
概念
Hadoop是什么
Apache基金会开发的分布式系统基础架构.
主要解决海量数据的存储和海量数据的分析计算问题.
Hadoop发展历史
在Lucene框架基础上进行优化升级.
Hadoop的三大发行版本
- Apache版本—最原始(最基础)的版本
- cloudera内部集成了很多大数据框架, 对应产品CDH;
- Hortonworks文档较好, 对应产品HDP. 现在已经被Cloudera公司收购, 推出新的品牌CDP.
Hadoop的优势
- 高可靠性: Hadoop底层维护多个数据副本, 所以即使Hadoop某个计算元素或存储出现故障, 也不会导致数据的丢失.
- 高拓展性: 在集群间分配任务数据, 可方便的拓展数以千计的节点.
- 高效性: 在MapReduce的思想下, Hadoop是并行工作的, 以加快任务处理速度.
- 高容错性: 能够自动将失败的任务重新分配.
Hadoop的组成
Hadoop1.X组成
- Common(辅助工具)
- HDFS(数据存储)
- MapReduce(计算+ 资源调度)
Hadoop2.X组成
- Common(辅助工具)
- HDFS(数据存储)
- MapReduce(计算)
- Yarn(资源调度)
Hadoop3.X
在组成上和Hadoop2.X没有区别
HDFS架构概述
分布式文件系统
- NameNode: 数据存储在什么位置
nn: 存储文件的元数据, 如文件名, 文件目录结构, 文件属性(生成时间, 副本数, 文件权限), 以及每个文件的块列表和块所在的DataNode等. - DataNode: 具体存储数据
在本地文件系统存储文件块数据, 以及块数据的校验和. - 2NN: 秘书
SecondNameNode: 每隔一段时间对NameNode元数据备份.
Yarn架构概述
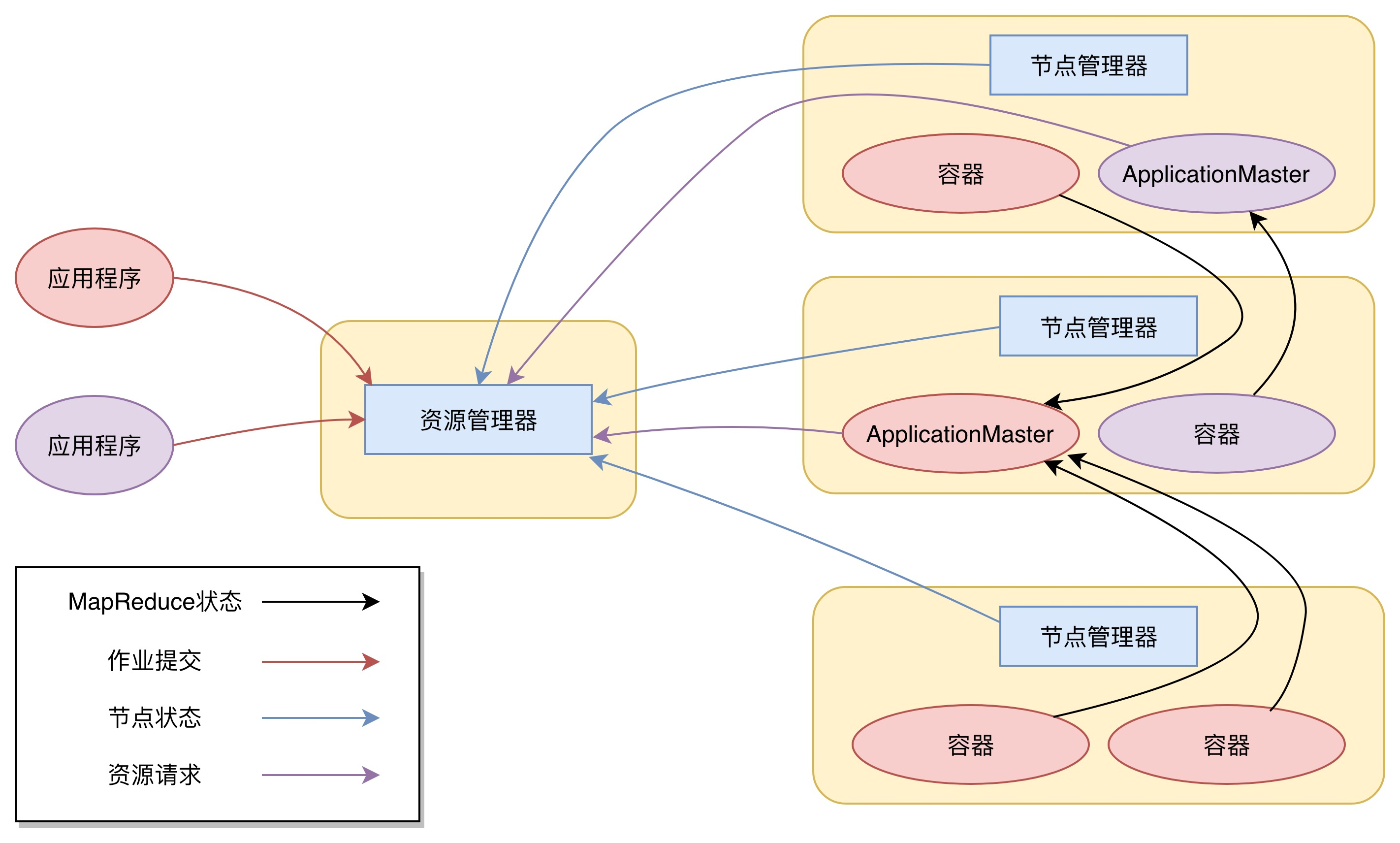
-
ResourceManager(RM): 整个集群资源(内存, CPU等)的老大
-
NodeManager(NM): 单个节点服务器资源老大
-
ApplicationMaster(AM): 单个任务运行的老大
-
Container:容器, 相当于一台独立的服务器, 里面封装了任务所需要的资源, 如内存, CPU, 磁盘, 网络等.
说明1: 客户端可以有多个
说明2: 集群上可以运行多个ApplicationMaster
说明3: 每个NodeManager上可以有多个Container
MapReduce架构概述
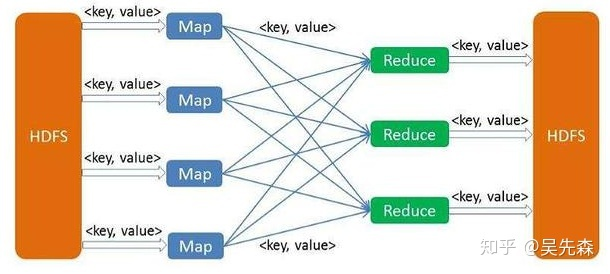
将计算过程分为两个阶段: Map和Reduce
- Map阶段并行处理数据
- Reduce阶段对Map结果进行汇总
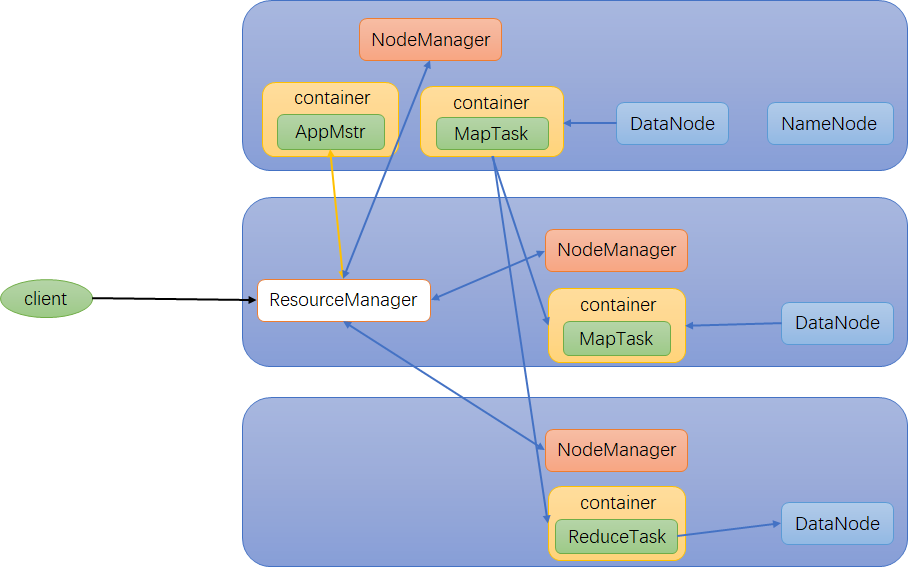
三者之间关系
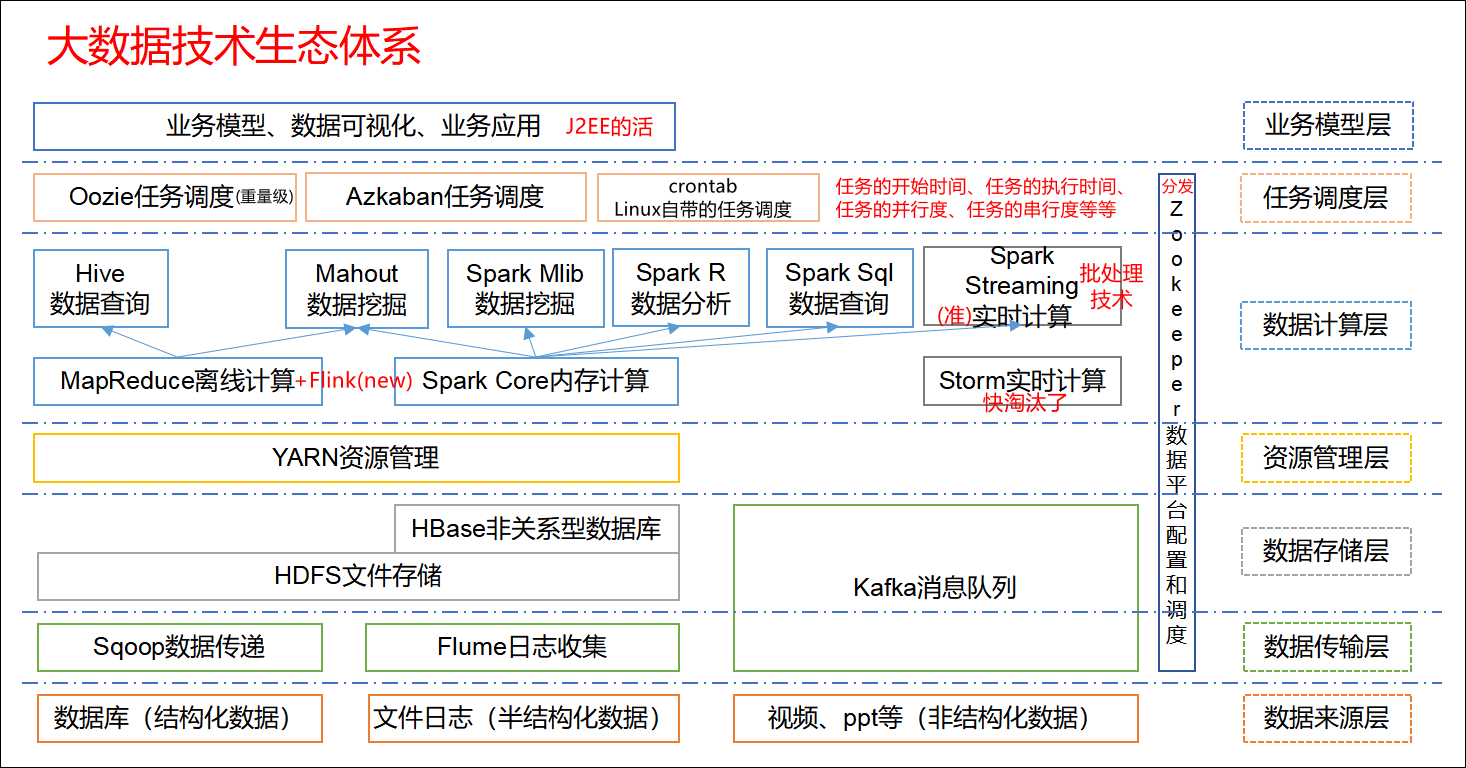
大数据技术生态体系
环境准备
模板虚拟机的准备
配置ip地址:
- vmware
克隆
安装JDK和Hadoop
Hadoop生产集群搭建
本地模式
完全分布式集群—开发和面试的重点
常见错误的解决方案
本文由 liyunfei 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jun 24,2022