
Redis主从复制
简介
单个Redis支持的读写能力还是有限的,此时我们可以使用多个redis来提高redis的并发处理能力,这些redis如何协同,就需要有一定的架构设计,这里我们首先从主从(Master/Slave)架构进行分析和实现.
为了分担服务器压力,会在特定情况下部署多台服务器分别用于缓存的读和写操作,用于写操作的服务器称为主服务器,用于读操作的服务器称为从服务器。
从服务器通过 psync 操作同步主服务器的写操作,并按照一定的时间间隔更新主服务器上新写入的内容。
Redis 主从复制的过程:
- Slave 与 Master 建立连接,发送 psync 同步命令。
- Master 会启动一个后台进程,将数据库快照保存到文件中,同时 Master 主进程会开始收集新的写命令并缓存。
- 后台完成保存后,就将此文件发送给 Slave。
- Slave 将此文件保存到磁盘上。
Redis 主从复制特点:
- 可以拥有多个 Slave。
- 多个 Slave 可以连接同一个 Master 外,还可以连接到其它的 Slave。(当 Master 宕机后,相连的 Slave 转变为 Master)。
- 主从复制不会阻塞 Master,在同步数据时, Master 可以继续处理 Client 请求。
- 提高了系统的可伸缩性。
从服务器的主要作用是响应客户端的数据请求,比如返回一篇博客信息。
上面说到了主从复制是不会阻塞 Master 的,就是说 Slave 在从 Master 复制数据时,Master 的删改插入等操作继续进行不受影响。
如果在同步过程中,主服务器修改了一篇博客,而同步到从服务器上的博客是修改前的。这时候就会出现时间差,即修改了博客过后,在访问网站的时候还是原来的数据,这是因为从服务器还未同步最新的更改,这也就意味着非阻塞式的同步只能应用于对读数据延迟接受度较高的场景。
要建立这样一个主从关系的缓存服务器,只需要在 Slave 端执行命令:
# SLAVEOF IPADDRESS PORT
> SLAVEOF 127.0.0.1 6379
如果主服务器设置了连接密码,就需要在从服务器中事先设置好:
config set masterauth <password>
这样,当前服务器就作为 127.0.0.1:6379 下的一个从服务器,它将定期从该服务器复制数据到自身。
在以前的版本中(2.8 以前),你应该慎用 redis 的主从复制功能,因为它的同步机制效率低下,可以想象每一次短线重连都要复制主服务器上的全部数据,算上网络通讯所耗费的时间,反而可能达不到通过 redis 缓存来提升应用响应速度的效果。但是幸运的是,官方在 2.8 以后推出了解决方案,通过部分同步来解决大量的重复操作。
这需要主服务器和从服务器都至少达到 2.8 的版本要求。
基本架构
redis主从架构如图所示:
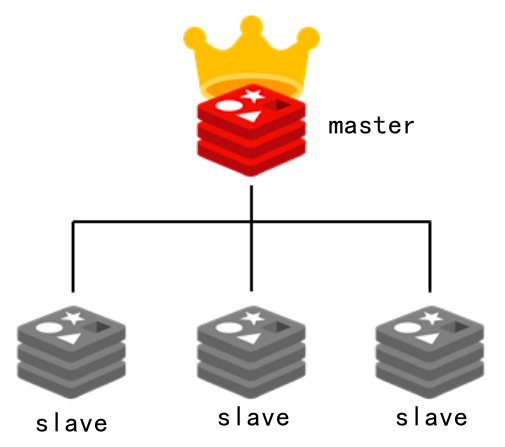
其中,master负责读写,并将数据同步到salve,从节点负责读操作.
快速入门实践
基于redis,设计一主从架构,一个Master,两个Slave,其中Master负责Redis读写操作,并将数据同步到Slave,Slave只负责读.,其步骤如下:
第一步:删除所有原有的redis容器(为了避免内存不足,宿主机端口冲突),例如:
docker rm -f redis容器名
第二步:进入你的宿主机docker目录,然后将redis01拷贝两份,例如:
cp -r redis01/ redis02
cp -r redis01/ redis03
第三步:启动三个新的redis容器,例如:
docker run -p 6379:6379 --name redis6379 \
-v /usr/local/docker/redis01/data:/data \
-v /usr/local/docker/redis01/conf/redis.conf:/etc/redis/redis.conf \
-d redis redis-server /etc/redis/redis.conf \
--appendonly yes
docker run -p 6380:6379 --name redis6380 \
-v /usr/local/docker/redis02/data:/data \
-v /usr/local/docker/redis02/conf/redis.conf:/etc/redis/redis.conf \
-d redis redis-server /etc/redis/redis.conf \
--appendonly yes
docker run -p 6381:6379 --name redis6381 \
-v /usr/local/docker/redis03/data:/data \
-v /usr/local/docker/redis03/conf/redis.conf:/etc/redis/redis.conf \
-d redis redis-server /etc/redis/redis.conf \
--appendonly yes
第四步 检测redis服务角色
启动三个客户端,分别登陆三台redis容器服务,通过info指令进行角色查看,默认新启动的三个redis服务角色都为master.
127.0.0.1:6379> info replication
\# Replication
role:master
connected_slaves:0
master_repl_offset:3860
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:3859
第五步:检测redis6379的ip设置
docker inspect redis6379
……
"Networks": {
"bridge": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"NetworkID": "c33071765cb48acb1efed6611615c767b04b98e6e298caa0dc845420e6112b73",
"EndpointID": "4c77e3f458ea64b7fc45062c5b2b3481fa32005153b7afc211117d0f7603e154",
"Gateway": "172.17.0.1",
"IPAddress": "172.17.0.2",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "02:42:ac:11:00:02",
"DriverOpts": null
}
}
第六步:设置Master/Slave架构
分别登陆redis6380/redis6381,然后执行如下语句
slaveof 172.17.0.2 6379
说明,假如master有密码,需要在slave的redis.conf配置文件中添加"masterauth 你的密码"这条语句,然后重启redis再执行slaveof 指令操作.
第七步:再次登陆redis6379,然后检测info
[root@centos7964 ~]# docker exec -it redis6379 redis-cli
127.0.0.1:6379> info replication
\# Replication
role:master
connected_slaves:2
slave0:ip=172.17.0.3,port=6379,state=online,offset=2004,lag=1
slave1:ip=172.17.0.4,port=6379,state=online,offset=2004,lag=1
master_failover_state:no-failover
master_replid:5baf174fd40e97663998abf5d8e89a51f7458488
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:2004
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:2004
第八步: 登陆redis6379测试,master读写都可以
[root@centos7964 ~]# docker exec -it redis6379 redis-cli
127.0.0.1:6379> set role master6379
OK
127.0.0.1:6379> get role
"master6379"
127.0.0.1:6379>
第九步: 登陆redis6380测试,slave只能读。
[root@centos7964 ~]# docker exec -it redis6380 redis-cli
127.0.0.1:6379> get role
"master6379"
127.0.0.1:6379> set role slave6380
(error) READONLY You can't write against a read only replica.
127.0.0.1:6379>
Java中的读写测试分析,代码如下:
@SpringBootTest
public class MasterSlaveTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void testMasterReadWrite(){//配置文件端口为6379
ValueOperations valueOperations = redisTemplate.opsForValue();
valueOperations.set("role", "master6379");
Object role = valueOperations.get("role");
System.out.println(role);
}
@Test
void testSlaveRead(){//配置文件端口为6380
ValueOperations valueOperations = redisTemplate.opsForValue();
Object role = valueOperations.get("role");
System.out.println(role);
}
}
主从同步原理分析
Redis的主从架构可以采用一主多从结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步。
- Redis全量同步:
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
1)从服务器连接主服务器,发送SYNC命令;
2)主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
3)主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
4)从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
5)主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
6)从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
- Redis增量同步
Redis增量复制是指Slave初始化后,开始正常工作时主服务器发生的写操作同步到从服务器的过程。 增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
小节面试分析
- redis如何支持10万+的并发?
单机的redis几乎不太可能说QPS超过10万+,除非一些特殊情况,比如你的机器性能特别好,配置特别高,物理机,维护做的特别好,而且你的整体的操作不是太复杂,一般的单机也就在几万。真正实现redis的高并发,需要读写分离。对缓存而言,一般都是用来支撑读高并发的,写的请求是比较少的,可能写请求也就一秒钟几千。读的请求相对就会比较多,例如,一秒钟二十万次读。所以redis的高并发可以基于主从架构与读写分离机制进行实现。
- Redis的replication机制是怎样的?
(1)redis采用异步方式复制数据到slave节点。
(2)一个master 节点是可以配置多个slave节点的。
(3)slave 节点做复制的时候,是不会阻塞 master 节点的正常工作的。
(4)slave 节点在做复制的时候,也不会阻塞对自己的查询操作,它会用旧的数据集来提供服务; 但是复制完成的时候,需要删除旧数据集,加载新数据集,这个时候就会暂停对外服务了。
(5)slave 节点主要用来进行横向扩容,做读写分离,扩容的slave节点可以提高读的吞吐量。
Redis哨兵模式
简介
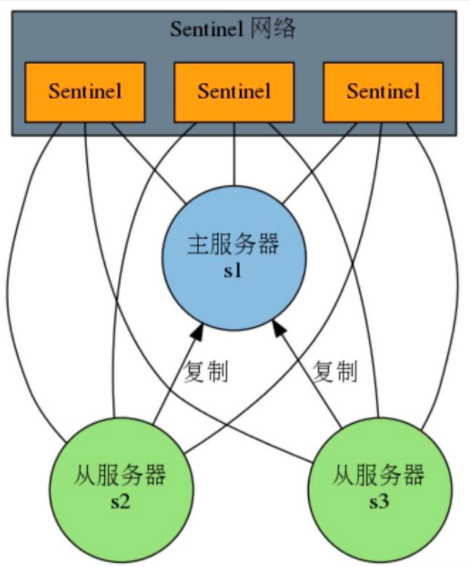
哨兵(Sentinel)是Redis主从架构模式下,实现高可用性(high availability)的一种机制。由一个或多个Sentinel实例组成的Sentinel系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求。
基本架构
哨兵快速入门
第一步:打开三个redis客户端窗口,分别进入3台redis容器内部,在容器(Container)指定目录/etc/redis中执行如下语句:
cat <<EOF > /etc/redis/sentinel.conf
sentinel monitor redis6379 172.17.0.2 6379 1
EOF
其中, 如上指令表示要的监控的master, redis6379为服务名, 172.17.0.2和6379为master的ip和端口,1表示多少个sentinel认为一个master失效时,master才算真正失效.
第二步:在每个redis容器内部的/etc/redis目录下执行如下指令,启动哨兵服务
redis-sentinel sentinel.conf
第三步:打开一个新的客户端连接窗口,关闭redis6379服务(这个服务是master服务)
docker stop redis6379
在其它客户端窗口,检测日志输出,例如
410:X 11 Jul 2021 09:54:27.383 # +switch-master redis6379 172.17.0.2 6379 172.17.0.4 6379
410:X 11 Jul 2021 09:54:27.383 * +slave slave 172.17.0.3:6379 172.17.0.3 6379 @ redis6379 172.17.0.4 6379
410:X 11 Jul 2021 09:54:27.383 * +slave slave 172.17.0.2:6379 172.17.0.2 6379 @ redis6379 172.17.0.4 6379
第四步:登陆ip为172.17.0.4对应的服务进行info检测,例如:
127.0.0.1:6379> info replication
\# Replication
role:master
connected_slaves:1
slave0:ip=172.17.0.3,port=6379,state=online,offset=222807,lag=0
master_failover_state:no-failover
master_replid:3d63e8474dd7bcb282ff38027d4a78c413cede53
master_replid2:5baf174fd40e97663998abf5d8e89a51f7458488
master_repl_offset:222807
second_repl_offset:110197
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:29
repl_backlog_histlen:222779
127.0.0.1:6379>
从上面的信息输出发现,redis6381服务现在已经变为master。
Sentinel 配置进阶
对于sentinel.conf文件中的内容,我们还可以基于实际需求,进行增强配置,例如:
sentinel monitor redis6379 172.17.0.2 6379 1
daemonize yes #后台运行
logfile "/var/log/sentinel_log.log" #运行日志
sentinel down-after-milliseconds redis6379 30000 #默认30秒
其中:
1)daemonize yes表示后台运行(默认为no)
2)logfile 用于指定日志文件位置以及名字
3)sentinel down-after-milliseconds 表示master失效了多长时间才认为失效
例如: 基于cat指令创建sentinel.conf文件,并添加相关内容.
cat <<EOF > /etc/redis/sentinel.conf
sentinel monitor redis6379 172.17.0.2 6379 1
daemonize yes
logfile "/var/log/sentinel_log.log"
sentinel down-after-milliseconds redis6379 30000
EOF
哨兵工作原理分析
1)每个Sentinel以每秒一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令。
2)如果一个Redis服务距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值(这个配置项指定了需要多少失效时间,一个master才会被这个sentinel主观地认为是不可用的。 单位是毫秒,默认为30秒), 则这个Redis服务会被 Sentinel 标记为主观下线。
3)如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
4)当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线 。
5)在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令 。
6)当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次 。
7)若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被移除。
8)若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
Redis集群高可用
简述
Redis单机模式可靠性保证不是很好,容易出现单点故障,同时其性能也受限于CPU的处理能力,实际开发中Redis必然是高可用的,所以单机模式并不是我们的终点,我们需要对目前redis的架构模式进行升级。
Sentinel模式做到了高可用,但是实质还是只有一个master在提供服务(读写分离的情况本质也是master在提供服务),当master节点所在的机器内存不足以支撑系统的数据时,就需要考虑集群了。
Redis集群架构实现了对redis的水平扩容,即启动N个redis节点,将整个数据分布存储在这N个redis节点中,每个节点存储总数据的1/N。redis集群通过分区提供一定程度的可用性,即使集群中有一部分节点失效或无法进行通讯,集群也可以继续处理命令请求。
基本架构
对于redis集群(Cluster),一般最少设置为6个节点,3个master,3个slave,其简易架构如下:
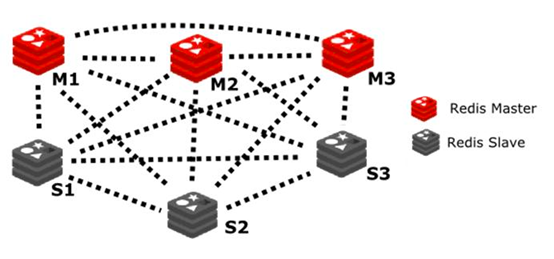
创建集群
第一步:准备网络环境
创建虚拟网卡,主要是用于redis-cluster能于外界进行网络通信,一般常用桥接模式。
docker network create redis-net
查看docker的网卡信息,可使用如下指令
docker network ls
查看docker网络详细信息,可使用命令
docker network inspect redis-net
第二步:准备redis配置模板
mkdir -p /usr/local/docker/redis-cluster
cd /usr/local/docker/redis-cluster
vim redis-cluster.tmpl
在redis-cluster.tmpl中输入以下内容
port ${PORT}
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 192.168.126.129
cluster-announce-port ${PORT}
cluster-announce-bus-port 1${PORT}
appendonly yes
其中:
各节点解释如下所示:
- port:节点端口,即对外提供通信的端口
- cluster-enabled:是否启用集群
- cluster-config-file:集群配置文件
- cluster-node-timeout:连接超时时间
- cluster-announce-ip:宿主机ip
- cluster-announce-port:集群节点映射端口
- cluster-announce-bus-port:集群总线端口
- appendonly:持久化模式
第三步:创建节点配置文件
在redis-cluser中执行以下命令
for port in $(seq 8010 8015); \
do \
mkdir -p ./${port}/conf \
&& PORT=${port} envsubst < ./redis-cluster.tmpl > ./${port}/conf/redis.conf \
&& mkdir -p ./${port}/data; \
done
其中:
- for 变量 in $(seq var1 var2);do …; done为linux中的一种shell 循环脚本, 例如:
[root@centos7964 ~]# for i in $(seq 1 5);
> do echo $i;
> done;
1
2
3
4
5
[root@centos7964 ~]#
- 指令envsubst <源文件>目标文件,用于将源文件内容更新到目标文件中.
通过cat指令查看配置文件内容
cat /usr/local/docker/redis-cluster/801{0..5}/conf/redis.conf
第四步:创建集群中的redis节点容器
for port in $(seq 8010 8015); \
do \
docker run -it -d -p ${port}:${port} -p 1${port}:1${port} \
--privileged=true -v /usr/local/docker/redis-cluster/${port}/conf/redis.conf:/usr/local/etc/redis/redis.conf \
--privileged=true -v /usr/local/docker/redis-cluster/${port}/data:/data \
--restart always --name redis-${port} --net redis-net \
--sysctl net.core.somaxconn=1024 redis redis-server /usr/local/etc/redis/redis.conf; \
done
其中, --privileged=true表示让启动的容器用户具备真正root权限, --sysctl net.core.somaxconn=1024 这是一个linux的内核参数,用于设置请求队列大小,默认为128,后续启动redis的启动指令需要先放到这个请求队列中,然后依次启动.
创建成功以后,通过docker ps指令查看节点内容。
第五步:创建redis-cluster集群配置
docker exec -it redis-8010 bash
redis-cli --cluster create 192.168.126.129:8010 192.168.126.129:8011 192.168.126.129:8012 192.168.126.129:8013 192.168.126.129:8014 192.168.126.129:8015 --cluster-replicas 1
如上指令要尽量放在一行执行,其中最后的1表示主从比例,当出现选择提示信息时,输入yes即可。
第六步:连接redis-cluster,并添加数据到redis
redis-cli -c -h 192.168.126.129 -p 8010
其中,这里-c表示集群(cluster),-h表示host(一般写ip地址),-p为端口(port)
登录成功后,可以通过如下指令,查看redis相关信息.
cluster nodes #查看集群节点数
cluster info #查看集群基本信息
其它:
在搭建过程,可能在出现问题后,需要停止或直接删除docker容器,可以使用以下参考命令:
批量停止docker 容器,例如:
docker ps -a | grep -i "redis-801*" | awk '{print $1}' | xargs docker stop
批量删除docker 容器,例如
docker ps -a | grep -i "redis-801*" | awk '{print $1}' | xargs docker rm -f
批量删除文件,目录等,例如:
rm -rf 801{0..5}/conf/redis.conf
rm -rf 801{0..5}
以上就是基于docker搭建redis-cluster的简单步骤,实际应用中可能还要更复杂一些,该文仅用于参考。
Jedis读写数据测试
在redis-jedis创建JedisClusterTests测试类,并添加如下单元测试方法,进行redis访问测试.
@Test
void testJedisCluster()throws Exception{
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.126.129",8010));
nodes.add(new HostAndPort("192.168.126.129",8011));
nodes.add(new HostAndPort("192.168.126.129",8012));
nodes.add(new HostAndPort("192.168.126.129",8013));
nodes.add(new HostAndPort("192.168.126.129",8014));
nodes.add(new HostAndPort("192.168.126.129",8015));
JedisCluster jedisCluster = new JedisCluster(nodes);
//使用jedisCluster操作redis
jedisCluster.set("test", "cluster");
String str = jedisCluster.get("test");
System.out.println(str);
//关闭连接池
jedisCluster.close();
}
RedisTemplate读写数据测试
第一步:配置application.yml,例如:
spring:
redis:
cluster: #redis 集群配置
nodes: 192.168.126.129:8010,192.168.126.129:8011,192.168.126.129:8012,192.168.126.129:8013,192.168.126.129:8014,192.168.126.129:8015
max-redirects: 3 #最大跳转次数
timeout: 5000 #超时时间
database: 0
jedis: #连接池 (假如配置lettuce池,项目中需要先添加commons-pool2依赖)
pool:
max-idle: 8
max-wait: 0
第二步:编写单元测试类,代码如下:
package com.cy.redis;
@SpringBootTest
public class RedisClusterTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void testMasterReadWrite(){
//1.获取数据操作对象
ValueOperations valueOperations = redisTemplate.opsForValue();
//2.读写数据
valueOperations.set("city","beijing");
Object city=valueOperations.get("city");
System.out.println(city);
}
}
小节面试分析
- Redis的高并发跟整个系统的高并发是什么关系?
第一:Redis要支持高并发,要把底层的缓存搞得很好。例如,mysql的高并发,是通过一系列复杂的分库分表,订单系统,事务要求的,QPS到几万,比较高了。
第二:要做一些电商的商品详情页,真正的超高并发,QPS上十万,甚至是百万,一秒钟百万的请求量,只有redis是不够的,但是redis是整个大型的缓存架构中,支撑高并发的架构里面,非常重要的一个环节。
第三:你的底层的缓存中间件,缓存系统,必须能够支撑的起我们说的那种高并发,其次,再经过良好的整体的缓存架构的设计(多级缓存架构、热点缓存),支撑真正的上十万,甚至上百万的高并发。
总结(Summary)
本章节从redis高性能,高可靠性的角度对redis的主从架构,读写分离、哨兵机制、集群方式做了分析实践。这部分内容也是中大型项目中redis常用的一些架构设计方式。
常见问题分析
- Redis主从架构,哨兵,集群架构诞生的一个背景?
- 单纯的Redis主从架构存在什么问题?(主机点宕机,整个主从不再支持写操作)
- Redis哨兵(sentinel)做用是什么?(监控主从节点工作状态,主节点宕机,自动选择新的主节点)
- Redis 从节点下还可有从节点吗?(可以的,薪火相传)
- Redis主从加哨兵还存在什么明显缺陷?(主节点只有一个,支持可存储的数据量受限)
- 集群架构要解决的主要问题是什么?(横向扩容,单个主节点不能支持更大并发的写操作,且容量有限)
- 当架构设计中的redis服务有问题时怎么办?(一定要看容器日志)
常见Bug分析
- 架构实践过程中要注意ip地址(最核心问题)。
- 服务内存不足,导致服务启动失败。
本文由 liyunfei 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Sep 21,2022