
一、介绍
内容
本节主要介绍 Scala 的隐含参数(即隐式参数)的使用方法,但它的使用是有一些限定条件的。希望通过本节的学习,你能掌握它们的用法。
知识点
- 隐含参数的使用
- View 限定
- 多个隐含转换的选择
环境
- Scala 2.11.8
- Xfce 终端
适合人群
本课程难度为一般,属于初级级别课程,适合 Scala 编程基础的用户。
二、开发准备
为了使用交互式 Scala 解释器,你可以在打开的终端中输入命令:
su -l hadoop
scala
当出现scala>开始的命令行提示符时,就说明你已经成功进入解释器了。如下图所示。
本实验的所有命令及语句均可在 Shell 中输入。
三、步骤
3.1 使用隐含参数
编译器可以自动插入 implicit 的最后一个用法是隐含参数。 比如编译器在需要时,可以把 someCall(a) 修改为 someCall(a)(b) ,或者是将 new someClass(a) 修改为 new SomeClass(a)(b) 。也就是说,编译器在需要的时候,会自动补充缺少的参数来完成方法的调用。其中 (b) 为一组参数,而不仅仅只最后一个参数。
这里我们给出一个简单的例子:假定你定义了一个类 PreferredPrompt ,其中定义了一个用户选择的命令行提示符(比如 “$” 或者 “>” )。
尝试在 Shell 中输入下列命令:
class PreferredPrompt(val preference:String)

另外,我们再定义一个 Greeter 对象,该对象定义了一个 greet 方法。该方法定义了两个参数:第一个参数代表用户姓名;第二个参数类型为 PreferredPrompt ,代表提示符。
尝试在 Shell 中定义该对象:
object Greeter{
def greet(name:String)(implicit prompt: PreferredPrompt) {
println("Welcome, " + name + ". The System is ready.")
println(prompt.preference)
}
}
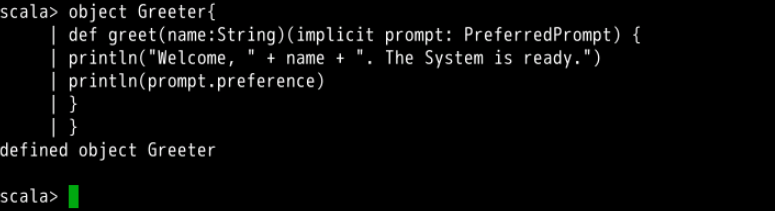
第二个参数标记为 implicit ,表明允许编译器根据需要自动添加。 我们首先采用一般方法的调用方法,提供所有的参数:
scala> val bobsPrompt =new PreferredPrompt("relax> ")
bobsPrompt: PreferredPrompt = PreferredPrompt@7e68a062
scala> Greeter.greet("Bob")(bobsPrompt)
Welcome, Bob. The System is ready.
relax>
这种用法与我们不给第二个参数添加 implicit 调用相比,呈现一样的结果。前面我们提过,隐含参数的用法有点类似某些 Dependency Injection 框架。比如我们在某些地方定义一个 PreferredPrompt 对象,而希望编译器在需要时注入该对象,那该如何使用呢?
首先,我们要定义一个对象,然后在该对象中定义一个 PreferredPrompt 类型的隐含实例:
object JamesPrefs{
implicit val prompt=new PreferredPrompt("Yes, master> ")
}

然后我们只提供第二个参数看看什么情况:
scala> Greeter.greet("James")
<console>:10: error: could not find implicit value for parameter prompt: PreferredPrompt
Greeter.greet("James")
^
可以看到出错了,这是因为编译器在当前作用域找不到 PreferredPrompt 类型的隐含变量。而它定义在对象 JamesPrefs 中,因此需要使用 import 引入:
scala> import JamesPrefs._
import JamesPrefs._
scala> Greeter.greet("James")
Welcome, James. The System is ready.
Yes, master>
可以看到编译器自动插入了第二个参数。要注意的是, implicit 关键字作用到整个参数列表,我们修改一下上面的例子看看:
class PreferredPrompt(val preference:String)
class PreferredDrink(val preference:String)
object Greeter{
def greet(name:String)(implicit prompt: PreferredPrompt, drink:PreferredDrink) {
println("Welcome, " + name + ". The System is ready.")
print("But while you work,")
println("why not enjoy a cup of " + drink.preference + "?")
println(prompt.preference)
}
}
object JamesPrefs{
implicit val prompt=new PreferredPrompt("Yes, master> ")
implicit val drink=new PreferredDrink("coffee")
}
import JamesPrefs._
Greeter.greet("James")
scala> Greeter.greet("James")
Welcome, James. The System is ready.
But while you work,why not enjoy a cup of coffee?
Yes, master>
这里有一点要注意的是,对于这里的 implicit 参数的类型,我们没有直接使用 String 类型。事实上,我们可以使用 String 类型:
object Greeter{
def greet(name:String)(implicit prompt: String) {
println("Welcome, " + name + ". The System is ready.")
println(prompt)
}
}
implicit val prompt="Yes, master> "
Greeter.greet("James")
scala> Greeter.greet("James")
Welcome, James. The System is ready.
Yes, master>
但问题是,如果有多个参数都使用 implicit 类型,并且它们的类型相同,你就无法提供多个参数。因此 implicit 类型的参数一般都是定义特殊的类型。
隐含参数的另外一个用法是给前面明确定义的参数补充说明一些信息。
我们先给出一个没有使用隐含参数的例子:
def maxListUpBound[T <:Ordered[T]](element:List[T]):T =
element match {
case List() =>
throw new IllegalArgumentException("empty list!")
case List(x) => x
case x::rest =>
val maxRest=maxListUpBound(rest)
if(x > maxRest) x
else maxRest
}
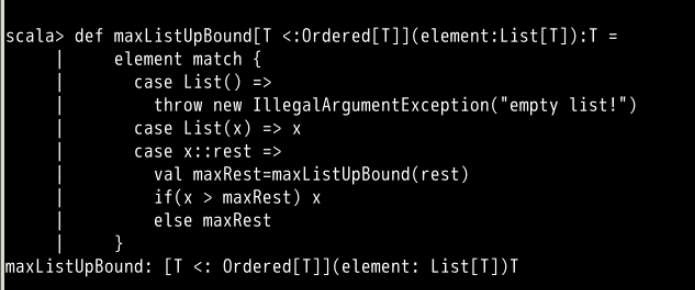
这个函数是求取一个顺序列表的最大值。但这个函数有个局限,它要求类型 T 是 Ordered[T] 的一个子类,因此这个函数无法求一个整数列表的最大值。
下面我们使用隐含参数来解决这个问题。我们可以再定义一个隐含参数,其类型为函数类型,可以把一个类型 T 转换成 Ordered[T] 。
def maxListImpParam[T](element:List[T])
(implicit orderer:T => Ordered[T]):T =
element match {
case List() =>
throw new IllegalArgumentException("empty list!")
case List(x) => x
case x::rest =>
val maxRest=maxListImpParam(rest)(orderer)
if(orderer(x) > maxRest) x
else maxRest
}
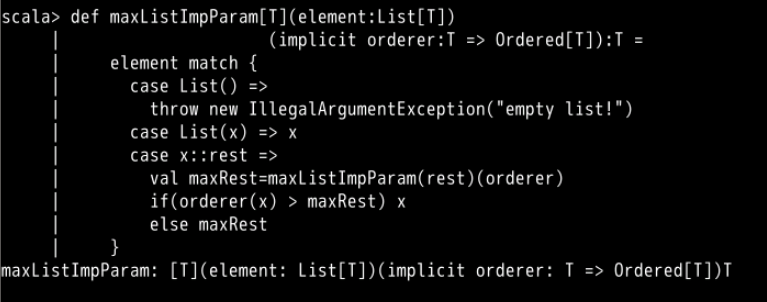
在这个函数中,隐含参数使用在两个地方:一个是在递归调用时传入;另一个是检查列表的表头是否大于列表其余部分的最大值。这个例子的隐含参数给前面定义的类型 T 补充了一些信息,也就是如何比较两个类型 T 对象。
这种用法非常普遍,以至于 Scala 的库缺省定义很多类型隐含的到 Ordered 类型的变换。例如我们调用这个函数:
scala> maxListImpParam(List(1,5,10,34,23))
res2: Int = 34
scala> maxListImpParam(List(3.4,5.6,23,1.2))
res3: Double = 23.0
scala> maxListImpParam(List("one","two","three"))
res4: String = two
在这几个调用中,编译器自动为函数添加了对应的 orderer 参数。
3.2 View 限定
先看看上一小节的这个例子:
def maxListImpParam[T](element:List[T])
(implicit orderer:T => Ordered[T]):T =
element match {
case List() =>
throw new IllegalArgumentException("empty list!")
case List(x) => x
case x::rest =>
val maxRest=maxListImpParam(rest)(orderer)
if(orderer(x) > maxRest) x
else maxRest
}
可以看到,其中函数体部分有机会使用 implicit ,却没有使用。要注意的是,当你在参数中使用 implicit 类型时,编译器不仅仅在需要时补充隐含参数,而且编译器也会把这个隐含参数作为一个当前作用域内可以使用的隐含变量使用。因此,在使用隐含参数的函数体内,可以省略掉 implicit 的调用而由编译器自动补上。
因此上述代码可以简化为:
def maxList[T](element:List[T])
(implicit orderer:T => Ordered[T]):T =
element match {
case List() =>
throw new IllegalArgumentException("empty list!")
case List(x) => x
case x::rest =>
val maxRest=maxList(rest)
if(x > maxRest) x
else maxRest
}
编译器在看到 x > maxRest 时,发现类型不匹配,但它不会马上停止编译。相反,它会检查是否有合适的隐含转换来修补代码。在本例中,它发现了 orderer 可用。因此编译器自动改写为 orderer(x)> maxRest 。
同理,我们在递归调用 maxList 时,省掉了第二个隐含参数,编译器也会自动补上。
同时我们可以发现,maxList 代码定义了隐含参数 orderer ,而在函数体中没有地方直接引用到该参数。因此,你可以任意改名 orderer ,比如下面几个函数定义是等价的:
def maxList[T](element:List[T])
(implicit orderer:T => Ordered[T]):T =
...
def maxList[T](element:List[T])
(implicit iceCream:T => Ordered[T]):T =
...
由于在 Scala 中,这种用法非常普遍,于是 Scala 专门定义了一种简化的写法—— View 限定。就像下面的例子,你可以尝试在 Shell 中输入它来验证一下:
def maxList[T <% Ordered[T]](element:List[T]) :T =
element match {
case List() =>
throw new IllegalArgumentException("empty list!")
case List(x) => x
case x::rest =>
val maxRest=maxList(rest)
if(x > maxRest) x
else maxRest
}
其中 <% 为 View 限定,也就是说,你可以使用任意类型的 T ,只要它可以看成类型 Ordered[T] 。这和 T 是 Orderer[T] 的子类不同,它不需要 T 和 Orderer[T] 之间存在继承关系。而如果类型 T 正好也是一个 Ordered[T] 类型,你也可以直接把 List[T] 传给 maxList 。此时,编译器使用一个恒等隐含变换:
implicit def identity[A](x:A): A =x
在这种情况下,该变换不做任何处理,直接返回传入的对象。
3.3 多个隐含转换的选择
有时在当前作用域,可能存在多个符合条件的隐含转换。在大多数情况下,Scala 编译器在此种情况下拒绝自动插入转换代码。隐含转换只有在转换非常明显的情况下工作良好,编译器只要例行公事地插入所需转换代码即可。如果当前作用域存在多个可选项,编译器不知道优先选择哪一个使用。
不妨在 Shell 中输入下列语句来测试一下:
scala> def printLength(seq:Seq[Int]) = println (seq.length)
printLength: (seq: Seq[Int])Unit
scala> implicit def intToRange(i:Int) = 1 to i
warning: there was one feature warning; re-run with -feature for details
intToRange: (i: Int)scala.collection.immutable.Range.Inclusive
scala> implicit def intToDigits(i:Int) = i.toString.toList.map( _.toInt)
warning: there was one feature warning; re-run with -feature for details
intToDigits: (i: Int)List[Int]
scala> printLength(12)
<console>:11: error: type mismatch;
found : Int(12)
required: Seq[Int]
Note that implicit conversions are not applicable because they are ambiguous:
both method intToRange of type (i: Int)scala.collection.immutable.Range.Inclusive
and method intToDigits of type (i: Int)List[Int]
are possible conversion functions from Int(12) to Seq[Int]
printLength(12)
这个例子产生的歧义是非常明显的,将一个整数转换成一组数字和转换成一个序列,明显是两个不同的变化。此时应该明确指明使用哪个变换,就像这样:
scala> intToDigits(12)
res1: List[Int] = List(49, 50)
scala> printLength(intToDigits(12))
2
scala> printLength(intToRange(12))
12
在 Scala 2.7 以前, Scala 编译器碰到多个可选项时都会这么处理。从 2.8 版本以后,这个规则不再这么严格。如果当前作用域内有多个可选项,Scala 编译器会优先选择类型更加明确的隐含转换。比如两个隐含变换,一个参数类型为 String,而另外一个类型为 Any 。两个隐含转换都可以作为备选项时,Scala 编译器优先选择参数类型为 String 的那个隐含转换。
“更明确”的一个判断规则如下:
- 参数的类型是另外一个类型的子类型
- 如果两个转换都是对象的方法,前对象是派生于另外一个对象。
Scala 做出这个改进的原因是为了更好地实现 Java 和 Scala 的集合类型(也包括字符串)之间的互操作性。
四、总结
我们应当注意:Scala 编译器会首先在方法调用处的当前范围内查找隐式转换函数;如果没有找到,会尝试在源类型或目标类型(包括源类型和目标类型的类型变量的类型)的伴随对象中查找转换函数,如果还是没找到,则拒绝编译。
另外,匿名函数也是不能声明隐式参数的,但你可以给匿名函数的参数加上 implicit ;如果一个函数带有 implicit 参数,则无法通过 _ 得到该函数引用。
本文由 liyunfei 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jun 24,2022