
技术介绍及其在项目中的运用
Spark 实时电商数据分析可视化系统是一个经典的大数据应用项目,技术栈主要有 Flume、Kafka、Spark Streaming、Flask 等,帮助大家了解和运用一些当前热门的大数据处理组件来亲自动手搭建一套大数据处理平台框架和熟悉大数据项目的基础开发流程。
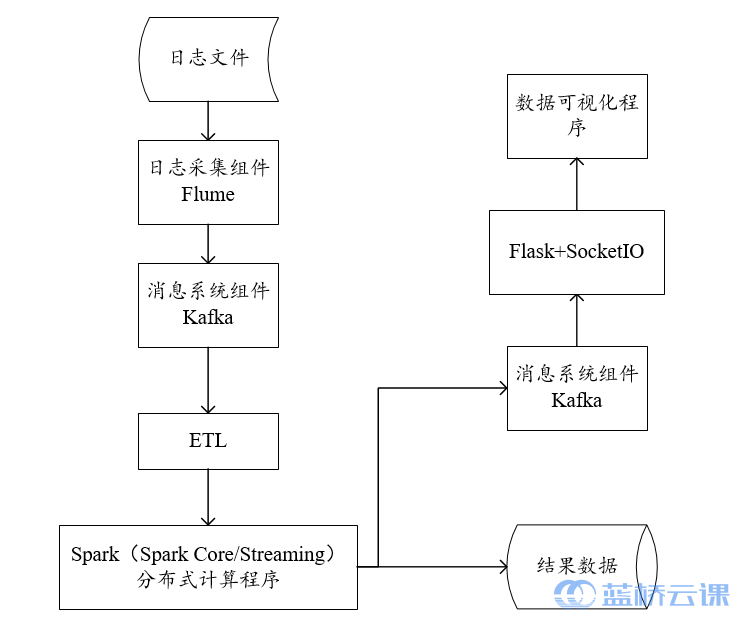
本项目选取了当前主流的大数据组件,实现一套完整的大数据处理平台项目,包括了数据采集与传输、数据处理和数据可视化三大部分,通过对每个模块部分的技术讲解和应用对一些功能需求进行实现。项目整体流程可参考下图。
Zookeeper 简介
为分布式应用提供支持的一种协调分布式服务,项目中主要用于管理 Kafka。除此之外还可提供统一配置管理、域名集中访问、分布式锁和集群管理等服务。
Flume 简介
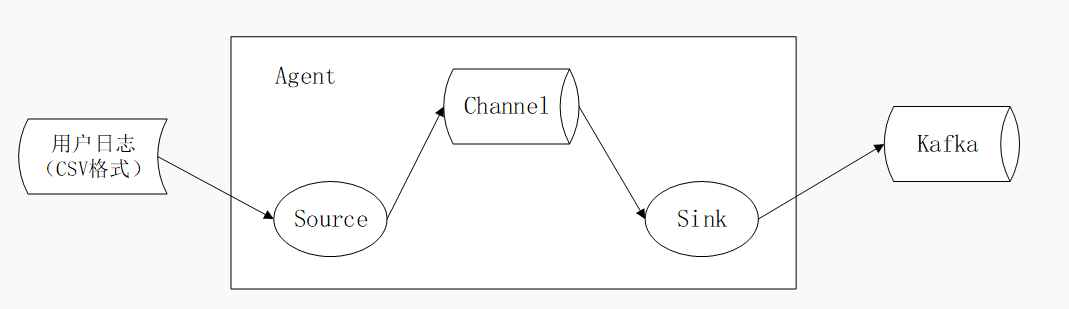
一种日志采集系统,具备高可用、高可靠和分布式等优点,可定制各类数据发送方,用于数据的收集;传输过程中,可对数据进行简单处理,并可定制数据接收方,具备事务性,只有当数据被消费之后才会被移除,项目中接收方定制为 Kafka。
在使用 Flume 的时候,可编写自定义的过滤器进行初次的数据清洗,减少后期 ETL 的压力,但是此项目用的数据集较为简单,仅需后期简单清洗即可,如果对这方面感兴趣的同学们可以去自行学习后,将过滤器加进此项目中测试。
Kafka 简介
一种高性能分布式消息队列系统组件,具有数据持久化、多副本备份、横向扩展和处理数据量大等特点。Kafka 需要部署于 Zookeeper 同步服务上,用于实时流式数据分析。项目中用作存放 Flume 采集的数据。Kafka 中也存在拦截器机制,可对传入的消息进行拦截和修改。
Flume 与 Kafka 结合使用的好处
- 实际项目开发中,由于数据源的多样性和数据的复杂性,如采用构建多个 Kafka 生产者、通过文件流的方式向主题写入数据再供消费者消费的话,很不方便。
- 进行实时数据处理时,由于 Flume 的数据采集速度过快,数据处理过慢时,可能会发生数据的堆积或者丢失,此时可把 Kafka 当做一个消息缓存队列,用于存放一段时间的数据。
- Kafka 属于中间件,可降低项目耦合性,使某模块出错时不会干扰其它组件。
源数据
源数据为用户行为日志数据集中截取的 10w 条记录,日志字段定义如下表所示:
| 字段名 | 说明 |
|---|---|
| userId | 用户 id |
| goodsId | 商品 id |
| catId | 商品类别 id |
| sellerId | 卖家 id |
| brandId | 品牌 id |
| month | 交易月份 |
| date | 交易日期 |
| action | 用户操作行为:{0:点击, 1:加入购物车, 2:购买, 3:关注} |
| ageLevel | 客户年龄段:{1:age<18, 2:18~24, 3:25~29, 4:30~34, 5:35~39, 6:40~49, 7 和 8: age>=50, 0 和 NULL:未知} |
| gender | 性别:{0:女, 1:男, 2 和 NULL:未知} |
| province | 省份 |
下载 test.csv 测试数据,考虑到运行环境内存,数据量不是很大,如果使用自己机器进行实现,可以去网络上找一份比较大数据量的数据集。
cd /home/shiyanlou/Desktop
# 测试数据拉取
wget https://labfile.oss.aliyuncs.com/courses/2629/test.csv
数据具体格式如下图所示,字段排列顺序按上表。

预期成果
结合提供的 Spark 开发环境,开启 Flume 采集端后,Kafka 的控制台消费者能够不断的消费 Topic 中的数据,在命令窗口中进行显示。
Flume 与 Kafka 的整合
启动 Zookeeper、Kafka
启动 Zookeeper,启动成功出现下图所示 zookeeper 已启动的提示信息。使用默认的配置文件启动后,端口默认为本地 2181 端口。
zkServer.sh start

Zookeeper 启动后,再启动 Kafka,启动成功出现下图所示 KafkaServer 已启动的提示信息。启动端口默认为 9092 端口。
kafka-server-start.sh /opt/kafka_2.11-1.0.0/config/server.properties

启动 Kafka 之后,新打开一个标签或终端,执行下面的操作。
在 Kafka 中创建项目所需的各个 Topic
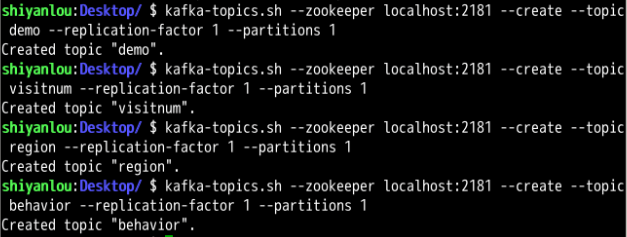
由于实验环境限制,下述所有 Topic 的副本数和分区数都定为 1。如果分区数大于 1,在后期使用 Sparkstreaming 处理阶段需要进行 union 操作。
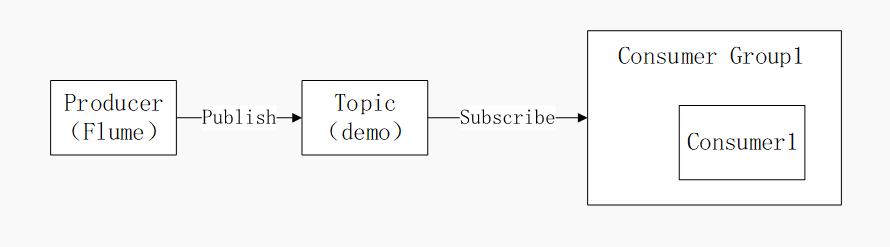
创建 demo 主题,用于接收 Flume 采集过来的用户行为日志信息。
kafka-topics.sh --zookeeper localhost:2181 --create --topic demo --replication-factor 1 --partitions 1
创建 visitnum 主题,用于接收 SparkStreaming 处理之后回传给 Kafka 的总访问量。后期的可视化模块可直接对此 Topic 进行数据获取消费,结合页面标签进行实时访问量的展示。
kafka-topics.sh --zookeeper localhost:2181 --create --topic visitnum --replication-factor 1 --partitions 1
创建 region 主题,用于接收 SparkStreaming 处理之后回传给 Kafka 的各省份总订单量。后期的可视化模块可直接对此 Topic 进行数据获取消费,结合 Echarts 进行各地区实时购买量的展示。
kafka-topics.sh --zookeeper localhost:2181 --create --topic region --replication-factor 1 --partitions 1
创建 behavior 主题,用于接收 SparkStreaming 处理之后回传给 Kafka 的用户各类操作行为次数。后期的可视化模块可直接对此 Topic 进行数据获取消费,结合 Echarts 进行用户行为操作实时统计的展示。
kafka-topics.sh --zookeeper localhost:2181 --create --topic hehavior --replication-factor 1 --partitions 1
以上四个主题创建成功的提示信息。
编写 Flume 作为 Kafka 数据源的配置文件
编写 kafkaSink.flm 连接配置文件,用于配置 Flume 作为 Kafka 的数据源,放于桌面。在文件中主要是定义了 source、channel 和 sink,定义服务名 a1,source 定义类型为 avro,端口号为 4141;channel 定义数据缓存类型为内存,提升数据传输速度;sink 类型定义为 KafkaSink,配置好 broker 的信息和目标 topic 即可。
# 定义一个服务名称为 a1,source,channel,sink 分别为 r1, c1, k1
a1.sources=r1
a1.channels=c1
a1.sinks=k1
# 定义 source,数据格式为 avro,监听端口号为本机的 4141 端口
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=4141
# 定义 channel,类型为内存
a1.channels.c1.type=memory
# 定义 sink,k1 的输出类型为 Kafka
# 此处仅为 Kafka1.0.0 版本配置内容,新版 kafka 配置内容有所修改
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList=localhost:9092
a1.sinks.k1.topic=demo
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
使用编写好的 kafkaSink.flm 文件启动 Flume,命令中的服务名为 a1,需要与 flm 文件中一致。当启动成功后,会出现如下图所示的信息提示。
flume-ng agent -f /home/shiyanlou/Desktop/kafkaSink.flm -n a1 -c /opt/apache-flume1.6.0-bin/conf
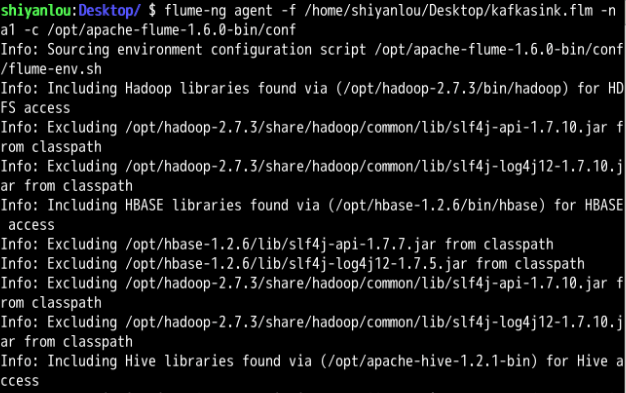
Flume 启动完成后,新打开一个标签或终端,执行下面的操作。
数据消费
创建 kakfaConsumer 消费 demo 中的数据,用于判断 Flume 与 Kafka 之间是否连通。创建好 Kakfa 的控制台消费者之后,会出现如下图所示的命令窗口显示,等待数据进入 demo 主题进行消费。
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic demo
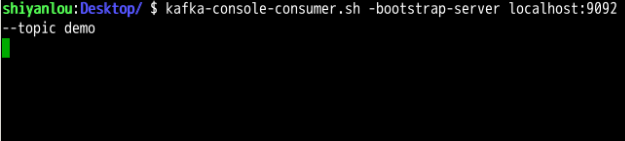
现在打开新终端,开始数据采集。
启动 Flume 向 avor-client 发送采集数据,采集目标文件为用户行为日志源文件。启动成功后,会通过内置的传输端口进行数据采集推送,如下图所示。
flume-ng avro-client -H localhost -p 4141 -F /home/shiyanlou/Desktop/test.csv

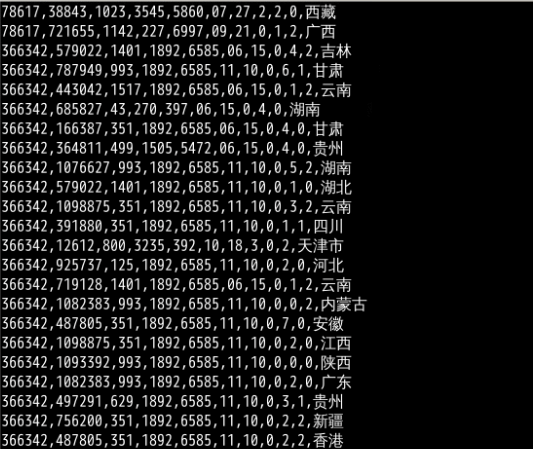
测试结果
数据消费中创建的 kafkaConsumer 的控制台窗口中的显示,数据格式与源数据一致。
本文由 liyunfei 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jun 24,2022