
1 什么是人工智能
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。
人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。人工智能可以对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、也可能超过人的智能。
约翰·麦卡锡给出的定义:
- 构建智能机器,特别是智能计算机程序的科学和工程。
- 人工智能是一种让计算机程序能够“智能的”思考的方式。
- 思考的模式类似于人类。
智能和智力是有区别的:智能包含智力,智力表现计算能力(聪明程度)
人工智能研究方向:
- 计算机视觉
- 自然语言处理
- 数据挖掘分析
- 综合应用
无人驾驶
机器人
行业AI赋能(量化)
1.1 怎么样算有智能呢?
- 可以根据环境变化而做出相应变化的能力。
- 具有“存活”的最基本动因(求生欲)。
- 自主能力,自我意识,等等。
1.2 图灵测试
图灵在1950年提出了一个关于判断机器是否足够智能的著名实验(turing test)

图灵测试(The Turing test)由艾伦·麦席森·图灵发明,指测试者与被测试者(一个人和一台机器)隔开的情况下,通过一些装置(如键盘)向被测试者随意提问。
进行多次测试后,如果机器让平均每个参与者做出超过30%的误判,那么这台机器就通过了测试,并被认为具有人类智能。图灵测试一词来源于计算机科学和密码学的先驱艾伦·麦席森·图灵写于1950年的一篇论文《计算机器与智能》,其中30%是图灵对2000年时的机器思考能力的一个预测,目前我们已远远落后于这个预测。
1.3 需要的基础
最基本的是数学,微分积分、高等代数、统计学、概率论等等,甚至还需要有社会科学,心理学等等。
1.4 人工智能简史
-
1943年人工神经网络概念被提出,Artificial Neural Network,神经网络计算模型出现。
-
1956年约翰·麦卡锡 发起达特茅斯会议(定义AI,Artificial Intelligence) ,标志AI正式诞生。
-
1957年提出感知器,一种最简单的人工神经网络,是生物神经网络机制的简单抽象,将人工智能推向第一个高峰。




1970年后的十几年人工智能第一个寒冬,传统感知器耗费的计算量和神经元数目的平方成正比,当时的计算机计算能力远达不到这个水平。
1982年提出霍普菲尔德神经网络,一种递归神经网络(根据回执反复计算),具有反馈机制(feed back)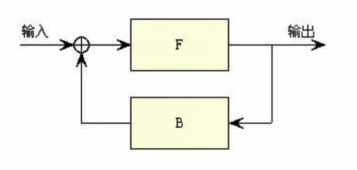
1974年提出反向传播(back propagation)算法,没有收到重视。
1986年重新提出完整算法(BP算法)使大规模神经网络训练成为可能,将人工智能推向第二个高峰。
1990年开始人工智能第二个寒冬,美国政府因为Darpa项目失败,缩减投入。
2006年提出深度学习(deep learning)指多层神经网络。同时进入感知智能时代(语音和图像识别)
人工智能时代划分:
运算智能、感知智能、认知智能
2016年AlphaGo又一次掀起人工智能浪潮Google收购DeepMind公司的AlphaGo(基于TensorFlow)
人工智能知识图谱:
2 什么是机器学习
机器学习是实现人工智能的一种方法,深度学习是机器学习的一个分支

2.1 什么是学习?
学习是一个过程:一个系统,通过执行某一个程序,改善其性能的动作。
学习的目的是“减熵”(熵:混乱程度,热力学第二定律:一个独立系统,倾向于自动增加熵)
2.2 机器学习的必要性
解决人工编程无法完成的任务。比如图像识别,自动驾驶等等。
人有状态好坏的差别,机器没有,不用容易犯错。
机器计算能力在某些维度远大于人类。
2.3 机器学习的概念
对某类任务T(Task)和性能P(Performance)通过经验E(Experience)改进后,在T上由性能度量P衡量的性能有所提升。

2.4 传统编程和机器学习的区别

训练猫握手,发出指令,对了给奖励,错了没有奖励。通过数据和结果希望猫学习到握手这个程序。
机器学习的目的就是通过数据和结果找到一个好的函数(function)
2.5 机器学习的分类
监督学习(分类,带标签)
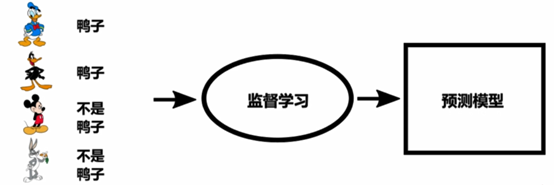
非监督学习(聚类,没有标签)

半监督学习(聚类,部分带标签)
强化学习(基于奖励推动学习)
2.6 机器学习相关算法

2.7 机器学习算法选型
分为四大类:分类,聚类,回归,降维
首先判断样本数量,大于50继续,不足需要收集更多数据
然后判断数据是否有类别,有类别备选分类和聚类,否则备选回归和降维
如果有类别,判断是否有标签,有标签分类,无标签聚类
没有类别时,判断是否需要预测数值,是回归,否降维

机器学习词汇
节点
predicting a category:预测类别
predicting a quantity:预测数值
labeled data:是否数据打过标签
回归
SGD Regressor:随机梯度下降回归
Lasso/ElasticNet Lasso:弹性网络 回归
SVR (kernel=‘linear’):支持向量机回归使用线性函数作为核函数
SVR (kernel=‘rbf’):支持向量机回归使用径向基函数
RidgeRegressor:岭回归
分类
Linear SVC:线性支持向量机分类
Navie Bayes:朴素贝叶斯
KNeighbors Classifier:K近邻分类器
SVC:支持向量机分类器
SGD Classifier:随机梯度下降分类器
kernel approximation:核近似方法
聚类
MiniBatch KMeans:最小族(束)KMeans
KMeans:传统KMeans
Spectral Clustering:谱聚类
GMM:混合高斯模型
VBGMM:VB混合高斯模型
2.8 机器学习步骤
- 收集数据
- 准备数据
- 选择/建立模型
- 训练模型
- 测试模型(如成功则在此停止)
- 调节参数
关键点:建模、评估、调优
2.9 其他概念
2.9.1 过拟合
欠拟合Underfitting
拟合完美fitting right
过拟合overfitting
回归中的体现

分类中的体现

2.9.2 解决过拟合的方法
降低数据量,减少不必要的数据降低拟合度。
正则化(代数几何),约束经验误差函数,引导函数向误差减小方向。
Dropout,训练时随机去除某些神经元,测试时使用全部神经元,达到泛化模型,防止过拟合。

3 什么是深度学习
3.1 概念
简而言之就是基于深度(多层隐藏层)神经网络的学习。


3.2 使用深度学习的必要条件
大量数据:图中看到数据量越大,效果越好
强计算力:强的计算力能使不可能变为可能,CPU、GPU、TPU、云计算
复杂模型:隐藏层越多效果越好
3.3 深度学习的过程总结
正向传播—计算误差(loss)—反向传播(BP)—调整权重(weight)
除了调参(权重)以外还有dropout
本文由 liyunfei 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jun 24,2022