
技术介绍及其在项目中的运用
SparkStreaming 简介
SparkStreaming 是基于 Spark 核心 API 的拓展,用于实时数据流的处理,具有低延迟、高吞吐和基于内存计算等特点。通过设置的批处理时间间隔生成的一批 RDD 来生成 Dstream,用于进行数据的处理。项目中使用 Kafka 当做 SparkStreaming 的数据来源。

Spark-shell 简介
Spark-shell 可以直接通过命令窗口学习 API,使用 Scala 或者 Python 语言编写数据处理分析逻辑代码进行交互式学习。实际是通过后台调用 Spark-submit 脚本来提交应用程序。项目中主要使用 Scala 语言在 Spark-shell 中进行逻辑代码编写。
预期成果
在 Sparkstreming 程序运行窗口中,对从 kafka 的 demo 主题中获取到的数据按 3 秒一次的刷新时间进行数据展示。

环境说明
本系统使用 Scala 版本为 2.11、Spark 版本为 2.4.4(Scala2.11 编写版)、Kafka 1.0.0。
通过查看提供的虚拟环境,各组件版本都符合要求。Kafka 可以使用高版本,但是不可以使用低版本,因为 Spark 2.4.4 与 Kafka 的连接组件,不支持 Kafka 1.0.0 以下版本。其它组件如果使用过高或者过低的版本极有可能出现不兼容的问题,所以尽量保持一致。
SparkStreaming 程序编写
Kafka 启动
需要先将 Zookeeper 与 Kafka 启动,因为 SparkStreaming 需要对 Kafka 进行对接。Flume 可以等 SparkStreaming 程序启动后再开始进行数据采集。参考上次实验,启动命令如下:
$ zkServer.sh start
$ kafka-server-start.sh /opt/kafka_2.11-1.0.0/config/server.properties
修改 Spark-shell 启动默认配置
由于项目中的数据来源为 Kafka,需要对获取的数据进行序列化。序列化方式是通过配置 SparkConf 对象来实现的,而 Spark-shell 在启动时已经默认创建好 sc 对象,所以无法通过传递 SparkConf 对象构建 sc 对象。
因此需要修改 Spark 文件夹中 conf 目录下的 spark-defaults.conf 文件,配置启动时默认使用的序列化方式。因为 conf 目录下只有 spark-defaults.conf.template 文件,所以需要复制模板文件再进行修改。
复制配置模板,创建 spark-default.conf 文件。
cp /opt/spark-2.4.4-bin-hadoop2.7/conf/spark-defaults.conf.template /opt/spark-2.4.4-bin-hadoop2.7/conf/spark-defaults.conf
修改 spark-default.conf 文件。
vim /opt/spark-2.4.4-bin-hadoop2.7/conf/spark-defaults.conf
将 spark-default.conf 文件第 25 行中的注释符号去除,即可设置启动时默认使用 Kryo 的序列化方式。Kryo 具有序列化速度快、易编码和易用性等优点。
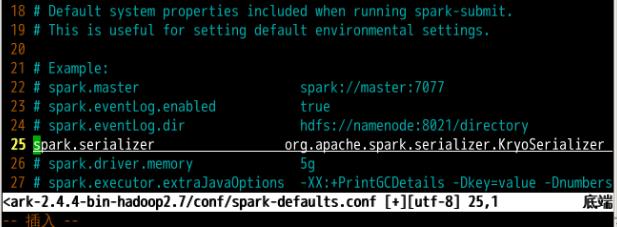
引入连接 Kafka 所需的 jar 包
下载 spark-streaming-kafka-0-10_2.11-2.4.4.jar 和 kafka-clients-2.0.0.jar 两个 jar 包,放到 /opt/spark-2.4.4-bin-hadoop2.7/jars 目录下,用于连接和操作 Kafka。
cd /home/shiyanlou/Desktop
# 从课程资源中将 spark-streaming-kafka 拉到桌面上
wget https://labfile.oss.aliyuncs.com/courses/2629/spark-streaming-kafka-0-10_2.11-2.4.4.jar
# 从课程资源中将 kafka-clients 拉到桌面上
wget https://labfile.oss.aliyuncs.com/courses/2629/kafka-clients-2.0.0.jar
# 移动目录
cp spark-streaming-kafka-0-10_2.11-2.4.4.jar kafka-clients-2.0.0.jar /opt/spark-2.4.4-bin-hadoop2.7/jars
通过 Spark-shell 创建 SparkStreaming 程序
启动 Spark-shell,下述操作都在此终端完成即可。
创建用户日志信息样例类,代码如下所示,学员们自己编写代码时可以省去注释部分。
case class UserBehavior(
user_id: String, //买家 id
item_id: String, //商品 id
cat_id: String, //商品类别 id
merchant_id: String, //卖家 id
brand_id: String, //品牌 id
month: String, //月份
day: String, //天数
act: String, //行为,取值范围 {0,1,2,3},0 表示点击,1 表示加入购物车,2 表示购买,3 表示关注商品
age_range: String, //买家年龄分段:1 表示年龄 <18,2 表示年龄在[18,24],3 表示年龄在 [25,29],4 表示年龄在 [30,34],5 表示年龄在 [35,39],6 表示年龄在 [40,49],7 和 8 表示年龄 >=50,0 和 NULL 则表示未知
gender: String, //性别:0 表示女性,1 表示男性,2 和 NULL 表示未知
province: String //收货地址省份
)
Spark-shell 中用户日志信息类创建成功效果如下图所示。
注意:在 Spark-shell 中进行多行输入时候尽量使用 paste 命令,以便于代码块整体运行。使用方法为输入 :paste 开启粘贴模式,可以选择粘贴或者手动编写代码块,完成后按 Crtl+D 退出粘贴模式,代码块自动运行。
导入程序中所要使用的拓展类包。
//Java 工具配置类
import java.util.Properties
//Spark 广播类(在数据处理二中需用到)
import org.apache.spark.broadcast.Broadcast
//SparkContext 类
import org.apache.spark.SparkContext
//连接 Kafka 所需的序列化类
import org.apache.kafka.common.serialization.{StringDeserializer, StringSerializer}
//log4j
import org.apache.log4j.{Level, Logger}
//SparkConf
import org.apache.spark.SparkConf
//Kafka 主题订阅
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
//kafka 工具类(0.8 和 0.10 版本不同,此处为 0.10 版本的工具类导入)
import org.apache.spark.streaming.kafka010.KafkaUtils
//分区方式
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
//StreamingContext
import org.apache.spark.streaming.{Seconds, StreamingContext}
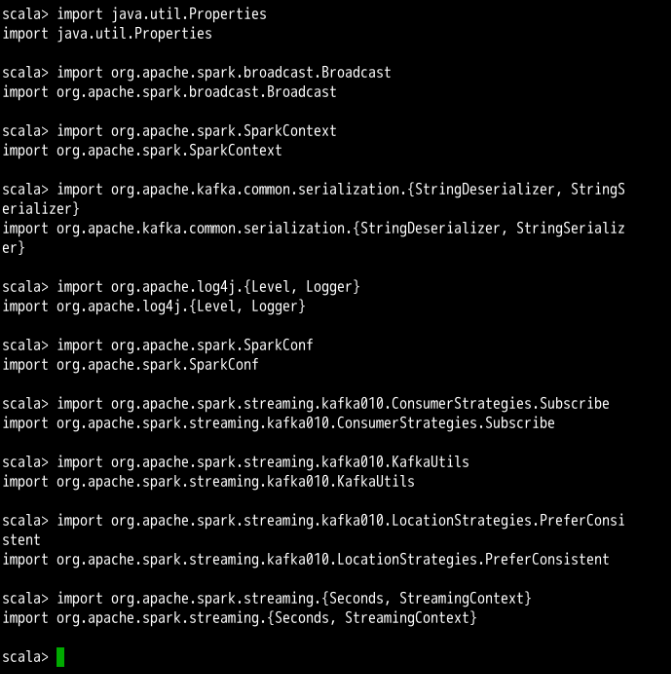
Spark-shell 中导入成功后每行下方都会出现导入成功提示,学员自己操作时可省略注释。效果如下图所示。
创建 StreamingContext 对象,我们可以把检查点 checkpoint 设立在本地文件夹中,也可设立在 Hadoop 集群中。
先打开一个终端创建用于存放检查点的本地文件夹,并配置好权限。
递归创建检查点文件夹。
sudo mkdir -p /bigdata/spark/checkpoint
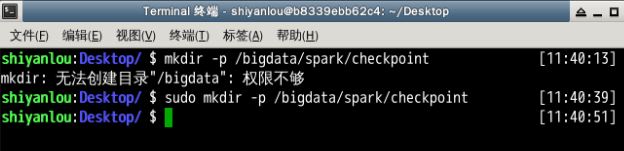
配置检查点文件夹及父目录的权限,用于程序中检查点的数据存放。
sudo chmod -R 777 /bigdata
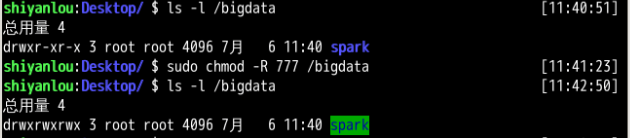
通过使用详细信息查询命令,可以看到相关目录权限已经改变。当然,直接设置权限为 777 在实际开发中是不规范的,此处只是为了项目中创建目录方便。
如果出现下图的创建错误提示信息,说明层级目录中某些目录权限不够。
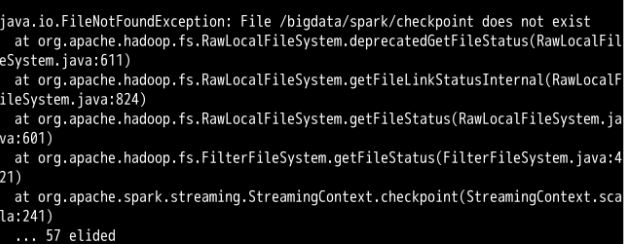
创建 StreamingContext 对象代码。
val ssc = new StreamingContext(sc,Seconds(3))
//设置数据检查点
//需要赋予 bigdata 以下所有目录权限,否则会因权限不足无法创建 checkpoint 文件夹
ssc.checkpoint("/bigdata/spark/checkpoint")
//kafka 中创建 demo 主题,用于存放 flume 采集发送过来的源数据
val topics = Set("demo")
val kafkaParams = Map[String, Object](
//配置 kafka 节点
"bootstrap.servers" -> "localhost:9092",
//设置 key 的序列化方式为 StringDeserializer
"key.deserializer" -> classOf[StringDeserializer],
////设置 value 的序列化方式为 StringDeserializer
"value.deserializer" -> classOf[StringDeserializer],
//设置消费组
//一个消费组中可以有多个消费者,所订阅的主题中的消息会被多个消费者分享
//所以在运行此程序前,该消费组中不可有其他的消费者在进行消费
//避免造成消费数据不完整
"group.id" -> "g1",
//偏移量设置为最新
"auto.offset.reset" -> "latest",
//关闭任务自动提交
"enable.auto.commit" -> (false: java.lang.Boolean)
)
Spark-shell 中创建 StreamingContext 对象成功后,代码块下面会显示相关信息,包括 StreamingContext 对象信息,连接的 Kafka 主题信息,Kafka 中各个参数的详细信息,效果如下图所示。
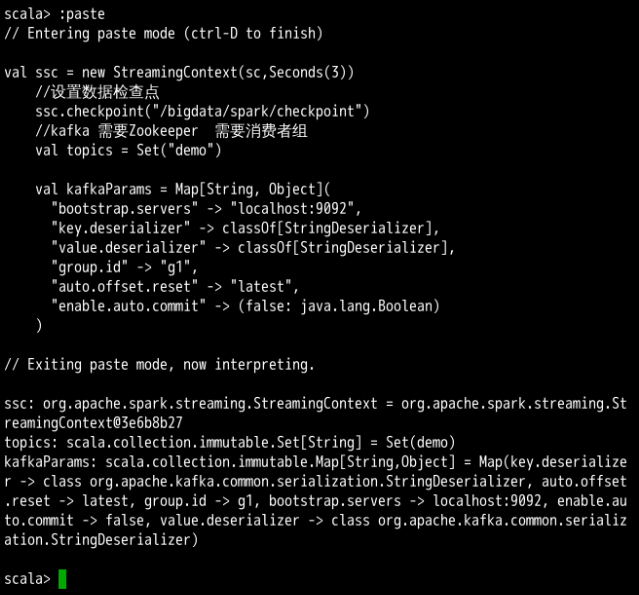
创建 Kafka 数据源的 Dstream。
目前,创建连接 Kafka 数据源的 Dstream 有两种方式,分别为 createDstream 和 createDirectDstream,一般来说第二种常用于开发中,两者的区别在各类文章中都有提及,学员们可自行学习。
由于此项目中 SparkStreaming 与 Kafka 的集成使用了 0.10 版本,而在 0.8 之后的版本,第一种创建 Dstream 的方式已经被弃用了,所以只能使用第二种 direct 创建模式。
//以 direct 模式创建 kafka 数据源的 Dstream
val data = KafkaUtils.createDirectStream(
//StreamingContext 对象
ssc,
//采用一致性方式,将分区大致均匀分配到所有 Executor 上去
PreferConsistent,
//配置 kafka 参数,订阅对应的 demo 主题
Subscribe[String, String](topics, kafkaParams))
Spark-shell 中创建 Dstream 后,会出现 DirectKafkaInputstream 的提示消息,说明已经创建好与 Kafka 的连接,同时会出现一些警告,这个可以先不用处理,不会影响后期项目运行,效果如下图所示。
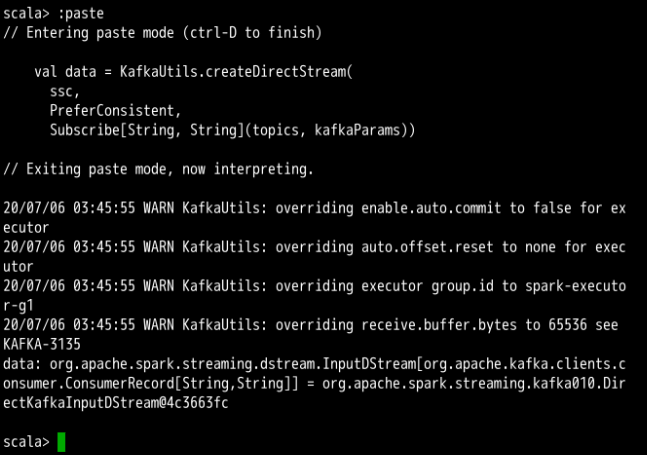
数据预处理,需要先将数据流进行简单的 map,将流中对象的值都取出。之后需要将原数据中某些字段进行判断赋值,以便于后期数据处理,如性别和年龄段字段,需要提前去除空值,以防出现异常。同时将得到的数据都封装为一个个的用户日志信息类的对象,形成一个个有机的整体,方便取值。
val result = data.map(_.value()).map(
line=>{
val record=line.split(",")
//年龄段字段为 0 或者 null,统一重新赋值为 9,方便过滤
if(record(8).equals("0")||record(8)==null)record(8)="9"
//性别字段为 2 或者 null,统一重新赋值为 3,方便过滤
if(record(9).equals("2")||record(9)==null)record(9)="3"
UserBehavior(
record(0), //买家 id
record(1), //商品 id
record(2), //商品类别 id
record(3), //卖家 id
record(4), //品牌 id
record(5), //月份
record(6), //日数
record(7), //行为
record(8), //年龄段
record(9), //性别
record(10) //省份
)
})
Spark-shell 中数据预处理完成后,信息提示已经转化为 UserBehavior 的 Dstream,效果如下图所示。
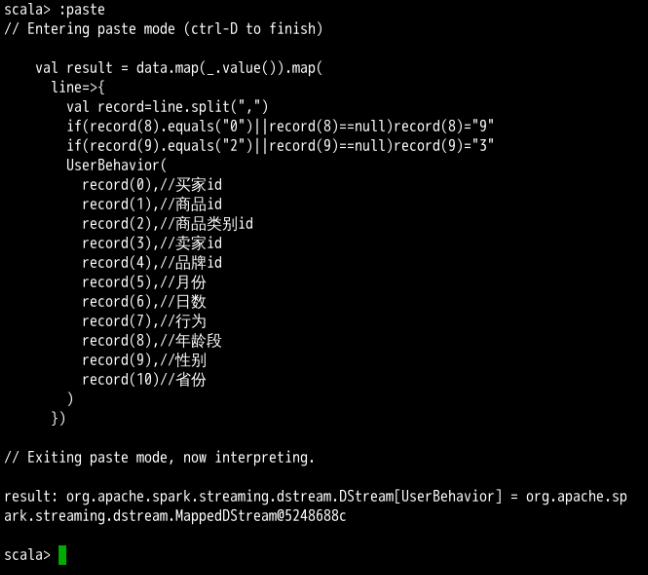
对以上获取到的所有用户日志信息在命令窗口中进行打印。
val test=result.print()

启动 SparkStreaming 程序。
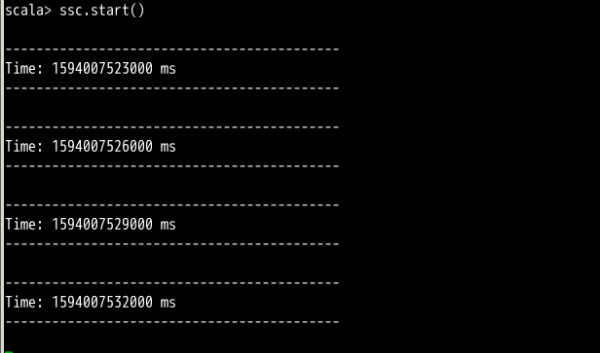
ssc.start()
Spark-shell 中 SparkStreaming 程序启动后,每隔三秒便会在命令窗打印一次信息,由于当前未有数据传入 Kafka,所以一直没有内容显示,效果如下图所示。
启动 Flume 开始进行数据采集。参考上次实验,启动命令如下:
$ flume-ng agent -f /home/shiyanlou/Desktop/kafkaSink.flm -n a1 -c /opt/apache-flume1.6.0-bin/conf
$ flume-ng avro-client -H localhost -p 4141 -F /home/shiyanlou/Desktop/test.csv
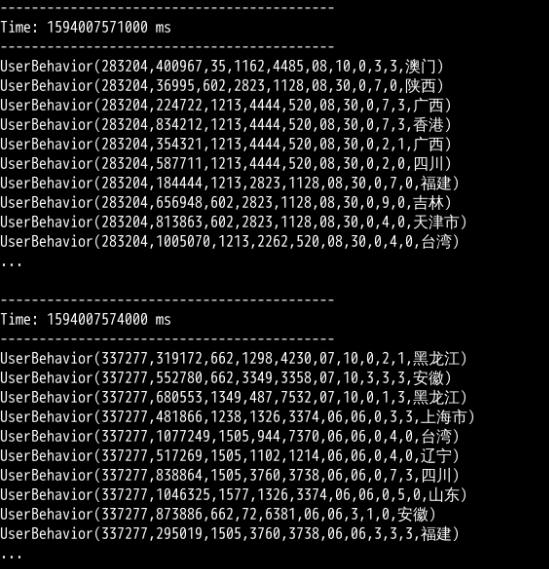
测试结果
启动完成的 SparkStreaming 程序,每隔 3 秒从 Kafka 的 demo 主题中获取一遍数据进行消费,并实时刷新打印在命令窗口中。获取的数据都以 UserBehavior 对象的形式进行打印。
spark-shell 完整代码
下面列出在 spark-shell 中执行的完整代码,供大家参考对比:
case class UserBehavior(
user_id: String, //买家 id
item_id: String, //商品 id
cat_id: String, //商品类别 id
merchant_id: String, //卖家 id
brand_id: String, //品牌 id
month: String, //月份
day: String, //天数
act: String, //行为,取值范围 {0,1,2,3},0 表示点击,1 表示加入购物车,2 表示购买,3 表示关注商品
age_range: String, //买家年龄分段:1 表示年龄 <18,2 表示年龄在[18,24],3 表示年龄在 [25,29],4 表示年龄在 [30,34],5 表示年龄在 [35,39],6 表示年龄在 [40,49],7 和 8 表示年龄 >=50,0 和 NULL 则表示未知
gender: String, //性别:0 表示女性,1 表示男性,2 和 NULL 表示未知
province: String //收货地址省份
)
//Java 工具配置类
import java.util.Properties
//Spark 广播类(在数据处理二中需用到)
import org.apache.spark.broadcast.Broadcast
//SparkContext 类
import org.apache.spark.SparkContext
//连接 Kafka 所需的序列化类
import org.apache.kafka.common.serialization.{StringDeserializer, StringSerializer}
//log4j
import org.apache.log4j.{Level, Logger}
//SparkConf
import org.apache.spark.SparkConf
//Kafka 主题订阅
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
//kafka 工具类(0.8 和 0.10 版本不同,此处为 0.10 版本的工具类导入)
import org.apache.spark.streaming.kafka010.KafkaUtils
//分区方式
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
//StreamingContext
import org.apache.spark.streaming.{Seconds, StreamingContext}
val ssc = new StreamingContext(sc,Seconds(3))
//设置数据检查点
//需要赋予 bigdata 以下所有目录权限,否则会因权限不足无法创建 checkpoint 文件夹
ssc.checkpoint("/bigdata/spark/checkpoint")
//kafka 中创建 demo 主题,用于存放 flume 采集发送过来的源数据
val topics = Set("demo")
val kafkaParams = Map[String, Object](
//配置 kafka 节点
"bootstrap.servers" -> "localhost:9092",
//设置 key 的序列化方式为 StringDeserializer
"key.deserializer" -> classOf[StringDeserializer],
////设置 value 的序列化方式为 StringDeserializer
"value.deserializer" -> classOf[StringDeserializer],
//设置消费组
//一个消费组中可以有多个消费者,所订阅的主题中的消息会被多个消费者分享
//所以在运行此程序前,该消费组中不可有其他的消费者在进行消费
//避免造成消费数据不完整
"group.id" -> "g1",
//偏移量设置为最新
"auto.offset.reset" -> "latest",
//关闭任务自动提交
"enable.auto.commit" -> (false: java.lang.Boolean)
)
//以 direct 模式创建 kafka 数据源的 Dstream
val data = KafkaUtils.createDirectStream(
//StreamingContext 对象
ssc,
//采用一致性方式,将分区大致均匀分配到所有 Executor 上去
PreferConsistent,
//配置 kafka 参数,订阅对应的 demo 主题
Subscribe[String, String](topics, kafkaParams))
val result = data.map(_.value()).map(
line=>{
val record=line.split(",")
//年龄段字段为 0 或者 null,统一重新赋值为 9,方便过滤
if(record(8).equals("0")||record(8)==null)record(8)="9"
//性别字段为 2 或者 null,统一重新赋值为 3,方便过滤
if(record(9).equals("2")||record(9)==null)record(9)="3"
UserBehavior(
record(0), //买家 id
record(1), //商品 id
record(2), //商品类别 id
record(3), //卖家 id
record(4), //品牌 id
record(5), //月份
record(6), //日数
record(7), //行为
record(8), //年龄段
record(9), //性别
record(10) //省份
)
})
val test=result.print()
ssc.start()
本文由 liyunfei 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jul 11,2022