
1 Python简介
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发。
1.1 起源
Python的作者是著名的“龟叔”Guido van Rossum,他希望有一种语言,这种语言能够像C语言那样,能够全面调用计算机的功能接口,又可以像shell那样,可以轻松的编程。龟叔从ABC语言看到希望,ABC语言是由荷兰的数学和计算机研究所开发的。龟叔也参与到ABC语言的开发。由于一系列原因ABC并没有快速传播使用。因此,龟叔开始写Python语言。
1.2 诞生
1989年,龟叔为了打发无聊的圣诞节,开始编写Python语言。1991年,第一个Python编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。特点:“优雅 ”,“明确”,“简单”
1)官 网:https://www.python.org/
2)中文社区:http://www.pythontab.com/
1.3优缺点
优点:简单易学,代码简洁,脚本可拓展,可嵌入,库的支持非常丰富
缺点:运行速度慢,是c和java的以上的封装,代码不能加密(没有编译过程)
2 环境搭建与测试
解释器:Python3.7.x(最新3.8.x)
IDE:jupyter、PyCharm
工具包:Anaconda(内置python,jupyter)
两种环境搭建方式:
1.Python+pip(原生)
2.Anaconda(内容更加丰富,支持多种工具)
Anaconda是什么?
Anaconda是一个用于科学计算的Python发行版,支持 Linux, Mac, Windows系统,提供了包管理与环境管理的功能,可以很方便地解决多版本python并存、切换以及各种第三方包安装问题。Anaconda利用工具/命令conda来进行package和environment的管理,并且已经包含了Python和相关的配套工具。
2.1 推荐环境:Anaconda+PyCharm
2.2 Anaconda下载安装
官网:https://www.anaconda.com/
选择个人开源版本下载安装包


下载安装包后,指定安装目录,凡以下没有特别说明的步骤一路下一步即可







2.3 PyCharm下载安装
官网https://www.jetbrains.com/pycharm/download/#section=windows下载社区版本即可

下载安装包后,指定安装目录,凡以下没有特别说明的步骤一路下一步即可





至此安装完成.
2.4 PyCharm的使用
安装完成后第一次打开会一路下一步直到





默认没有eclipse的keymap可以从plugins中搜索下载
2.5 第一个python程序
#!/home/app/python3.7.6
# -*- coding: utf-8 -*-
print("Hello World!!!")
注意:其中前两行内容为shebang(释伴) 在Unix为内核的系统中,必须要有shebang才能正确识别文件类型.第一行为解释器位置的声明,第二行为字符编码的声明,在windows系统中,文件都以后缀名识别,并且有默认应用和默认字符集的设置,所以在windows中这两行内容不生效.

3 基础语法
3.1 注释
1、单行注释
以井号(#)开头,右边的所有内容当做说明
2、多行注释
以三对单引号或者三对双引号将注释包含起来
# 这是一个单行注释
"""
这是一个多行注释
"""
'''
这也是一个多行注释,但是一般不做为第一个注释来使用
'''
print("Hello World!!!")

3.2 缩进
Python的语法比较简单,采用缩进的方式(严格)。
'''
缩进:在python中,没有行位结束符,但同时对格式的要求也就比较严
格,代码必须以缩进的方式维护格式,同时在运算符的前后应该加上空格
'''
a = 100
if a > 100:
print("大于100")
elif a == 100:
print("等于100")
else:
print("小于100")

注意:
由于Python采用缩进的语法,在你复制,粘贴语句时,一定要注意,重新检查当前代码的缩进格式。
在Python中,对大小写十分敏感,如果大小写错误,会报错。
3.3 变量
变量指存放数据的容器(所有python支持的格式)
3.4 标识符
标识符是自己定义的,如变量名 、函数名等
标识符命名规则
1、只能包含字母、数字和下划线。变量名可以以字母或者下划线开头。但是不能以数字开头。
2、不能包含空格,但可以使用下划线来分隔其中的单词。
3、不能使用Python中的关键字作为变量名
4、建议使用驼峰命名法,驼峰式命名分为大驼峰(UserName)。和小驼峰(userName)。
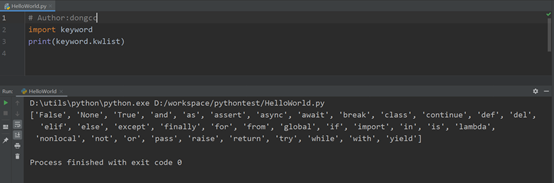
常见关键字不可以作为标识符
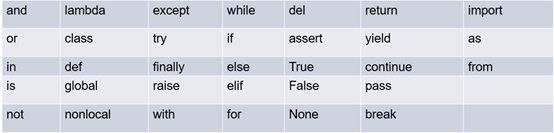
import keyword
print(keyword.kwlist)
4 数据类型

可以用以下两种方式判断数据的类型
type()不会认为子类是一种父类类型。
isinstance()会认为子类是一种父类类型。
4.1 Number(不可变)
4.1.1 整数int
Python可以处理任意大小的整数,当然包括负整数,在程序中的表示方法和数学上的写法一模一样。
"""
int
"""
i = 100
print(type(i))
4.1.2 浮点型float
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的。
"""
float
"""
f = 1.1
print(type(f))
4.1.3 复数complex
一个实数和一个虚数的组合构成一个复数。
"""
complex
"""
c = 2 + 6j
print(type(c))
4.1.4 布尔bool
bool值是特殊的整型,取值范围只有两个值,也就是True和False。
"""
bool
"""
b = True
print(type(b))
print(isinstance(b, bool))
4.1.5 算数运算符

"""
算数运算符
"""
i, j = 10, 3
print(i + j)
print(i - j)
print(i * j)
print(i / j)
print(i % j)
print(i // j)
print(i ** j)
4.1.6 赋值运算符

"""
赋值运算符
"""
num, i = 5, 2
num += i
print(num)
num, i = 5, 2
num -= i
print(num)
num, i = 5, 2
num *= i
print(num)
num, i = 5, 2
num /= i
print(num)
num, i = 5, 2
num %= i
print(num)
num, i = 5, 2
num //= i
print(num)
num, i = 5, 2
num **= i
print(num)
4.1.7 比较运算符
定义a = 1, b = 2

4.1.8 逻辑运算符

4.1.9 位运算符
定义a = 60, b = 13

"""
位运算符
"""
a, b = 4, 2
'''
0000 0100 4
0000 0010 2
0000 0000 0
'''
print(a & b)
'''
0000 0100 4
0001 0000 16
'''
print(a << b)
4.2 String(不可变)
字符串就是一系列任意文本。Python中的字符串用单引号或者双引号括起来,同时可以使用反斜杠(\)转义特殊字符。
单引号(’’)和双引号(“”)本身只是一种表示方式,不是字符串的一部分,因此,字符串’hello’只有h,e,l,l,o这五个字符。如果’本身也是字符的话,那么就可以用””括起来,比如”I’m OK” 当中包含了一个 ’ 。如果字符串内部包含 ’ 或者 ” ,但是又想当成普通字符串处理怎么办?这个时候就要用转义字符(\)来标识。
4.2.1 字符串的声明
"""
字符串的声明:单双引号都可以声明字符串,互相嵌套不需要转义,同符号嵌套需要使用'\'转义,
当希望字符串中的'\'只作为普通字符展示时,在字符串前加'r'
"""
s0 = 'Hello'
s1 = "World"
s2 = '我说了:"你好!",I\'m cc'
print(s1+s2)
s3 = r"do\ngcc"
print(s3)
注意,Python 没有单独的字符类型,一个字符就是长度为1的字符串。
4.2.2 字符串的下标
"""
字符串的下标:正数从0开始,倒数从-1开始
"""
s3 = "abcdef"
print(s3[2])
print(s3[-2])
4.2.3 字符串的截取
变量[头下标:尾下标:步长]
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PL6i59Xp-1592883706298)(C:\Users\87784\AppData\Roaming\Typora\typora-user-images\image-20200623113620453.png)]](https://img-blog.csdnimg.cn/20200623114915187.png)
"""
字符串的截取:s4[头下标:尾下标:步长] 对于[头下标:尾下标]遵循左闭右开的原则
"""
s4 = "abcdef"
print(s4[1:5]) # bcde
print(s4[1:5:2]) # bd
print(s4[-4:-1]) # cde
print(s4[-1:-4:-1]) # fed
print(s4[::-1]) # fedcba
4.2.4 字符串的拼接
加号 + 是字符串的连接符, 星号 * 表示复制当前字符串,紧跟的数字为复制的次数。
"""
字符串的拼接:'+'可以将两个字符串进行拼接,'*'用来多次复制某个字符串
"""
s6 = "Hello"
print(s6+"Python") # HelloPython
print(s6*3+"Python"*2) # HelloHelloHelloPythonPython
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZIlgUz1k-1592883706299)(C:\Users\87784\AppData\Roaming\Typora\typora-user-images\image-20200623113641040.png)]](https://img-blog.csdnimg.cn/20200623114922845.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2RjYzE1MDExMDAzMTAx,size_16,color_FFFFFF,t_70)
4.2.5 格式化输出

"""
格式化输出
"""
name = "董长春"
age = 18
address = "张家口"
wind = 5.5
print("大家好,我叫" + name + ",今年" + str(age) + "岁了,来自" + address + "一个常年刮着" + str(wind) + "级大风的地方")
print("大家好,我叫%s,今年%d岁了,来自%s一个常年刮着%.1f级大风的地方" % (name, age, address, wind))
4.2.6 字符串的常用函数





"""
字符串中的常用函数
"""
# find:查找字符串内是否包含指定内容,如果是,返回位置,否,返回-1
s7 = input("请输入一个字符串:")
print(s7.find('dong'))
# index:查找字符串内是否包含指定内容,如果是,返回位置,否,报错
s7 = "Hi, my name is dongcc"
# print(s7.index('q'))
# 略
4.3 List(可变)
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表是写在方括号 [] 之间、用逗号分隔开的元素列表。
和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
嵌套列表以多级索引进行访问.
"""
列表的定义
"""
my_list = [123, "hello", "cc", [123, 456]]
"""
列表的访问
"""
print(my_list[0]) # 123
print(my_list[3][1]) # 456
4.3.1 列表的截取
列表截取的语法格式如下:
变量[头下标:尾下标:步长]
索引值以 0 为开始值,-1 为从末尾的开始位置。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1VUtyey5-1592883706300)(C:\Users\87784\AppData\Roaming\Typora\typora-user-images\image-20200623113714708.png)]](https://img-blog.csdnimg.cn/20200623114951729.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2RjYzE1MDExMDAzMTAx,size_16,color_FFFFFF,t_70)
"""
列表的截取:与字符串截取一样list[头下标:尾下标:步长]
"""
my_list = [1, 2, 3, 4, 5, 6]
print(my_list[2:5:2])
4.3.2 列表元素的’增删改查’
4.3.2.1 增加元素
"""
增加元素
"""
# 列表后追加
my_list = ["hadoop", "flink", "spark"]
my_list.append('python')
print(my_list) # ['hadoop', 'flink', 'spark', 'python']
# 列表中指定位置插入
my_list = ["hadoop", "flink", "spark"]
my_list.insert(2, 'tensoflow')
print(my_list) # ['hadoop', 'flink', 'tensoflow', 'spark']
4.3.2.2 删除元素
"""
删除元素
"""
# pop():用于移出列表中的一个元素(默认是最后一个元素),可以指定元素索引,并且返回该元素的值。
my_list = ["hadoop", "flink", "spark"]
print(my_list.pop())
print(my_list) # ['hadoop', 'flink'] 默认删除最后一个元素
my_list.pop(0)
print(my_list) # ['flink'] 也可以指定下标删除
print('='*50)
# del:通过列表索引删除某个元素,元素一旦被删除之后就再无法访问,如果不指定索引将会删除整个list
my_list = ["hadoop", "flink", "spark"]
del my_list[0]
print(my_list) # ['flink', 'spark']
del my_list # 整个列表被删除
# print(my_list) # 报错:NameError: name 'my_list' is not defined
print('='*50)
# remove():通过元素值删除list中与之匹配的第一个元素,如果没有这个元素则会报错
my_list = ["hadoop", "flink", "spark", "hadoop"]
my_list.remove("hadoop")
print(my_list) # ['flink', 'spark', 'hadoop']
4.3.2.3 修改元素
修改元素的方式非常简单,就是拿到某个元素后重新赋值的过程.
"""
修改元素:修改列表元素的语法和访问列表元素的语法类似,指定列表名和要修改元素的索引,再指定新值
"""
my_list = ["hadoop", "flink", "spark"]
my_list[2] = "scala"
print(my_list) # ['hadoop', 'flink', 'scala']
4.3.2.4 查找元素
这里的查找是指查看list中是否存在指定的元素.
"""
查找元素:查找指定的元素是否存在,包括两种:in 和 not in
"""
my_list = ["hadoop", "flink", "spark"]
print("hadoop" in my_list) # True
print("hadoop" not in my_list) # False
4.3.2.5 其他操作
加号 + 是列表连接运算符,星号 * 是重复操作。如下实例:
"""
其他操作
"""
list01 = [1, 2, 3, 4]
list02 = [5, 6]
print(list01 + list02) # [1, 2, 3, 4, 5, 6]
print(list01 * 2) # [1, 2, 3, 4, 1, 2, 3, 4]
4.3.3 列表的常用函数



"""
列表常用函数
"""
my_list = ["hadoop", "flink", "spark", "flink"]
ext_list = ["scala", "kafka"]
print(len(my_list)) # 4
print(max(my_list)) # spark
print(min(my_list)) # flink
print(my_list.count("flink"))
my_list.extend(ext_list)
print(my_list) # ['hadoop', 'flink', 'spark', 'flink', 'scala', 'kafka']
4.4 Tuple(不可变)
元组(tuple)与列表类似,不同之处在于元组的元素不能修改,所以不能新增修改或者删除单个元素。元组写在小括号 () 里,元素之间用逗号隔开。
元组中的元素类型也可以不相同.
4.4.1 元组的声明
"""
创建元组:以小括号的方式定义,元素类型任意
"""
in_list = [1, 2, 3]
my_tup = (1, 2, 3, 4, "tuple", in_list)
print(my_tup)
4.4.2 元组的访问
"""
元组的访问:元组的访问与String,list相同,通过下标的方式来进行元素的读取
"""
my_tup = (1, 2, 3, 4, "tuple", ("a", "b", "c"))
print(my_tup[5][1]) # b
4.4.3 元组的截取
"""
元组的截取:元组的截取与String,list相同,通过[头下标:尾下标:步长]操作
"""
my_tup = (1, 2, 3, 4, "tuple", ("a", "b", "c"))
print(my_tup[-1:-4:-2]) # (('a', 'b', 'c'), 4)
4.4.4 元组的转换
元组是不可变的所以不能直接增删改某个元素,但是如果实际需求需要修改,那么可以将其转化为list,同样如果在list使用过程中不希望其中的元素被修改,也可以将其转化为tuple.
"""
元组的转换
"""
my_tup = (1, 2, 3, 4, "tuple", ("a", "b", "c"))
my_list = list(my_tup)
print(type(my_list)) # <class 'list'>
change2tuple = tuple(my_list)
print(type(change2tuple)) # <class 'tuple'>
4.4.5 元组的删除
元组是不可变的,其元素不能单独删除,但是可以将整个元组销毁.
"""
删除整个元组
"""
my_tup = (1, 2, 3, 4, "tuple", ("a", "b", "c"))
del my_tup
print(my_tup) # NameError: name 'my_tup' is not defined
4.4.5 元组的其他操作
同样的元组也支持+号拼接和*号的多次输出
"""
元组的其他操作
"""
my_tup1 = (1, 2, 3, 4)
my_tup2 = (5, 6)
print(my_tup1 + my_tup2) # (1, 2, 3, 4, 5, 6)
print(my_tup1 * 3) # (1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QXVqd6J9-1592883706303)(C:\Users\87784\AppData\Roaming\Typora\typora-user-images\image-20200623113757908.png)]](https://img-blog.csdnimg.cn/2020062311520545.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2RjYzE1MDExMDAzMTAx,size_16,color_FFFFFF,t_70)
其他操作基本与字符串类似,可以把字符串看做一种特殊的元祖。
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
对于有0个或者1个元素的元祖需要特殊定义

4.4.5 元组的常用函数

4.5 Dictionary(可变)
字典(dictionary)是Python中另一个非常有用的内置数据类型。
列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
键(key)必须使用不可变类型。
在同一个字典中,键(key)必须是唯一的。类似java中的map。
4.5.1 字典的声明
"""
字典的声明:字典类似Json的格式,其中的key可以是String,Number或Tuple等不可变类型,value没有类型的限制.
其中,key值必须唯一,如果出现两个相同的key,后边覆盖前边
"""
list0 = [3, 4]
tuple0 = (1, 2)
bool0 = False
complex0 = 4 + 3j
float0 = 1.1
my_dict = {'name': 'dongcc', 'age': 18, 1: 2, 1: 3, float0: tuple0, bool0: list0, complex0: 1, tuple0: 4}
print(my_dict) # {'name': 'dongcc', 'age': 18, 1: 3, 1.1: (1, 2), False: [3, 4], (4+3j): 1, (1, 2): 4}
4.5.2 字典的新增
"""
字典的新增
"""
my_dict = {'name': 'dongcc', 'age': 18, 'address': '张家口'}
print(my_dict)
my_dict['gender'] = '男'
print(my_dict)
4.5.3 字典的修改
"""
字典的修改
"""
my_dict = {'name': 'dongcc', 'age': 18, 'address': '张家口'}
print(my_dict)
my_dict['age'] = 15
print(my_dict)
4.5.4 字典的删除
"""
字典的删除:使用del删除某个键值对,或者整个字典,不能恢复,也可以使用.clear()清空字典
"""
my_dict = {'name': 'dongcc', 'age': 18, 'address': '张家口'}
del my_dict['address']
print(my_dict)
my_dict.clear()
print(my_dict) # {}
del my_dict
print(my_dict) # NameError: name 'my_dict' is not defined
4.5.5 字典的函数和方法




"""
字典的函数和方法
"""
my_dict = {'name': 'dongcc', 'age': 18, 'address': '张家口'}
print(len(my_dict))
print(my_dict.get('name'))
print(my_dict.get('gender', '男')) # 通过key获取value,如果没有对应的key使用默认值'男'
print(my_dict.items()) # dict_items([('name', 'dongcc'), ('age', 18), ('address', '张家口')])
4.5.6 字典的其他操作

构造函数 dict() 可以直接从键值对序列中构建字典如下:
\>>>dict([('Tedu', 1), ('Google', 2), ('Taobao', 3)])
{'Taobao': 3, 'Tedu': 1, 'Google': 2}
\>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
\>>> dict(Tedu=1, Google=2, Taobao=3)
{'Tedu': 1, 'Google': 2, 'Taobao': 3}
4.6 Sets(可变)
集合(set)是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。
Set中不允许重复,基本功能是进行成员关系测试和删除重复元素。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
4.6.1 基本操作
创建格式:
"""
集合的定义:使用{...}的形式定义,定义空集合时不能使用{}因为{}代表空字典,应该使用set()
"""
tuple1 = (1, 2, 3)
my_set = {1, 2, 3, 4, 'hello', tuple1}
null_set = set()
print(my_set)
print(type(null_set))
| 数学符号 | python语法 | 意义 |
|---|---|---|
| ∩ | & | 交集 |
| ∪ | | | 并集 |
| - | - | 差集 |
| ∈ | in | 属于 |
| ∉ | not in | 不属于 |
"""
集合的基本操作
"""
set1 = {1, 2, 3, 4, 5}
set2 = {1, 2, 3}
set3 = {6, 7, 8, 9}
print(set1 & set2)
print(set1 | set3)
print(set1 - set2)


4.7 数据类型转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。

5 分支\循环\推导式
5.1 分支结构if
5.1.1 语法
"""
分支结构-if语句
"""
input_num = int(input("请您输入年龄:"))
if input_num > 18:
print("您已经超过18岁")
elif input_num == 18:
print("您刚好18岁")
else:
print("您未成年")
5.2 循环结构while
5.2.1 语法
"""
while循环
"""
num = 10
while num > 0:
num -= 1
if num == 5:
# break
continue
print(num)
else: # 注意这个else属于while,一般不需要
print("结束")
5.3 循环结构for
5.3.1 语法
"""
for循环
"""
my_list = [1, 2, 3, 4, 5]
for i in my_list[::-1]:
print(i)
my_dict = {'name': 'dongcc', 'age': 16, 'gender': 'male'}
for i in my_dict:
print(i)
print(my_dict[i])
5.3.2 range()
"""
range():传参方式有三种
"""
for i in range(10): # 0~9
print(i)
print('_'*10)
for i in range(5, 10): # 5~9
print(i)
print('_'*10)
for i in range(0, 10, 2): # 0~9 步长为2
print(i)
"""
九九乘法表
"""
for i in range(1, 10):
for j in range(1, i + 1):
print("%d * %d = %d" % (j, i, i * j), end='\t')
print()
5.4 推导式
5.4.1 列表推导式
"""
列表推导式
"""
# [expr for value in collection ifcondition]
my_list = ["day" + str(i) for i in range(1, 10) if i % 2 == 0]
print(my_list) # ['day1', 'day2', 'day3', 'day4', 'day5', 'day6', 'day7', 'day8', 'day9']
5.4.2 字典推导式
"""
字典推导式
"""
# 利用推导式调转dictionary中的kv
my_dict = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
my_dict = {v: k for k, v in my_dict.items()}
print(my_dict) # {'v1': 'k1', 'v2': 'k2', 'v3': 'k3'}
5.4.3 集合推导式
"""
集合推导式
"""
my_set = {x ** 2 for x in [1, 2, 3, 4]}
print(my_set) # {16, 1, 4, 9} 注意这不是错误展示,set无序
6 函数
函数是,组织好的、可重复使用的、用户实现单一或者关联功能的代码段。函数能够提高应用的模块性和代码的重复利用率。Python提供了很多内置的函数,比如len等等,另外也可以根据自己的业务需求进行用户自定义函数的创建。
6.1 内置函数
python中定义了很多内置函数,所谓内置函数就是已经定义好的一些特定功能,可以直接使用.

函数可以直接使用也可以复制给一个变量.
比如:
my_len = len
print(my_len("hello"))
常用的内置函数有:

"""
常用的内置函数
"""
s1 = '1+2'
print(eval(s1)) # 3
s2 = "print('1 + 2 = ' + str(1 + 2))"
exec(s2) # 1 + 2 = 3
my_list = [1, 5, 2, 6, 8, 3]
print(sorted(my_list)) # [1, 2, 3, 5, 6, 8]
print(isinstance(my_list, list)) # True
6.2 函数的定义
- 定义函数使用def关键字+函数名(参数列表)的形式
- 在函数签名中不需要声明返回值(无类型)
- 函数的注释在函数内部的第一行来标注
- 函数内容以冒号开始,并且缩进.函数和其他代码块之间建议空出两行
"""
函数的定义
def 函数名([参数列表]):
#函数说明
逻辑代码
return 返回结果
"""
def print_name(name):
"""
函数的定义
:param name: 传入参数
:return: 返回值
"""
return "我叫" + name
print(print_name('cc'))
6.3 函数的参数
6.3.1 必备参数
函数在调用时必须按照参数列表的规则传参,否则报错.
"""
必备参数(普通的参数):函数在调用时必须按照参数列表的规则传参,否则报错.
"""
def get_info(name, age, addr):
return "%s今年%d岁了,来自%s" % (name, age, addr)
print(get_info('dongcc',12,'张家口'))
6.3.2 关键字参数
关键字参数一般用在参数较多时,为了避免传参对应关系不明晰的问题.在指定关键字后参数传入顺序可以与定义时不一致.但是要注意的是,关键字参数后不能再传入没有关键字的参数.
"""
关键字参数
"""
def get_info(name, age, addr):
return "%s今年%d岁了,来自%s" % (name, age, addr)
print(get_info(age=12, addr='张家口', name='董长春'))
# print(get_info(age=12, addr='张家口', '董长春')) # 编译不通过
6.3.3 参数默认值
函数参数列表在定义时可以使用等号指定该参数的默认值,有默认值得参数调用时可以不传参,则使用默认值,如果传入参数则覆盖掉默认值.需要注意的是有默认值的参数应该定义在参数列表的最后.
"""
默认值参数:
"""
# def get_info(name,age = 18,addr): # 编译不通过,有默认值的参数只能定义在参数列表的最后
def get_info(name,addr,age = 18):
return "%s今年%d岁了,来自%s" % (name, age, addr)
print(get_info('dongcc','张家口'))
print(get_info('dongcc','张家口',12))
6.3.4 可变参数
可变参数用来定义那些事前不清楚调用时会传入多少参数的函数,不确定参数数量的部分使用*或者**来标记,*标记的部分会以tuple保存,**标记的部分会以dictionary来保存.
"""
可变参数
"""
def get_info(name,*args,**kwargs):
print(name)
print(args)
print(kwargs)
get_info('dongcc',1,2,3,4,'hello',age = 12,addr = '张家口')
'''输出
dongcc
(1, 2, 3, 4, 'hello')
{'age': 12, 'addr': '张家口'}
'''
6.4 函数的返回值
6.4.1 return
return可以返回一次返回值,return之后的代码不再被执行.return可以返回单个返回值也可以返回多个返回值.多个返回值时,返回值被保存在tuple中.
"""
return
"""
def get_info_1(name, age, addr):
return name
print(get_info_1('name',12,'张家口'))
def get_info_n(name, age, addr):
return name,age,addr
print(get_info_n('name',12,'张家口')) # ('name', 12, '张家口')
name,age,addr = get_info_n('name',12,'张家口')
print(name)
print(age)
print(addr)
6.4.2 yield
yield可以多次返回函数的返回值,使用yield的函数被称为生成器generator,生成器的返回值是一个迭代器
"""
yield
"""
def get_nums(n):
while(n>0):
yield n
n -= 2
nums = get_nums(10)
print(nums) # <generator object get_nums at 0x000001B2D7CE4648>
print(next(nums))
print('_'*20)
for i in nums:
print(i)
6.5 变量的作用域
与其他的开发语言一样,python中的变量也有作用域的限制,即一般变量并不是在任何位置都可以访问.这样的设计可以增加编程的灵活度.
变量分为局部变量和全局变量,局部变量定义在函数内部只能在局部进行访问,而全局变量定义在函数外部,在当前文件的任何位置都可以访问.
6.5.1 局部变量
局部变量定义在函数内部,只能在函数内部调用,在函数外部或者其他函数中无法调用.函数和函数之间可以定义同名的局部变量,互不影响.
"""
局部变量
"""
def get_name():
name = 'dongcc'
print('函数内部调用' + name)
return name
# print('函数外部调用'+name) # 编译不通过,外部无法读取函数内部的局部变量
print('调用函数'+get_name())
6.5.2 全局变量
定义在函数外部的变量称之为全局变量,全局变量在外部或者函数内部都可以使用.
"""
全局变量
"""
name = 'dongcc'
def print_name():
print(name)
print_name()
6.5.2.1 global关键字
想要在函数内部对全局变量进行修改需要加global关键字,来区分是修改已经存在的全局变量还是定义新的局部变量.
"""
global关键字
"""
name = 'dongcc'
age = 12
def change_name():
name = '百威'
global age # 这里不能直接复制,需要先有一个引入的操作
age = 18
print(name + '已经' + str(age) + '岁了')
change_name() # 百威已经18岁了
print(name) # dongcc
print(age) # 18
写一个小案例
"""
定义一个函数,输入两个数字和一个计算符号,实现四则运算
"""
result = 0
num1, num2, fun = int(input('num1:')), int(input('num2:')), input('fun:')
def comput(num1, num2, fun):
global result
if fun == '+':
result = int(num1).__add__(int(num2))
return "%d %s %d = " % (num1, fun, num2)
elif fun == '-':
result = int(num1).__sub__(int(num2))
return "%d %s %d = " % (num1, fun, num2)
elif fun == '*':
result = int(num1).__mul__(int(num2))
return "%d %s %d = " % (num1, fun, num2)
elif fun == '/':
result = int(num1).__truediv__(int(num2))
return "%d %s %d = " % (num1, fun, num2)
else:
return '输入符号错误'
print(comput(num1, num2, fun) + str(result))
6.6 匿名函数
如果一个函数我们只用一次,那么可以不进行命名,这样没有命名的函数叫做匿名函数.在python中使用lambda表达式来定义匿名函数.
lambda表达式是一个简单的表达式,不是代码块,所以一般不要写太多逻辑在里边,他的返回值就是整个表达式的返回值所以不需要return关键字.一般情况下,lambda表达式作为参数传递给其他函数.
"""
匿名函数:lambda表达式
"""
f = lambda x, y: x + y
print(f(1, 2))
具体的使用我们会在后边的高阶函数的例子中来体现.
6.7 递归函数
递归函数简而言之就是函数调用函数自己来实现递归.
"""
递归函数
"""
def fun(n):
if n > 1:
n = n * fun(n - 1)
return n
print(fun(5))
6.7 常用高阶函数

"""
常用高阶函数
"""
from functools import reduce
my_list1 = [1, 2, 3]
my_list2 = [1, 2, 3]
my_map = map(lambda x, y: "[" + str(x * y) + "]", my_list1, my_list2)
print(list(my_map))
my_list3 = range(100)
my_list3 = filter(lambda a: a % 2 == 0, my_list3)
print(list(my_list3))
my_list4 = range(101)
result = reduce(lambda a, b: a + b, my_list4)
print(result)
7 面向对象
面向对象的编程思想我们已经非常熟悉,目前比较流行的语言基本都包含面向对象编程的方式.当然也包括python.对于面向对象的概念我们不在赘述,着重讨论一下.关于面向过程,面向对象和函数式编程的区别.
面向过程:根据业务进行逻辑的堆叠.代码复用性较差.但是整体性能较强.一般用于开发工具或应用的内核,比如游戏的具体逻辑就需要高速响应.
面向对象:是过程和函数的封装.是事务的高级抽象.他的优势在于代码复用,方便管理和随时调用.但缺点也比较明显,那就是在分布式开发中,从类中实例化对象,从对象中调用函数这样的方式往往都附着状态.带状态的逻辑或者代码并不适合分布式开发的需求.所以我们经常会见到在面向对象思想中的技术难点往往在状态的屏蔽和解耦中.比如分布式事务,分布式锁都是为了解决此类问题.
函数式编程:讲包含具体逻辑的代码块封装为函数,解决了代码复用的问题,同时函数式编程更适合分布式开发的优势在于,发布或传输的代码总是算法.而算法本身没有固定的条件和返回值.输入和输出都由调用者来决定.这样就解决了带状态的问题.但缺点也比较明显.那就是整体过于灵活,灵活的代价就是不稳定,不健壮,鲁棒性较差.所以一般的函数式编程语言也会有面向对象的概念来弥补这一缺点.
7.1 类的定义
类是对象的模板,对象是类的实例.类是抽象的,对象时具象的.我们总是定义类,而使用对象.
"""
类的定义
"""
class Person:
"""
类文档说明
self 代表实例对象本身,可以使用其他单词代替,不是一个关键字,但是规范要求使用self
"""
country = '中国' # 类属性
def __init__(self, name, age, addr='张家口'): # 构造方法,构造方法中声明的属性为实例属性,可以有默认值
print('这是一个构造方法')
self.name = name
self.age = age
self.addr = addr
def info(self): # 普通方法
print("%s今年%d岁了,来自%s" % (self.name, self.age, self.addr))
person = Person('dongcc', 18) # 实例化对象
person.info()
print(person.name)
print(Person.country)
7.1.1 针对属性的常用函数
getattr(obj, name[, default]) : 访问对象的属性
hasattr(obj,name) : 检查是否存在一个属性
setattr(obj,name,value) : 设置一个属性。如果属性不存在,会创建一个新属性
delattr(obj, name) : 删除属性
"""
针对属性操作的常用函数
getattr(obj, name[, default]) : 访问对象的属性
hasattr(obj,name) : 检查是否存在一个属性
setattr(obj,name,value) : 设置一个属性。如果属性不存在,会创建一个新属性
delattr(obj, name) : 删除属性
"""
print(getattr(person, 'name'))
setattr(person, 'gender', '男')
print(person.gender)
print(hasattr(person, 'age'))
7.1.2 内置的类属性
"""
__dict__ : 类的属性(包含一个字典,由类的属性名:值组成) 实例化类名.__dict__
__doc__ :类的文档字符串 (类名.)实例化类名.__doc__
__name__: 类名,实现方式 类名.__name__
__bases__ : 类的所有父类构成元素(包含了以个由所有父类组成的元组)类名.__bases__
"""
print(person.__dict__)
print(person.__doc__)
print(Person.__name__)
print(Person.__bases__)
7.2 继承和多态
7.3 类属性实例属性
7.4 访问权限
7.5 类方法与静态方法
8 模块和包
8.1 模块
8.2 模块制作
8.3 dir()函数
8.4 标准模块
8.5 包
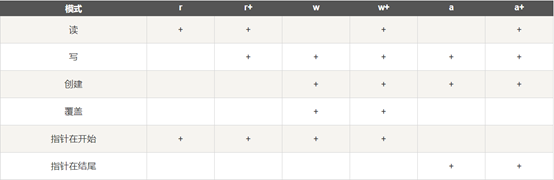
9 文件和异常
9.1 文件的操作
9.2 文件的读写
9.3 异常
10 爬虫案例练习
10.1 什么是爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。
简而言之:请求网站并提取数据的自动化程序
10.2 关于爬虫的法律常识
- 必须遵守Robots协议(eg:https://www.jd.com/robots.txt)
User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符
Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录
Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录
Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录
Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。
Disallow: /*?* 禁止访问网站中所有包含问号 (?) 的网址
Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片
Disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件。
Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录
Allow: /tmp 这里定义是允许爬寻tmp的整个目录
Allow: .htm$ 仅允许访问以".htm"为后缀的URL。
Allow: .gif$ 允许抓取网页和gif格式图片
Sitemap: 网站地图 告诉爬虫这个页面是网站地图
- 放慢速度
- 不突破反爬
- 对于爬虫项目或者爬虫任务要认真评估风险
遵守以上规则避免从入门到入狱
10.3 爬虫的基本概念
10.3.1 基本流程
- 发送请求
- 获取内容
- 解析数据
- 保存数据
10.3 爬虫基础知识
java:jsoup\WebMagic\Nutch
python:requests\scrapy\Splash
10.3.1 正则表达式
正则表达式是对字符串操作的⼀种逻辑公式,就是⽤事先定义好的⼀些特定
字符、及这些特定字符的组合,组成⼀个“规则字符串”,这个“规则字符串”⽤
来表达对字符串的⼀种过滤逻辑。
基本语法
| 模式 | 描述 |
|---|---|
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9] |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| […] | 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’ |
| [^…] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| * | 匹配0个或多个的表达式。 |
| + | 匹配1个或多个的表达式。 |
| ? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| 精确匹配n个前面表达式。 | |
| 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 | |
| a|b | 匹配a或b |
| ( ) | 匹配括号内的表达式,也表示一个组 |
常用的正则表达式
一、校验数字的表达式
数字:^[0-9]*$
n位的数字:^\d{n}$
至少n位的数字:^\d{n,}$
m-n位的数字:^\d{m,n}$
零和非零开头的数字:^(0|[1-9][0-9]*)$
非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(\.[0-9]{1,2})?$
带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})$
正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
有两位小数的正实数:^[0-9]+(\.[0-9]{2})?$
有1~3位小数的正实数:^[0-9]+(\.[0-9]{1,3})?$
非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
非负整数:^\d+$ 或 ^[1-9]\d*|0$
非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
校验字符的表达式
汉字:^[\u4e00-\u9fa5]{0,}$
英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
长度为3-20的所有字符:^.{3,20}$
由26个英文字母组成的字符串:^[A-Za-z]+$
由26个大写英文字母组成的字符串:^[A-Z]+$
由26个小写英文字母组成的字符串:^[a-z]+$
由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
禁止输入含有~的字符:[^~\x22]+
三、特殊需求表达式
Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.?
InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|4|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号): ((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$)
身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)
帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$
强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
日期格式:^\d{4}-\d{1,2}-\d{1,2}
一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
钱的输入格式:
有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
中文字符的正则表达式:[\u4e00-\u9fa5]
双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
空白行的正则表达式:\n\s*\r (可以用来删除空白行)
HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? /> ( 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))
10.3.2 requests请求
基本写法
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)
带参写法
import requests
data = {
'name': 'germey',
'age': 22
}
response = requests.get("http://httpbin.org/get", params=data)
print(response.text)
解析json
import requests
import json
response = requests.get("http://httpbin.org/get")
print(type(response.text))
print(response.json())
print(json.loads(response.text))
print(type(response.json()))
获取二进制(图片\视频)
import requests
response = requests.get("https://github.com/favicon.ico")
print(type(response.text), type(response.content))
print(response.text)
print(response.content)
# 把图片写入当前文件夹
with open('favicon.ico', 'wb') as f:
f.write(response.content)
f.close()
添加headers
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
response = requests.get("https://www.zhihu.com/explore", headers=headers)
print(response.text)
10.3.3 BeautifulSoup解析
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, “html.parser”) | Python的内置标准库、执行速度适中 、文档容错能力强 | Python 2.7.3 or 3.2.2)前的版本中文容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 速度快、文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, “xml”) | 速度快、唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 | 速度慢、不依赖外部扩展 |
基本使用
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.prettify())
print(soup.title.string)
标签选择器
选择元素
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.title)
print(type(soup.title))
print(soup.head)
print(soup.p)
获取名称
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.title.name)
获取属性
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.p.attrs['name'])
print(soup.p['name'])
获取内容
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p clss="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.p.string)
嵌套选择
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.head.title.string)
子节点和子孙节点
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.p.contents)
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.p.children)
for i, child in enumerate(soup.p.children):
print(i, child)
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.p.descendants)
for i, child in enumerate(soup.p.descendants):
print(i, child)
父节点和祖先节点
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.a.parent)
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(list(enumerate(soup.a.parents)))
兄弟节点
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(list(enumerate(soup.a.next_siblings)))
print(list(enumerate(soup.a.previous_siblings)))
标准选择器
find_all( name , attrs , recursive , text , **kwargs )
可根据标签名、属性、内容查找文档
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all('ul'))
print(type(soup.find_all('ul')[0]))
10.4 案例一:runoob练习题
"""
create database `pydb` character set utf8 collate utf8_general_ci;
CREATE TABLE `pyquestion` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`title` VARCHAR(50) NULL DEFAULT NULL COLLATE 'utf8_general_ci',
`info` VARCHAR(500) NULL DEFAULT NULL COLLATE 'utf8_general_ci',
PRIMARY KEY (`id`) USING BTREE
);
抓取runoob上python100道练习题
robots.txt
User-agent: *
Disallow: /wp-admin/
Disallow: /feed/
Disallow: /*/feed/
Disallow: /trackback/
Disallow: /*/trackback/
Disallow: /page/
Disallow: /try/
Disallow: /wp-*.php
Disallow: /wp-includes/
Disallow: /?s=*
"""
import time
from bs4 import BeautifulSoup
import requests
import pymysql
import sys
# 1.伪装浏览器,requests访问网址拿到dom对象并获取文本
url = 'https://www.runoob.com/python/python-100-examples.html'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/83.0.4103.106 Safari/537.36 '
}
response = requests.get(url, headers).text
# 2.使用bs解析文本为html
html = BeautifulSoup(response, "lxml")
# 3.获取并格式化所有二级链接
a_html = html.find(id="content").find_all("a")
a_href_list = ["https://www.runoob.com" + i.attrs["href"] for i in a_html]
# https://www.runoob.com/python/python-exercise-example1.html
# 4.获取数据库连接
try:
db = pymysql.connect("localhost", "root", "root", "py1db")
print("数据连接成功!")
except Exception as e:
print(e)
print("数据库连接失败!")
sys.exit(1)
# 5.获取操作游标
cursor = db.cursor()
# 6.对所有二级链接进行请求解析
for i in range(len(a_href_list)):
# 6.1.伪装浏览器,requests访问网址拿到二级链接dom对象并获取文本
example_response = requests.get(a_href_list[i], headers).text
# 6.2.使用bs解析文本为html
example_html = BeautifulSoup(example_response, "lxml")
# 6.3.定位数据并获取内容
find = example_html.find(id="content")
question_title = find.h1.text
question_info = find.find_all("p")[1].text
# 6.4.存入数据库
# 6.4.1.初始化sql
sql = "insert into pyquestion values (NULL,'%s','%s')" % (question_title, question_info)
try:
# 6.4.2.执行sql
cursor.execute(sql)
# 6.4.3.提交事务
db.commit()
print("第%d条插入成功" % (i+1))
except Exception as e:
print(e)
# 6.4.3.失败回滚
db.rollback()
# 7.睡眠,降低服务器压力
time.sleep(1)
# 8.关闭数据库连接
db.close()
文件
本文由 liyunfei 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jun 24,2022