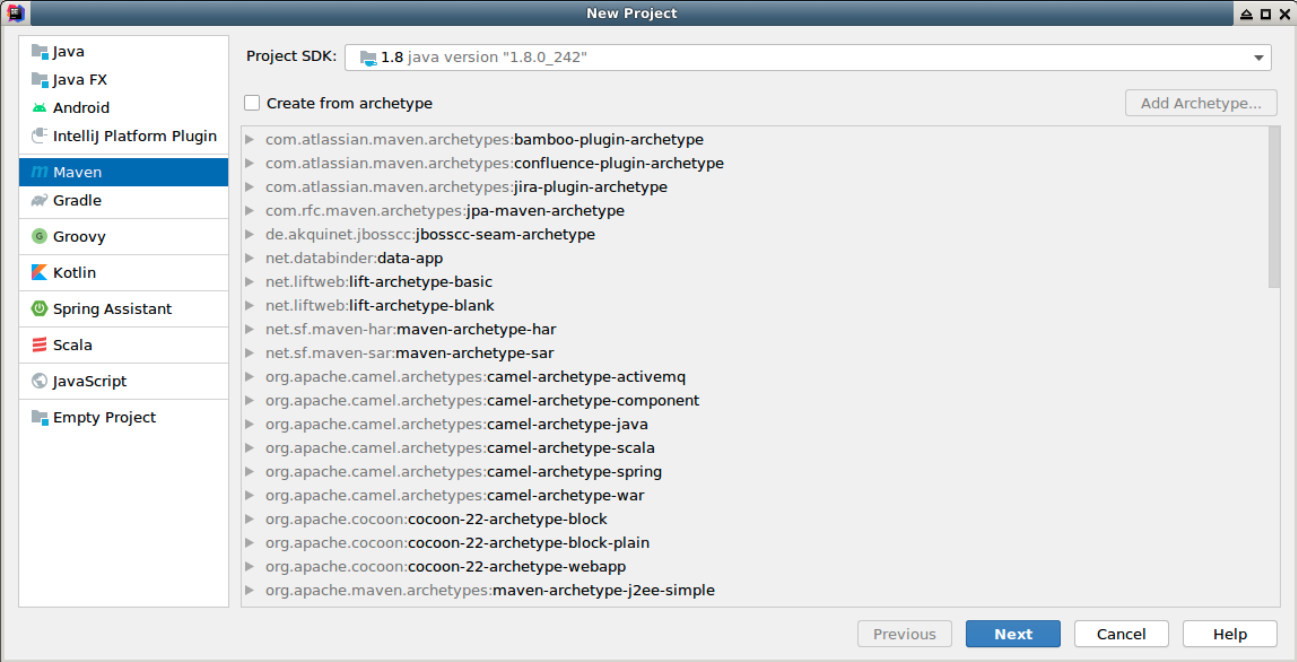
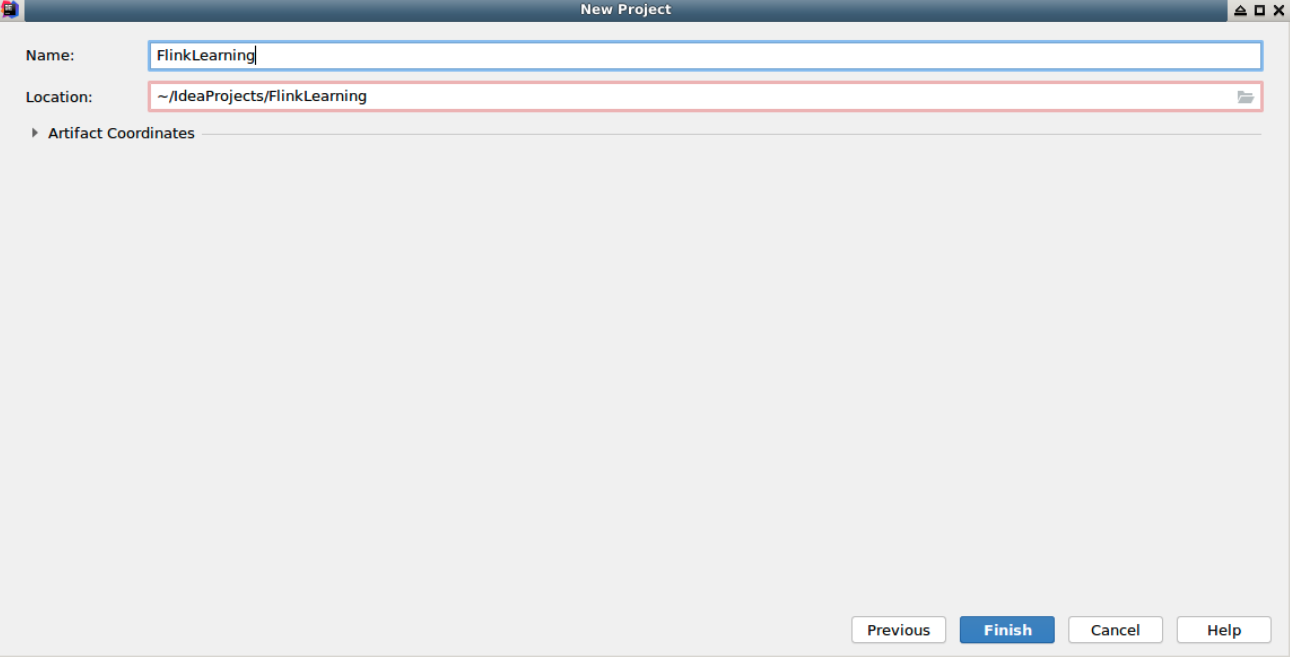
双击桌面的 IDEA 程序,启动之后,点击 File -> New -> Project 创建一个新的 Maven 工程 FlinkLearning:
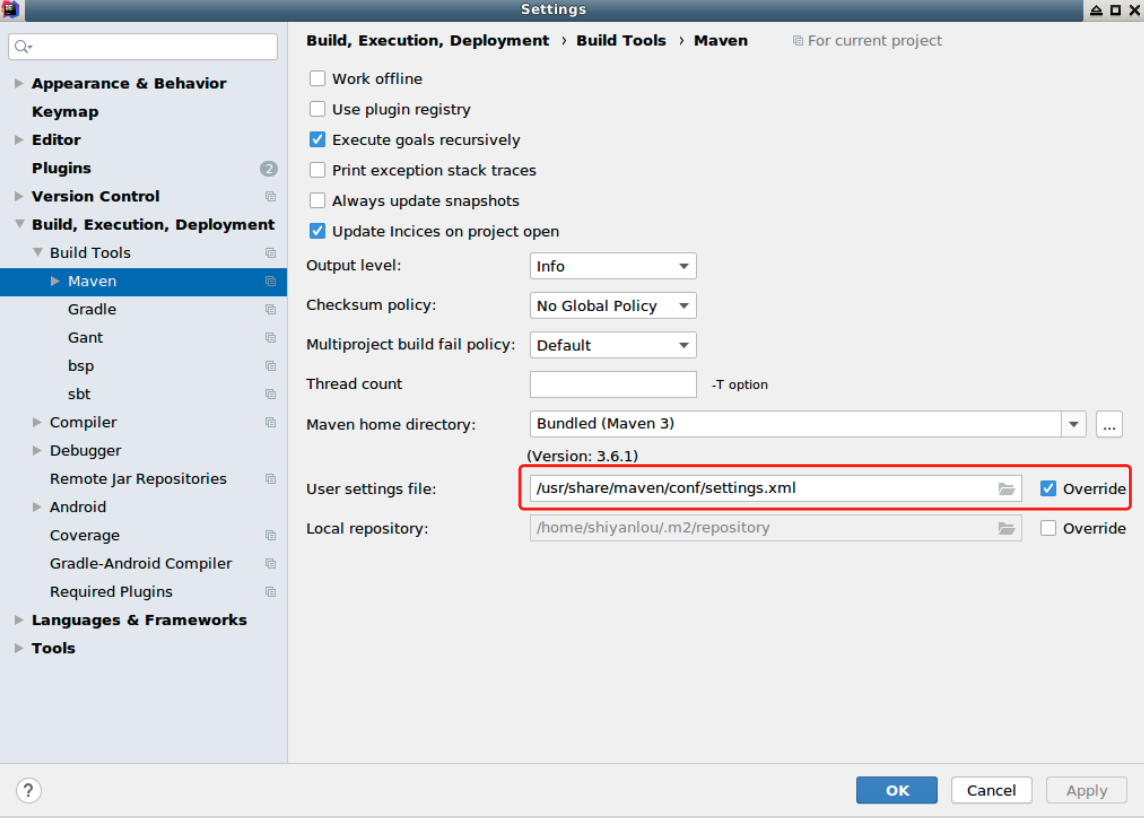
创建好之后点击左上角 File > Settings 中,将 Maven 的配置文件修改为 /usr/share/maven/conf/settings.xml,配置之后的 Maven 中心仓库为阿里云,加载依赖会快很多:
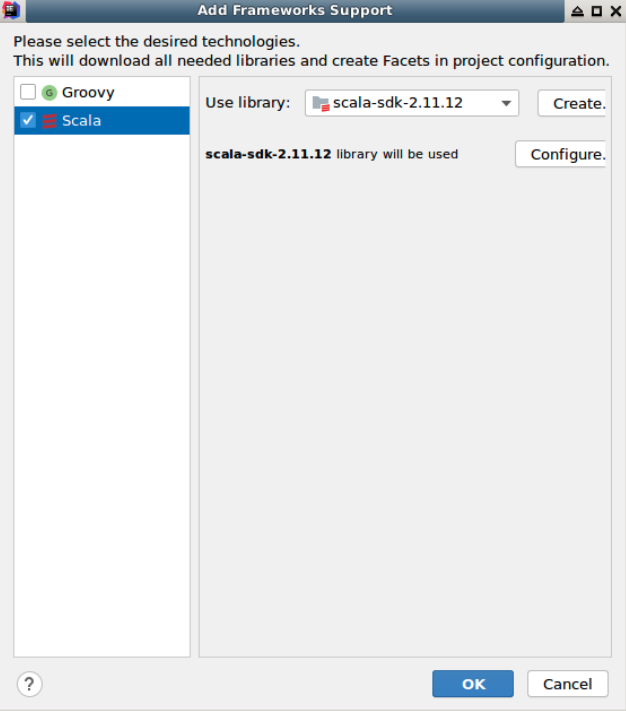
接下来在工程的总目录 FlinkLearning 右键点击 Add Framework Support,为工程勾选添加 Scala 支持:
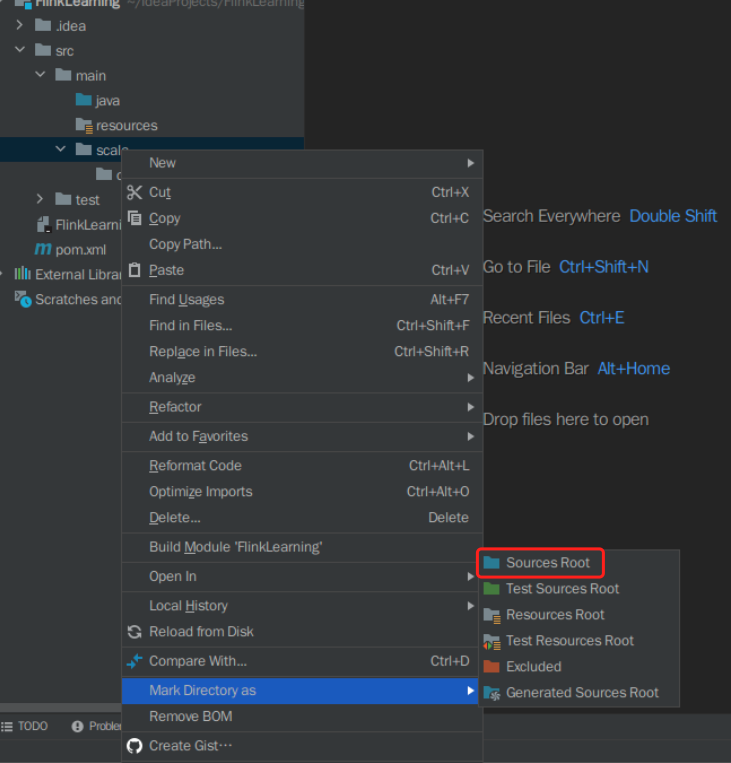
在工程 src/main 目录中创建 scala 文件夹,然后右键,选择 Mark Directory as,并将其标记为 Sources Root。
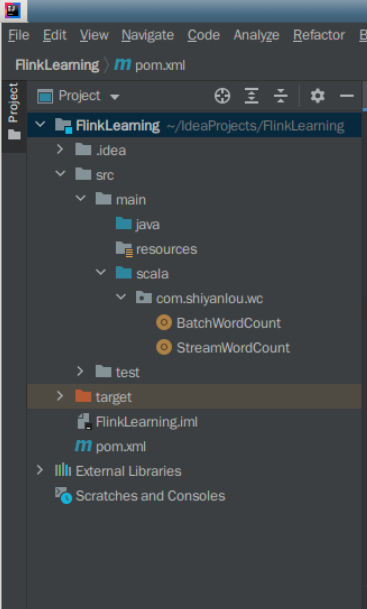
在 scala 目录里创建 com.shiyanlou.wc 包,并分别创建 BatchWordCount 和 StreamWordCount 两个 Scala Object,分别代表 Flink 批处理和 Flink 流处理。
至此,我们的准备工作已经完成,接下来正式进入编码阶段。
Flink批处理
package cn.tedu.flinktest;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWC {
public static void main(String[] args) throws Exception {
//1.获取执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//2.读取源文件
DataSource<String> textFile = env.readTextFile("E:\\words.txt");
//3.读取当前行,并进行切割
textFile.flatMap(new FlatMapFunction<String, Tuple2<String,Integer>>() {
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] values = s.toLowerCase().split(" ");
for (String value: values){
if (value.length()>0){
collector.collect(new Tuple2<String, Integer>(value,1));
}
}
}
})
//4.分组
.groupBy(0)
//5.求和
.sum(1)
//6.打印(sink)
.print();
}
}
Flink流式处理
package cn.tedu.flinktest;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class StreamWC {
public static void main(String[] args) throws Exception {
//1.从args中获取端口等参数
int port = 0;
try{
ParameterTool tool = ParameterTool.fromArgs(args);
port = tool.getInt("port");
}catch(Exception e){
System.err.println("未定义端口,使用默认9999");
port = 9999;
}
//2.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//3.获取数据源
DataStreamSource<String> source = env.socketTextStream("localhost", port);
//4.对每行数据进行切割
source.flatMap(new FlatMapFunction<String, Tuple2<String,Integer>>() {
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] values = s.toLowerCase().split(" ");
for (String value: values){
if (value.length()>0){
collector.collect(new Tuple2<String, Integer>(value,1));
}
}
}
})
//5.分组
.keyBy(0)
//6.定时刷新结果
.timeWindow(Time.seconds(5))
//7.求和
.sum(1)
//8.打印(sink)
.print()
//9.设置并行数
.setParallelism(1);
//10.提交作业
env.execute("StreamWC");
}
}
总结开发过程
Flink程序不管是批处理还是流式数据处理看起来都像转换数据集合的常规程序。每个程序都包含相同的基本部分:
获得execution environment
有三种方式:
getExecutionEnvironment()
createLocalEnvironment()
createRemoteEnvironment(String host, int port, String... jarFiles) //(不常用)
加载/创建初始数据source
批处理:DataStream
流式处理: DataStreamSource
等等(详见source章节)
指定对此数据的转换transformation
根据业务需求编写处理逻辑。此部分为后续重点讲解内容。
指定将计算结果放在何处sink
writeAsText(String path)
print()
触发程序执行execute
Flink不会直接将部分代码逐行执行,而是采用懒加载方式,只有最终调用execute()方法时才会执行相关作业,这样能够保证flink可以胜任更加复杂的应用程序。
env.execute()
本文由 liyunfei 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jun 24,2022