
一、介绍
内容
本课程侧重讲解 Scala 中的 Extractor ,它可以将数据模型和视图逻辑分离,在 Scala 体系中充当类似于适配器的角色,是一种极具函数式的做法。你将可以在课程中学到如何定义和设定 Extractor 。
知识点
- 分解 Email 地址
- 定义 Extractor
- 定义无参数和带一个参数的模式
- 可变参数的 Extractors
- Extractors 和 Seq 模式
- 正则表达式
环境
- Scala 2.11.8
- Xfce 终端
适合人群
本课程难度为一般,属于初级级别课程,适合具有 Scala 基础的用户。
二、开发准备
为了使用交互式 Scala 解释器,你可以在打开的终端中输入命令:
su -l hadoop
scala
当出现 scala> 开始的命令行提示符时,就说明你已经成功进入解释器了。如下图所示。
本实验的所有命令及语句均可在 Shell 中输入。
三、原理
分解 Email 地址的例子
到目前为止,构造器模式是和 Case Class 关联在一起的。有些时候你希望使用类似的模式而不需要创建 Case Class。
实际上,你可能希望创建自定义的模式。 Extractor(解析器)可以帮助你完成这些任务。
本实验以一个简单的例子来介绍Extractor的概念和用法。
比方说,给定一个代表了 Email 地址的字符串,你需要判断它是否是一个有效的 Email 地址。如果是有效的 Email 地址,你需要分别取出用户名和域名两个部分。传统的实现方法可以定义如下三个辅助函数:
def isEmail(s:String): Boolean
def domain(s:String): String
def user(s:String): String
使用这些方法,你可以使用如下代码分析输入的字符串:
if(isEmail(s)) println(user(s) + " AT " + domain(s))
else println("not an email address")
这段代码功能是正确的,但比较笨拙。并且,如果同时需要有多个测试时,情况就变得比较复杂:比如你要在一个字符串中,寻找相连的同一个用户名的 Email 地址。
我们之前介绍的模式匹配处理这类问题非常有效。简单说来,你可以使用如下的格式来匹配一个字符串:
Email(user,domain)
这个模式可以匹配含有“ @ ”的字符串,使用这个模式,你可以使用 user, domain 分别绑定用户名和域名。我们使用模式匹配重写前面的例子:
s match{
case Email(user,domain) => println (user + " AT " + domain)
case _ => println ("not an email address")
}
而如果要寻找相连的两个同名的 Email 地址,可以使用如下代码:
s match{
case Email(u1,d1)::Email(u2:d2):: _ if(u1==u2) => ...
...
}
这段代码看起来简单明了,但问题是 String(s的类型)不是一个 case class 。 它们不具有可以表示为 Email(user,domain) 的方法。 此时我们就可以借助于 Extractor ,它们支持为这些内置的类型定义新的模式。
四、步骤
4.1 定义 Extractor
在 Scala 中,Extractor 可理解为一个定义了 unapply 方法的对象。
unapply 的作用是匹配一个值,然后从中提取所需的部分。通常,unapply 和 apply 一起定义,但这不是必需的。例如,前面定义的那个 Email 对象。
它的定义如下:
object EMail {
def apply(user:String,domain:String) = user + "@" + domain
def unapply(str:String) :Option[(String,String)] ={
val parts = str split "@"
if(parts.length==2) Some(parts(0),parts(1)) else None
}
}
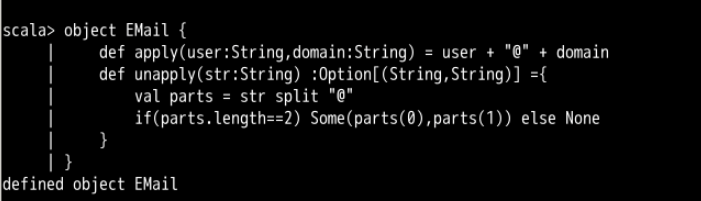
Email 对象定义了 apply 和 unapply 方法。apply 方法没有什么特别之处,而 unapply 方法则把 EMail 对象变成了一个 Extractor。在某种程度上来说, unapply 和 apply 的作用相反,apply 方法把两个字符串参数变成一个 Email 地址,而 unapply 方法反向变换,把一个字符串分解成两个部分:用户名和域名。
unapply 方法必须处理不能把一个字符串分解成两部分的情况,这也是为什么这里 unapply 方法返回 Option 类型的原因。
简单的测试如下,请尝试在 Shell 中 输入这些语句:
scala> EMail.unapply("james@guidebee.com")
res1: Option[(String, String)] = Some((james,guidebee.com))
scala> EMail.unapply("James Shen")
res2: Option[(String, String)] = None
现在,模式匹配遇到一个模式引用到一个 Exactor 对象的情况时,会调用该对象的 unapply 方法,比如:
selectorString match { case EMail(user,domain) => ...
这种情况下,可以调用:
EMail.unapply(selectorString)
例如:
"james.shen@guidebee.com" match{
case EMail(user,domain) => println (user +" AT " + domain)
case _ =>
}
james.shen AT guidebee.com
4.2 无参数和带一个参数的模式定义
前面例子中的 unapply 方法在匹配成功时,返回一个二元组。这可以很容易推广到多于两个变量的情况。为了绑定 N 个变量,unapply 方法可以返回一个 N 元祖,封装在 Some 中。
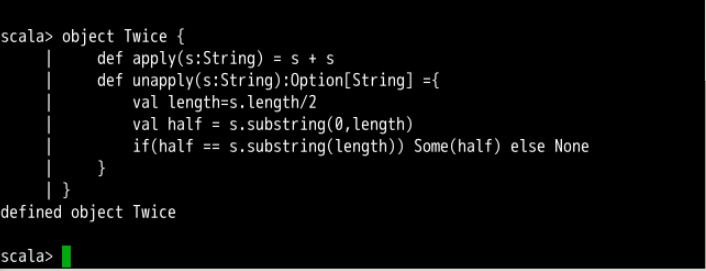
对于只绑定一个变量的情况来说,这有些特殊。Scala 没有所谓的“一元组”。为了返回一个变量,该变量直接封装在 Some 中返回。下面例子中的 Twice 匹配一个含有两个连续的相同字符串的情况。请尝试在 Shell 中定义它:
object Twice {
def apply(s:String) = s + s
def unapply(s:String):Option[String] ={
val length=s.length/2
val half = s.substring(0,length)
if(half == s.substring(length)) Some(half) else None
}
}
一个 Extractor 也可以绑定任何变量,这种情况下可以返回 true 或 false 代表匹配成功与否。比如下面的例子匹配一个字符串是否都是大写字母:
object UpperCase {
def unapply(s:String):Boolean = s.toUpperCase ==s
}

因为这里定义 apply 方法无任何意义,所以这个例子只定义了 unapply 方法。
之后我们可以利用上面定义的 Twice 和 UpperCase Extractor 组合构造组合的模式定义(还记得之前提到的 Monoid吗? 设计模式 Option 类型就是一个 Monoid ,Monoid 的一个特点就是可以任意组合)。这个定义如下:
def userTwiceUpper(s:String) = s match{
case EMail(Twice(x @ UpperCase()),domain) =>
"match:" + x + " in domain " + domain
case _ => "no match"
}
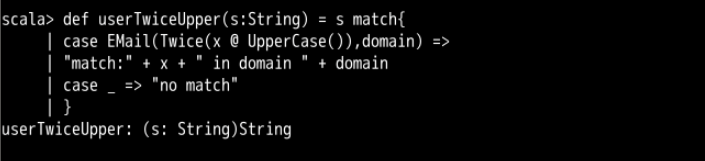
第一个模式定义去匹配所有的 Email 地址,这个 Email 地址的用户名为大写,并且有两个相同的字符串构成。例如:
scala> userTwiceUpper("DIDI@hotmail.com")
res1: String = match:DI in domain hotmail.com
scala> userTwiceUpper("DIDO@hotmail.com")
res2: String = no match
scala> userTwiceUpper("didi@hotmail.com")
res3: String = no match
在这个模式定义中,UpperCase 后面跟了一个空括号,这个空括号是必须的,否则模式变成匹配和 UpperCase 相等。即使 UpperCase 没有绑定任何变量,但你可以利用我们之前提到的“模式的种类”中的方法为这个模式绑定一个自定义的变量。这时使用“ @ ”来定义的。在本例为 x 。
4.3 可变参数的 Extractors
前面的几个例子中,Extractor 返回的结果数目都是固定的。比如 EMail 返回了两个结果:用户名和域名。有些时候,这显得有些不够灵活。比如你打算匹配一个域名,而返回的部分为域名的各个部分,你可能会写如下的模式:
dom match{
case Domain("org","acm") => print("acm.org")
case Domain("com","sun","java") => println("java.sun.com")
case Domain("net",_*) => println (" a .net domain")
}
这个例子的模式定义有很大的局限性,只能匹配 acm.org、 java.sun.com 和 *.net 域名。问题是我们如何实现可以匹配任意类型的域名,并分解出域名的各个部分。
针对这种变长类型的匹配,Scala 定义了一个 unapplySeq 方法来支持这种用法,例如:
object Domain{
def apply(parts:String *) :String = parts.reverse.mkString(".")
def unapplySeq(whole:String): Option[Seq[String]] =
Some(whole.split("\\.").reverse)
}
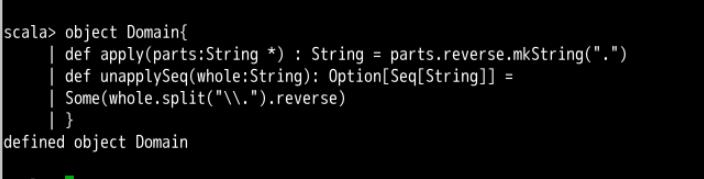
对象 Domain 定义了 unapplySeq 方法。首先以“ . ”分割字符串, Split 使用正规表达式(需要使用 \\ 转义)。 unapplySeq 结果返回一个封装在 Some 的 Seq 数据。
然后你可以使用 Domain Extractor 来获取 Email 地址更详细的信息。比如查找用户名为“ tom ”,域名为某些含“ com ”的地址。
def isTomDotCom(s:String):Boolean =s match{
case EMail("tom",Domain("com",_*)) => true
case _ => false
}
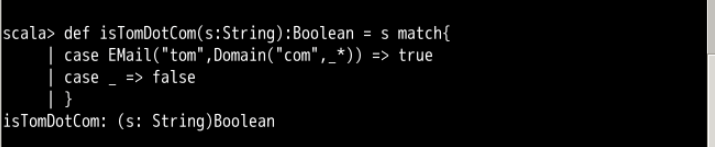
测试如下:
scala> isTomDotCom("tom@sun.com")
res0: Boolean = true
scala> isTomDotCom("peter@sun.com")
res1: Boolean = false
scala> isTomDotCom("tom@acm.org")
res2: Boolean = false
使用 unapplySeq 也支持返回一部分固定长度的变量加上后面变长的变量,这个返回值可以表示成一个多元组,可变的部分放在最后。比如:
object ExpendedEMail{
def unapplySeq(email: String)
:Option[(String,Seq[String])] ={
val parts = email split "@"
if(parts.length==2)
Some(parts(0),parts(1).split("\\.").reverse)
else
None
}
}
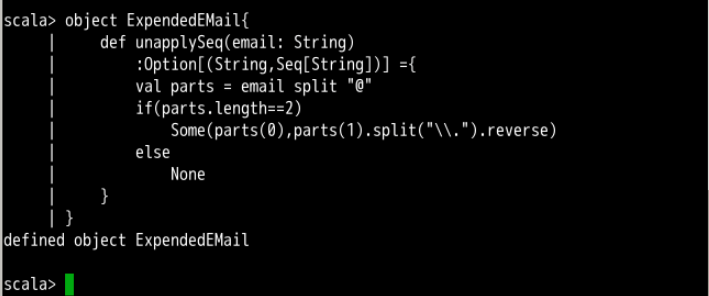
本例中的 unapplySeq 返回一个二元组,第一个元素为用户名,第二个元素为一个 Seq ,包含域名的所有部分。
scala> val s ="james.shen@mail.guidebee.com"
s: String = james.shen@mail.guidebee.com
scala> val ExpendedEMail(name,topdomain,subdoms @ _*) =s
name: String = james.shen
topdomain: String = com
subdoms: Seq[String] = WrappedArray(guidebee, mail)
4.4 Extractors 和 Seq 模式
我们在前面模式匹配中介绍了可以使用如下的方式访问列表的元素:
List()
List(x,y,_*)
Array(x,0,0,_)
实际上,这些序列模式内部实现都是使用 Extractor 来定义的。 比如下面的 Scala 标准库中对于 List 的定义:
package scala{
def apply[T](elems: T*) = elems.toList
def unapplySeq[T](x:List[T]): Option[Seq[T]] =Some(x)
...
}
4.5 正则表达式
Extractor 其中一个特别有用的应用是正则表达式。Scala 支持正规表达式,尤其是它在和 Extractor 配合使用时显得非常便利。
4.5.1 生成正则表达式
Scala 继承了 Java 的正则表达式的语法规则。这里我们假定你了解正则表达式。Scala 的正则表达式相关的类型定义在包scala.util.matching中。
创建一个正则表达式是使用 RegEx 类型,例如:
scala> import scala.util.matching.Regex
import scala.util.matching.Regex
scala> val Deciaml = new Regex("(-)?(\\d+)(\\.\\d*)?")
Deciaml: scala.util.matching.Regex = (-)?(\d+)(\.\d*)?
这里构建了一个可以识别数值的正则表达式。这个表达式中使用多个 \\ 转义。对于复杂的正则表达式来说,有时显得太复杂,很容易出错,Scala 允许你使用原始的正则表达式(无需转义),可以通过将正则表达式包含在 """ 字符串中的方式,比如重写上面的正则表达式如下:
val Deciaml = new Regex("""(-)?(\d+)(\.\d*)?""")
此外还有一个更简洁的方法,是在字符串后使用 .r 操作符,例如:
scala> val Deciaml = """(-)?(\d+)(\.\d*)?""".r
Deciaml: scala.util.matching.Regex = (-)?(\d+)(\.\d*)?
.r 为 StringOps 的方法,它把一个字符串转换为 Regex 对象。
4.5.2 使用正则表达式查找字符串
Scala 支持下面几种正则表达式的查找方法:
regex findFirstIn Str:查找第一个匹配的字符串,返回Option类型。regex findAllIn str:查找所有匹配的字符串,返回Interator类型。regex findPrefixOf str:从字符串开头检查是否匹配正则表达式,返回Option类型。
例如:
scala> val Decimal = """(-)?(\d+)(\.\d*)?""".r
Decimal: scala.util.matching.Regex = (-)?(\d+)(\.\d*)?
scala> val input = " for -1.0 to 99 by 3"
input: String = " for -1.0 to 99 by 3"
scala> for(s <- Decimal findAllIn input) println(s)
-1.0
99
3
scala> Decimal findFirstIn input
res5: Option[String] = Some(-1.0)
scala> Decimal findPrefixOf input
res6: Option[String] = None
4.5.3 使用正则表达式分解数据
Scala 所有的正则表达式都定义了一个 Extractor,可以用来解析正规表达式中对应的分组。比如前面定义的 Decimal 定义了三个分组,可以直接用来解析一个浮点数:
scala> val Decimal(sign,integerpart,decimalpart) = "-1.23"
sign: String = -
integerpart: String = 1
decimalpart: String = .23
如果对应的分组查找不到,则返回 Null。比如:
scala> val Decimal(sign,integerpart,decimalpart) = "1.0"
sign: String = null
integerpart: String = 1
decimalpart: String = .0
这种分解方法同样可以应用到 for 表达式中,例如:
for(Decimal(s,i,d) <- Decimal findAllIn input)
println ("sign: " +s + ",integer:" +
i + ",deciaml:" +d)
sign: -,integer:1,deciaml:.0
sign: null,integer:99,deciaml:null
sign: null,integer:3,deciaml:null
本文由 liyunfei 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jun 24,2022