
Spark简介
快如闪电的统一分析引擎.

Apache Spark™是用于大规模数据处理的统一分析引擎。

核心概念
Spark 是 UC Berkeley AMP lab 开发的一个集群计算的框架,类似于 Hadoop,但有很多的区别。最大的优化是让计算任务的中间结果可以存储在内存中,不需要每次都写入 HDFS,更适用于需要迭代的 MapReduce 算法场景中,可以获得更好的性能提升。例如一次排序测试中,对 100TB 数据进行排序,Spark 比 Hadoop 快三倍,并且只需要十分之一的机器。Spark 集群目前最大的可以达到 8000 节点,处理的数据达到 PB 级别,在互联网企业中应用非常广泛。
Spark 的特性
Hadoop 的核心是分布式文件系统 HDFS 和计算框架 MapReduces。Spark 可以替代 MapReduce,并且兼容 HDFS、Hive 等分布式存储层,良好的融入 Hadoop 的生态系统。
Spark 执行的特点
- 中间结果输出:Spark 将执行工作流抽象为通用的有向无环图执行计划(DAG),可以将多 Stage 的任务串联或者并行执行。
- 数据格式和内存布局:Spark 抽象出分布式内存存储结构弹性分布式数据集 RDD,能够控制数据在不同节点的分区,用户可以自定义分区策略。
- 任务调度的开销:Spark 采用了事件驱动的类库 AKKA 来启动任务,通过线程池的复用线程来避免系统启动和切换开销。
Spark 的优势
- 速度快,运行工作负载快 100 倍。Apache Spark 使用最先进的 DAG 调度器、查询优化器和物理执行引擎,实现了批处理和流数据的高性能。
- 易于使用,支持用 Java、Scala、Python、R 和 SQL 快速编写应用程序。Spark 提供了超过 80 个算子,可以轻松构建并行应用程序。您可以从 Scala、Python、R 和 SQL shell 中交互式地使用它。
- 普遍性,结合 SQL、流处理和复杂分析。Spark 提供了大量的库,包括 SQL 和 DataFrames、用于机器学习的 MLlib、GraphX 和 Spark 流。您可以在同一个应用程序中无缝地组合这些库。
- 各种环境都可以运行,Spark 在 Hadoop、Apache Mesos、Kubernetes、单机或云主机中运行。它可以访问不同的数据源。您可以使用它的独立集群模式在 EC2、Hadoop YARN、Mesos 或 Kubernetes 上运行 Spark。访问 HDFS、Apache Cassandra、Apache HBase、Apache Hive 和数百个其他数据源中的数据。
哪些公司在使用 Spark
日常为我们所熟知的,在国外就有 IBM Almaden(IBM 研究实验室)、Amazon(亚马逊)等,而在国内有 baidu(百度)、Tencent(腾讯)等等,包括一些其它的公司大部分都使用 Spark 来处理生产过程中产生的大量数据。更多详情可以参考链接: 谁在使用 Spark?
发展历史
2009 年,Spark 诞生于伯克利大学的 AMPLab 实验室
2010 年,伯克利大学正式开源了 Spark 项目
2013 年 6 月,Spark 成为了 Apache 基金会下的项目
2014 年 2 月,Spark 以飞快的速度成为了 Apache 的顶级项目
2015 年至今,Spark 变得愈发火爆,大量的国内公司开始重点部署或者使用 Spark
核心模块及功能
目前,Spark 已经发展成为包含众多子项目的大数据计算平台。BDAS 是伯克利大学提出的基于 Spark 的数据分析栈(BDAS)。其核心框架是 Spark,同时涵盖支持结构化数据 SQL 查询与分析的查询引擎 Spark SQL,提供机器学习功能的系统 MLBase 及底层的分布式机器学习库 MLlib,并行图计算框架 GraphX,流计算框架 Spark Streaming,近似查询引擎 BlinkDB,内存分布式文件系统 Tachyon,资源管理框架 Mesos 等子项目。这些子项目在 Spark 上层提供了更高层、更丰富的计算范式。

Spark Core
Spark Core 中提供了 Spark 最基础与最核心的功能,Spark 其他的功能如:Spark SQL,
Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基础上进行扩展的
Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL
或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
Spark Streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理
数据流的 API。
Spark MLlib
MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等
额外的功能,还提供了一些更底层的机器学习原语。
Spark GraphX
GraphX 是 Spark 面向图计算提供的框架与算法库。
部署与启动Spark服务
部署 Spark
Spark 虽然是大规模的计算框架,但也支持在单机上运行,这里的教程提供的是单机模式安装,方便同学们在自己的电脑上按照相同的操作方式部署安装。
Spark 安装非常简单,简单到只需要下载 binary 包解压即可,具体的步骤如下。
安装前准备
安装 Spark 之前需要先安装 Java,Scala 及 Python。
安装 Java
首先,我们打开桌面上的Xfce终端,切换到 hadoop 用户下:
su -l hadoop #密码为hadoop

实验楼环境中已经安装了 JDK,执行查看 Java 版本:
java -version

可以看到实验楼的 Java 版本是1.8.0_131,满足 Spark 2.4.4 对 Java 版本的要求。
如果需要自己安装可以在 Oracle 的官网下载 Java SE JDK ,下载链接:http://www.oracle.com/technetwork/java/javase/downloads/index.html
安装 Scala
为了自己开发 Scala 程序调试的方便我们安装一个版本 2.11.8 的 Scala,实验楼环境已经安装了该版本的 Scala,我们可以测试 scala 命令,并查看版本:
scala -version

如果不是以上提示,则表明需要全新安装 Scala ,可以参考以下命令(在本实验环境中不必输入):
cd /home/hadoop
wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
tar -zxvf scala-2.11.8.tgz
sudo mv scala-2.11.8 /opt/scala-2.11.8
sudo chown -R hadoop:hadoop /opt/scala-2.11.8
添加系统环境变量:
vim /home/hadoop/.bashrc
在文件的末尾添加以下内容,注意环境变量 PATH 中的 SCALA_HOME/bin` 即可。
export SCALA_HOME=/opt/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
然后执行如下命令使添加后的环境变量生效:
source /home/hadoop/.bashrc
安装 Python
在本实验环境中默认是已经安装好了 Python,可以执行如下命令查看 Python 的版本:
python --version

Spark 下载
课程中使用目前最新稳定版:Spark 2.4.4,官网上下载已经预编译好的 Spark binary,直接解压即可。
Spark 官方下载链接:http://spark.apache.org/downloads.html
由于实验环境中我们使用的是 Hadoop 2.7.3,所以下载页面中我们如下图选择Pre-build for Apache Hadoop 2.7 and later并点击复制下载链接:
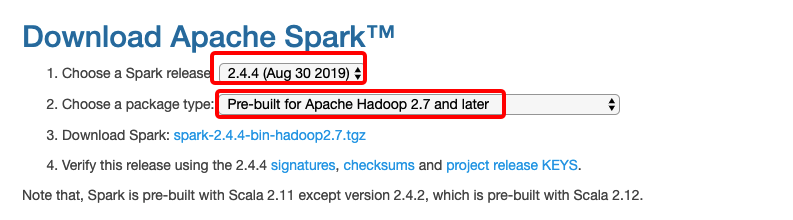
首先,切换到 hadoop 主目录,在终端中输入以下命令:
cd /home/hadoop
切换完成后,使用 wget 命令下载 Spark 的安装包,在终端中输入以下命令:
wget https://mirrors.huaweicloud.com/apache/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
对下载得到的安装包进行解压缩:
tar -zxvf spark-2.4.4-bin-hadoop2.7.tgz
随后,将解压得到的 Spark 目录移动到 /opt 目录下,并将目录的所有者修改为 hadoop 用户。请在终端输入以下命令:
sudo mv spark-2.4.4-bin-hadoop2.7 /opt/spark-2.4.4-bin-hadoop2.7
sudo chown -R hadoop:hadoop /opt/spark-2.4.4-bin-hadoop2.7
配置路径与日志级别
接着,需要设置 Spark 相关的环境变量。使用 VIM 编辑器打开用户主目录下的.bashrc文件:
vim /home/hadoop/.bashrc

在文件的末尾添加以下内容,其中 $SPARK_HOME/bin 是直接添加在已有的 PATH 环境变量之后,$PATH由环境中的实际情况决定。
export SPARK_HOME=/opt/spark-2.4.4-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
编辑完成后保存并退出 VIM 编辑器。在终端中使用 source 命令来激活之前设置的环境变量:
source /home/hadoop/.bashrc
运行如下的命令打印出 spark-shell 的路径:
$ which spark-shell
/opt/spark-2.4.4-bin-hadoop2.7/bin/spark-shell
spark-shell 的路径被打印了出来,证明实验楼的环境没有错误。
我们进入到 spark 的配置目录 /opt/spark-2.4.4-bin-hadoop2.7/conf/ 进行配置:
cd /opt/spark-2.4.4-bin-hadoop2.7/conf/
基于模板创建日志配置文件:
cp log4j.properties.template log4j.properties
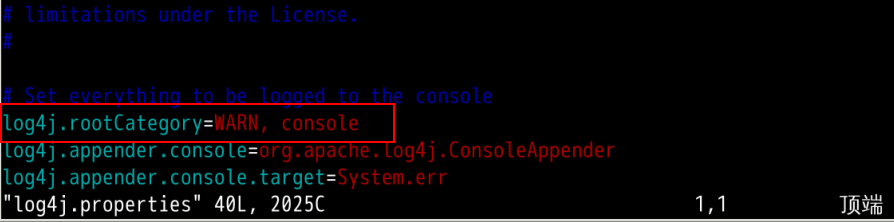
使用 VIM 编辑文件 log4j.properties:
vim log4j.properties
修改 log4j.rootCategory 为 WARN, console ,可避免测试中输出太多信息:
使用 VIM 编辑文件 spark-env.sh:
sudo vim spark-env.sh
添加以下内容设置 Spark 的环境变量:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export SPARK_HOME=/opt/spark-2.4.4-bin-hadoop2.7
export SCALA_HOME=/opt/scala-2.11.8
spark-env.sh脚本会在启动 Spark 时加载,内容包含很多配置选项及说明,在以后的实验中会用到少部分,感兴趣可以仔细阅读这个文件的注释内容。
至此,Spark 就已经安装好了,Spark 安装很简单,依赖也很少。
Spark-Shell
Spark-Shell是 Spark 自带的一个 Scala 交互 Shell ,可以以脚本方式进行交互式执行,类似直接用 Python 及其他脚本语言的 Shell 。
进入Spark-Shell只需要执行spark-shell即可:
spark-shell #执行需要等待一小会
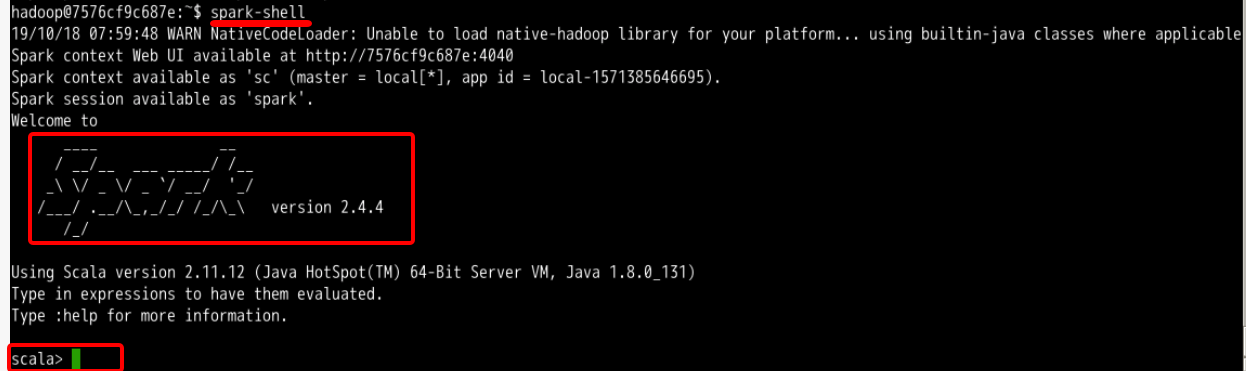
进入到Spark-Shell后可以使用Ctrl D组合键退出 Shell。
在Spark-Shell中我们可以使用 Scala 的语法进行简单的测试,比如我们运行下面几个语句获得文件/etc/protocols的行数以及第一行的内容:
var file = sc.textFile("/etc/protocols")
file.count()
file.first()
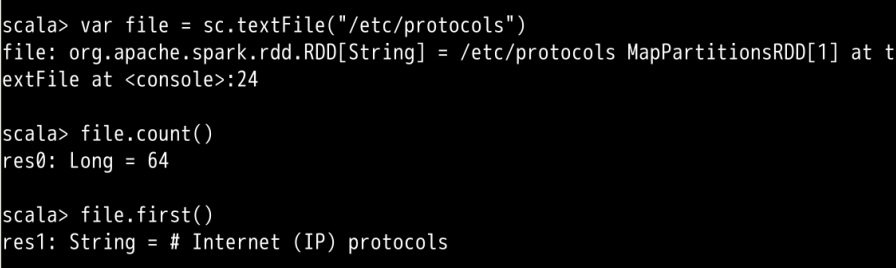
上面的操作中创建了一个 RDD file,执行了两个简单的操作:
count()获取 RDD 的行数first()获取第一行的内容
我们继续执行其他操作,比如查找有多少行含有tcp和udp字符串:
file.filter(line => line.contains("tcp")).count()
file.filter(line => line.contains("udp")).count()
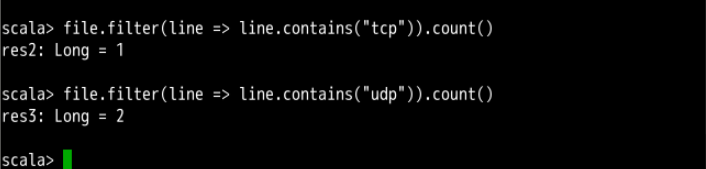
查看一共有多少个不同单词的方法,这里用到 Mapreduce 的思路:
var wordcount = file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
wordcount.count()
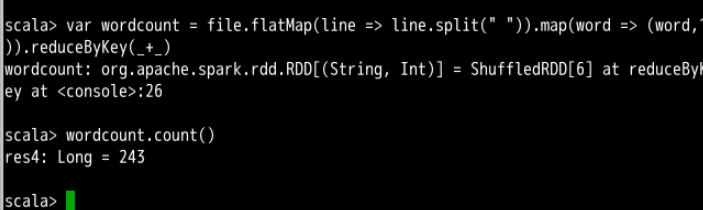
上面两步骤我们发现,/etc/protocols中各有一行含有tcp与udp字符串,并且一共有 243 个不同的单词。
上面每个语句的具体含义这里不展开,可以结合你阅读的文章进行理解,后续实验中会不断介绍。这里仅仅提供一个简单的例子让大家对 Spark 运算有基本认识。
操作完成后,Ctrl D组合键退出 Shell。
Pyspark
Pyspark 类似 Spark-Shell ,是一个 Python 的交互 Shell 。
执行pyspark启动进入 Pyspark:
pyspark #执行需要等待一小会
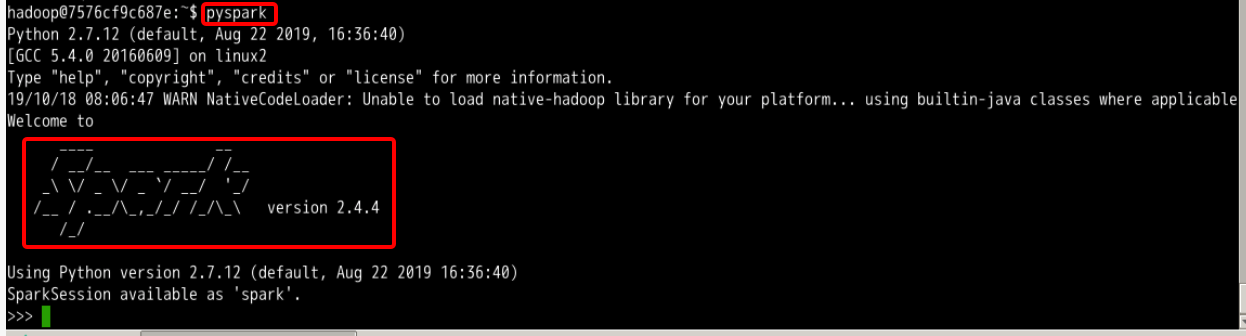
退出方法仍然是Ctrl D组合键。
在 Pyspark 中,我们可以用 Python 语法执行 Spark-Shell 中的操作,比如下面的语句获得文件/etc/protocols 的行数以及第一行的内容:
file = sc.textFile("/etc/protocols")
file.count()
file.first()
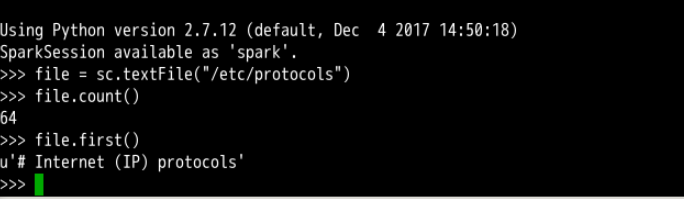
操作完成后,Ctrl D组合键退出 Shell。
在后续的实验中我们主要是使用 Spark-Shell 编写代码,对于 Pyspark 大家可以自行学习拓展,可以参考官方文档Spark Python API
启动 Spark 服务
这一节我们将启动 Spark 的 master 主节点和 slave 从节点,这里也会介绍 spark 单机模式和集群模式的部署区别。
本节实验包括以下 5 个小节内容:
1、启动主节点
2、启动从节点
3、测试实例
4、停止服务
5、集群部署
启动主节点
执行下面几条命令启动主节点:
# 进入到spark目录
cd /opt/spark-2.4.4-bin-hadoop2.7/sbin
# 启动主节点
./start-master.sh

没有报错的话表示 master 已经启动成功,master 默认可以通过 web 访问http://localhost:8080,依次点击 所有应用程序 -> 互联网 -> Firefox 网络浏览器,访问该链接:
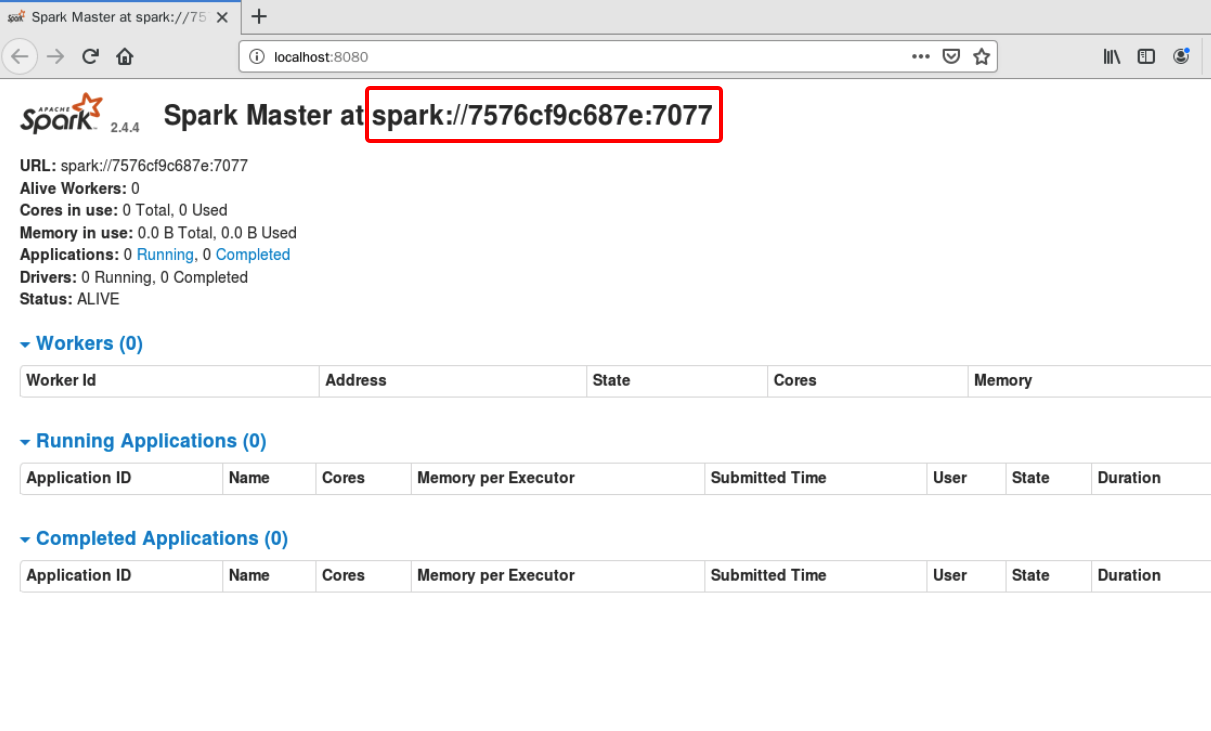
图中所示,master 中暂时还没有一个 worker ,我们启动 worker 时需要 master 的参数,该参数已经在上图中标志出来:spark://7576cf9c687e:7077,请在执行后续命令时替换成你自己的参数。
启动从节点
执行下面的命令启动 slave:
./start-slave.sh spark://7576cf9c687e:7077

没有报错表示启动成功,再次刷新 Firefox 浏览器页面可以看到下图所示新的 worker 已经添加:
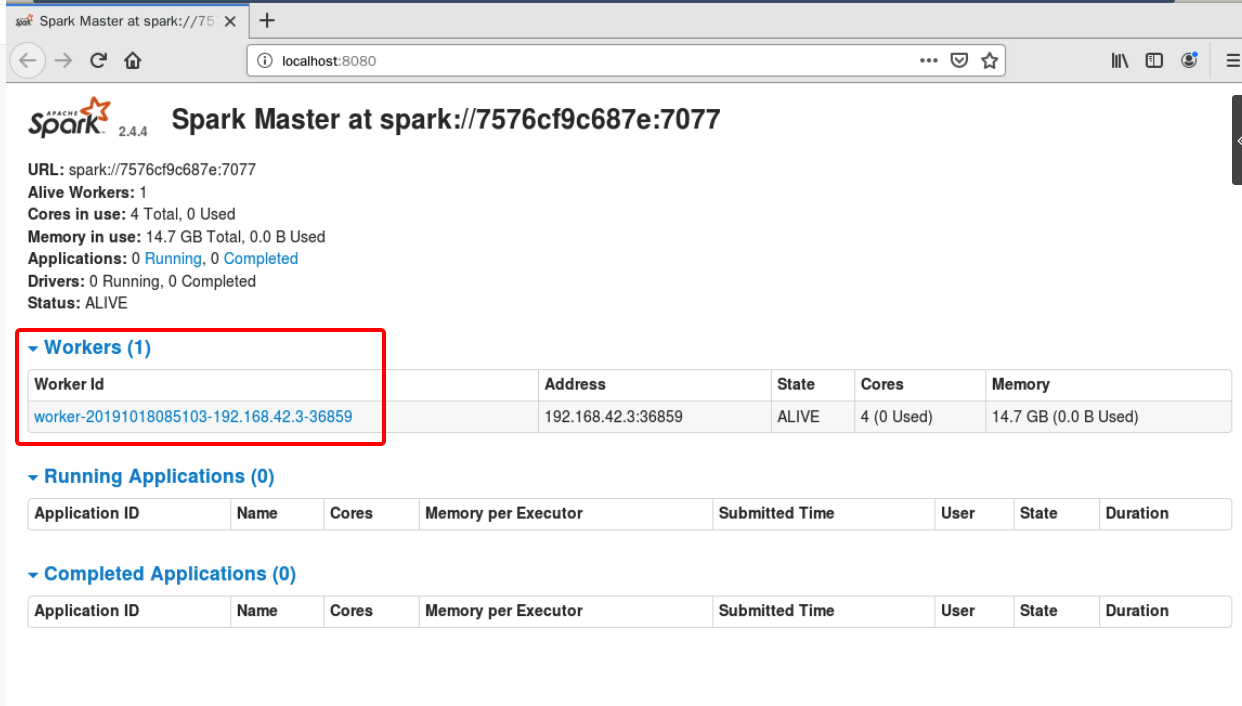
也可以用jps命令查看启动的服务,应该会列出Master和Worker。

测试实例
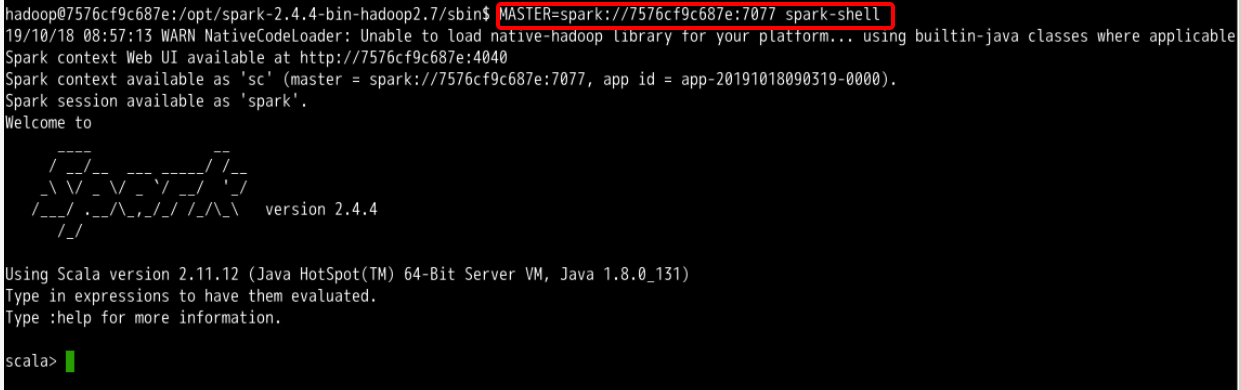
使用 spark-shell 连接 master ,注意把 MASTER 参数替换成你实验环境中的实际参数:
MASTER=spark://7576cf9c687e:7077 spark-shell #执行需要等待一小会
刷新 master 的 web 页面,可以看到新的Running Applications,如下图所示:
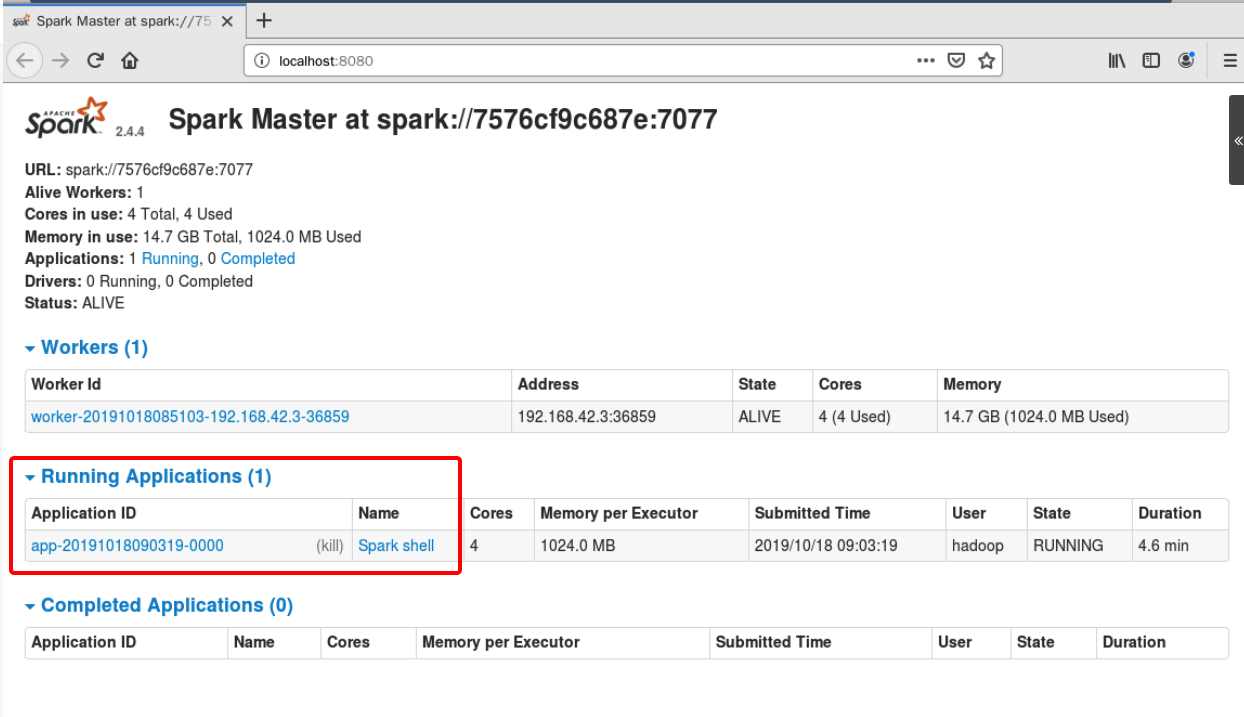
当退出 spark-shell 时,这个 application 会移动到Completed Applications一栏。
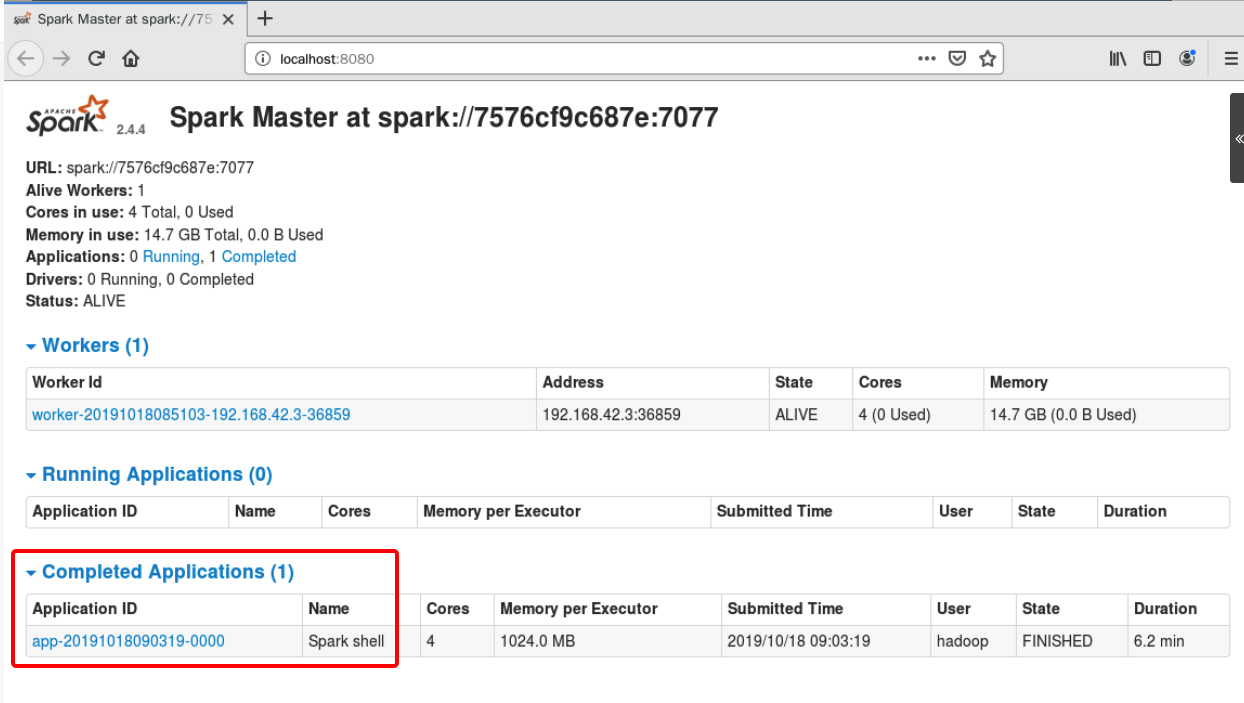
可以自己点击页面中的 Application 和 Workers 的链接查看并了解相关信息。
停止服务
停止服务的脚本为./sbin/stop-all.sh。
./stop-all.sh
jps

通过 jps 可以看到,master 与 worker 进程都已经停止。
集群部署
上面的步骤介绍了我们在单机模式Standalone Mode下部署的 Spark 环境,如果要部署 Spark 集群稍有区别:
- 主节点上配置 spark ,例如
conf/spark-env.sh中的环境变量 - 主节点上配置
conf/slaves,添加从节点的主机名,注意需要先把所有主机名输入到/etc/hosts避免无法解析 - 把配置好的 spark 目录拷贝到所有从节点,从节点上的目录路径与主节点一致,例如都设置为
/opt/spark-2.3.1-bin-hadoop2.6 - 配置主节点到所有从节点的 SSH 无密码登录,使用
ssh-keygen -t rsa和ssh-copy-id两个命令 - 启动 spark 集群,在主节点上执行
sbin/start-all.sh - 进入主节点的 web 界面查看所有 worker 是否成功启动
总结
介绍了 Spark 的生态系统 BDAS、单机模式和集群模式的安装部署方法,并尝试了启动 Spark 服务进行基本的测试。
- Spark 核心概念
- Spark 生态系统 BDAS
- Spark 单机模式部署
- Spark 集群模式部署
- Spark-Shell 的基本使用
- 启动 Spark 服务
总体而言,Spark 作为一个用来实现快速而通用的集群计算的平台,其功能还有待进一步挖掘,请保持积极查询技术资料的习惯,并请继续学习后续的课程。
参考链接:
环境准备
安装Hadoop\Spark环境
1.将Hadoop安装包和Spark安装包分别解压至合适的目录
2.在环境变量中配置HADOOP_HOME

3.将HADOOP_HOME引入Path

4.测试
在Spark安装目录中的bin目录下找到spark-shell.cmd双击运行

5.访问控制台
浏览器访问localhost:4040

创建Maven项目
打开IDEA创建Maven项目


更新pom文件,加入以下坐标,并更新maven配置等待下载完成.
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>

邮件项目,选择Add Framework Support…
添加Scala代码模板


在main中创建scala目录,并标记为Sources Root目录

创建HelloSpark Object进行测试
package cn.tedu.spark.hello
import org.apache.spark.SparkContext
object HelloSpark {
def main(args: Array[String]): Unit = {
println("Hello Spark: " + SparkContext)
}
}

导入log4j.properties
resources目录下创建log4j.properties文件
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd
HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell,
the
# log level for this class is used to overwrite the root logger's log level, so
that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent
UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
WordCount
使用Spark实现WordCount
package cn.tedu.spark.core.wc
/**
* Spark入门案例_WordCound
*/
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//1.初始化配置
val sparkConf: SparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
//2.创建Spark执行环境
val sc = new SparkContext(sparkConf)
//3.读取数据文件
val lines = sc.textFile("{datas/*}")
//4.拆分单词,扁平化处理,转化为Tuple
val wordTuple = lines.flatMap(_.split(" ")).map((_, 1))
//5.分组聚合
val result = wordTuple.reduceByKey(_ + _)
//6.从内存中收集结果并打印
result.collect().foreach(println)
//7.释放资源
sc.stop()
}
}
SparkCore
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于
处理不同的应用场景。三大数据结构分别是:
RDD : 弹性分布式数据集
累加器:分布式共享只写变量
广播变量:分布式共享只读变量
RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据
处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行
计算的集合。
- 弹性:
存储的弹性:内存与磁盘的自动切换;
容错的弹性:数据丢失可以自动恢复;
计算的弹性:计算出错重试机制;
分片的弹性:可根据需要重新分片。 - 分布式:数据存储在大数据集群不同节点上
- 数据集:RDD 封装了计算逻辑,并不保存数据
- 数据抽象:RDD 是一个抽象类,需要子类具体实现
- 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在
新的 RDD 里面封装计算逻辑 - 可分区、并行计算

RDD的创建/数据读取
package cn.tedu.spark.core.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 读取数据
*/
object SourceTest {
def main(args: Array[String]): Unit = {
//1.初始化配置
val conf = new SparkConf().setMaster("local[*]").setAppName("RDDSourceTest")
//2.创建Spark环境
val sc = new SparkContext(conf)
//3.从List中读取数据
val list = List(1,2,3,4,5)
// val source1: RDD[Int] = sc.parallelize(list)
val source1: RDD[Int] = sc.makeRDD(list)
//3.从文件中读取数据
val source2: RDD[String] = sc.textFile("{datas/*}")
//5.收集结果
source1.collect().foreach(s => println("source1: "+ s))
source2.collect().foreach(s => println("source2: "+ s))
//6.释放资源
sc.stop()
}
}
分区和并行度
package cn.tedu.spark.core.rdd
import org.apache.spark.{SparkConf, SparkContext}
/**
* 分区,并行度
*/
object RDDParTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("RDDParTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.处理数据
val list = List(1,2,3,4,5)
// val memSource = sc.makeRDD(list)
val memSource = sc.makeRDD(list,3)
// memSource.saveAsTextFile("result")
memSource.saveAsTextFile("result3")
//3.释放资源
sc.stop()
}
}
算子
所谓算子简言之就是将整个事件处理的整个过程拆分成多个阶段,每个阶段就是一个算子.Spark中的算子被分为两类,包括Transformations和Actions.
Transformations
map
map(func):返回一个新的分布式数据集,该数据集是通过将源的每个元素传递给函数func形成的。
package cn.tedu.spark.core.rdd.operator
import org.apache.spark.{SparkConf, SparkContext}
/**
* map
*/
object TransformationsTest {
def main(args: Array[String]): Unit = {
/*
map
进一出一
*/
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
//2.1.获取数据源
val list = List(1,2,3,4)
val source = sc.makeRDD(list)
//2.2.map
val result = source.map(_ * 2)
//2.3.收集数据并打印
result.collect().foreach(println)
//3.释放资源
sc.stop()
}
}
分区并行测试
package cn.tedu.spark.core.rdd.operator
/**
* map并行
*/
import org.apache.spark.{SparkConf, SparkContext}
object TransformationParTest {
def main(args: Array[String]): Unit = {
/*
map
进一出一
*/
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
//2.1.获取数据源
val list = List(1, 2, 3, 4)
/*
1.RDD的计算一个分区内数据是一个一个串行执行的,前边的数据完全执行完之后,后边的数据才会开始执行.
2.不同的分区之间数据计算是无序的(并行)
*/
// val source = sc.makeRDD(list)
// val source = sc.makeRDD(list,1)
val source = sc.makeRDD(list,2)
//2.2.map
val result = source.map(
num => {
println("A: " + num)
num
}
)
val result1 = result.map(
num => {
println("B: " + num)
}
)
//2.3.收集数据
result1.collect()
//3.释放资源
sc.stop()
}
}
mapPartitions
mapPartitions(func): 与map相似,但是分别在RDD的每个分区(块)上运行,因此func在类型T的RDD上运行时必须为Iterator => Iterator 类型。
功能上与map相同,但是性能上高与map,原因是读取整个分区数据之后统一计算,相当于批处理.
缺点是如果数据量大,内存资源小可能出错(内存资源不足).
package cn.tedu.spark.core.rdd.operator
/**
* mapPartitions
*/
import org.apache.spark.{SparkConf, SparkContext}
object TransformationTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
val mapPartitionsList = List(1, 2, 3, 4)
val mapPartitionsSource = sc.makeRDD(mapPartitionsList,3)
val mapPartitionsResult = mapPartitionsSource.mapPartitions(
iter => {
println("这是一个单独的分区")
iter.map(_ * 10)
}
)
mapPartitionsResult.collect().foreach(println)
//3.释放资源
sc.stop()
}
}
mapPartitions和map的区别
➢ 数据处理角度
Map 算子是分区内一个数据一个数据的执行,类似于串行操作。而 mapPartitions 算子
是以分区为单位进行批处理操作。
➢ 功能的角度
Map 算子主要目的将数据源中的数据进行转换和改变。但是不会减少或增多数据。
MapPartitions 算子需要传递一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变,
所以可以增加或减少数据
➢ 性能的角度
Map 算子因为类似于串行操作,所以性能比较低,而是 mapPartitions 算子类似于批处
理,所以性能较高。但是 mapPartitions 算子会长时间占用内存,那么这样会导致内存可能
不够用,出现内存溢出的错误。所以在内存有限的情况下,不推荐使用。使用 map 操作。
flatMap
flatMap(func): 与map相似,但是每个输入项都可以映射到0个或多个输出项(因此func应该返回Seq而不是单个项)。
package cn.tedu.spark.core.rdd.operator
import org.apache.spark.{SparkConf, SparkContext}
/**
* flatMap
*/
object TransformationsTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val flatMapList = List("hello scala", "hello spark")
val flatMapSource = sc.makeRDD(flatMapList)
val flatMapResult = flatMapSource.flatMap(_.split(" "))
flatMapResult.collect().foreach(println)
//3.释放资源
sc.stop()
}
}
glom
glom(): 将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变
package cn.tedu.spark.core.rdd.operator
import org.apache.spark.{SparkConf, SparkContext}
/**
* glom
*/
object TransformationGlomTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
val source = sc.makeRDD(List(1, 2, 3, 4), 2)
val value = source.glom()
value.collect().foreach(value => println(value.mkString(",")))
//3.释放资源
sc.stop()
}
}
filter
filter(func): 返回一个新的数据集,该数据集是通过选择func在其上返回true的源中的那些元素形成的。
package cn.tedu.spark.core.rdd.operator.transformation
import org.apache.spark.{SparkConf, SparkContext}
/**
* filter过滤器
*/
object FilterTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
val source = sc.makeRDD(List(1, 2, 3, 4), 2)
val value = source.filter(
_ % 2 == 0
)
value.collect().foreach(println)
//3.释放资源
sc.stop()
}
}
groupBy
groupBy(func): 返回分组项目的RDD。每个组由一个键和映射到该键的一系列元素组成。不能保证每个组中元素的顺序,甚至每次评估生成的RDD时都可能会有所不同。
package cn.tedu.spark.core.rdd.operator.transformation
import org.apache.spark.{SparkConf, SparkContext}
/**
* groupBy 分组
*/
object GroupByTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
val source = sc.makeRDD(List(1, 2, 3, 4), 2)
val value = source.groupBy(num => num % 2)
value.collect().foreach(println)
//3.释放资源
sc.stop()
}
}
reduceByKey
reduceByKey(func): 在(K,V)对的数据集上调用时,返回(K,V)对的数据集,其中每个键的值使用给定的reduce函数func(其类型必须为(V,V)=>)进行汇总V.与in一样groupByKey,reduce任务的数量可以通过可选的第二个参数进行配置。
package cn.tedu.spark.core.rdd.operator.transformation
import org.apache.spark.{SparkConf, SparkContext}
/**
* reduceByKey 分组聚合
*/
object ReduceByKeyTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
val source = sc.makeRDD(List(("spark",4), ("scala",2), ("spark",1), ("scala",2)), 2)
val value = source.reduceByKey(_ + _)
value.collect().foreach(println)
//3.释放资源
sc.stop()
}
}
cogroup
cogroup(otherDataset, [numPartitions]): 在(K,V)和(K,W)类型的数据集上调用时,返回(K,(Iterable ,Iterable ))元组的数据集。此操作也称为groupWith。
package cn.tedu.spark.core.rdd.operator.transformation
import org.apache.spark.{SparkConf, SparkContext}
/**
* cogroup
*/
object CogroupTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
val source1 = sc.makeRDD(List(("spark",4), ("scala",2), ("spark",1), ("scala",2)), 2)
val source2 = sc.makeRDD(List(("spark","k"), ("scala","a"), ("spark","k"), ("scala","a")), 2)
val source3 = sc.makeRDD(List(("spark",2), ("scala",1), ("hello",2)), 2)
val value = source1.cogroup(source2,source3)
//val value = source1.groupWith(source2,source3)
value.collect().foreach(println)
//3.释放资源
sc.stop()
}
}
Actions
reduce
reduce(func): 使用函数func(该函数接受两个参数并返回一个)来聚合数据集的元素。该函数应该是可交换的和关联的,以便可以并行正确地计算它。
package cn.tedu.spark.core.rdd.operator.actions
/**
* reduce 聚合
*/
import org.apache.spark.{SparkConf, SparkContext}
object ReduceTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
val source = sc.makeRDD(List(1, 2, 3, 4), 2)
val value = source.reduce(_ + _)
println(value)
//3.释放资源
sc.stop()
}
}
collect
collect(): 在驱动程序中将数据集的所有元素作为数组返回。这通常在返回足够小的数据子集的过滤器或其他操作之后很有用。
package cn.tedu.spark.core.rdd.operator.actions
/**
* collect 收集
*/
import org.apache.spark.{SparkConf, SparkContext}
object CollectTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
val source = sc.makeRDD(List(1, 2, 3, 4), 2)
val value = source.collect()
println(value.mkString(","))
//3.释放资源
sc.stop()
}
}
count
count(): 返回数据集中的元素数。
package cn.tedu.spark.core.rdd.operator.actions
/**
* count 计数
*/
import org.apache.spark.{SparkConf, SparkContext}
object CountTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
val source = sc.makeRDD(List(1, 2, 3, 4), 2)
val value = source.count()
println(value)
//3.释放资源
sc.stop()
}
}
first
first(): 返回数据集的第一个元素(类似于take(1))。
package cn.tedu.spark.core.rdd.operator.actions
/**
* first 取第一个元素
*/
import org.apache.spark.{SparkConf, SparkContext}
object FirstTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
val source = sc.makeRDD(List(1, 2, 3, 4), 2)
val value = source.first()
println(value)
//3.释放资源
sc.stop()
}
}
take
take(n): 返回具有数据集的前n个元素的数组。
package cn.tedu.spark.core.rdd.operator.actions
/**
* take 取前n个数
*/
import org.apache.spark.{SparkConf, SparkContext}
object TakeTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
val source = sc.makeRDD(List(1, 2, 3, 4), 2)
val value = source.take(3)
println(value.mkString("|"))
//3.释放资源
sc.stop()
}
}
takeOrdered
takeOrdered(n,[ordering]) : 使用自然顺序或自定义比较器返回RDD的前n个元素。
package cn.tedu.spark.core.rdd.operator.actions
/**
* takeOrdered 排序后取前n个元素
*/
import org.apache.spark.{SparkConf, SparkContext}
object TakeOrderedTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
val source = sc.makeRDD(List(5,2,3,1,4), 2)
val value = source.takeOrdered(3)(Ordering[Int].reverse)
println(value.mkString("|"))
//3.释放资源
sc.stop()
}
}
RDD依赖关系
RDD血缘关系
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用,窄依赖我们形象的比喻为独生子女。
宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
累加器和广播变量
累加器
累加器Accumulator用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后,传回 Driver 端进行 merge。
package cn.tedu.spark.core.accumulator
import org.apache.spark.{SparkConf, SparkContext}
/**
* 累加器
*/
object AccumulatorTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("TransformationsTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
val source = sc.makeRDD(List(1, 2, 3, 4))
val value = source.reduce(_ + _)
println(value)
var sum = 0 //sum = 0 定义在Driver中
source.foreach(sum += _) //计算在Executor中,数据没有回收到Driver
println(sum) //0
//累加器
val acc = sc.longAccumulator
source.foreach(acc.add(_))
println(acc.value)
//3.释放资源
sc.stop()
}
}
广播变量
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来都很顺手。在多个并行操作中使用同一个变量,但是 Spark 会为每个任务分别发送。
package cn.tedu.spark.core.broadcast
import org.apache.spark.{SparkConf, SparkContext}
/**
* BroadcastTest 广播变量
*/
object BroadcastTest {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setAppName("BroadcastTest").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2.构建DAG
val source = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3), ("d", 4)))
val list = List(("a", 1), ("b", 2), ("c", 3), ("d", 4))
// 声明广播变量
val broadcast = sc.broadcast(list)
val resultRDD = source.map {
case (key, num) => {
var num2 = 0
// 使用广播变量
for ((k, v) <- broadcast.value) {
if (k == key) {
num2 = v
}
}
(key, (num, num2))
}
}
resultRDD.collect().foreach(println)
//3.释放资源
sc.stop()
}
}
SparkSQL

Spark SQL是用于结构化数据处理的Spark模块。与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息。在内部,Spark SQL使用这些额外的信息来执行额外的优化。与Spark SQL交互的方法有多种,包括SQL和Dataset API。计算结果时,将使用相同的执行引擎,而与要用来表达计算的API /语言无关。这种统一意味着开发人员可以轻松地在不同的API之间来回切换,从而提供最自然的方式来表达给定的转换。
pom文件,在此前基础上增加以下坐标
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
示例代码
package cn.tedu.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* SparkSQL
*/
object SparkSqlTest {
def main(args: Array[String]): Unit = {
//1.初始化执行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSqlTest")
val ss = SparkSession.builder().config(sparkConf).getOrCreate()
//2.构建DAG
val df = ss.read.json("datas/user.json")
// df.show()
df.createOrReplaceTempView("user")
val resultDF = ss.sql("select age,name from user where age > 19")
resultDF.show()
//3.释放资源
ss.close()
}
}
SparkStreaming

Spark Streaming是核心Spark API的扩展,可实现实时数据流的可伸缩,高吞吐量,容错流处理。数据可以从像Kafka或TCP套接字许多来源摄入,并且可以使用与像高级别功能表达复杂的算法来处理map,reduce,join和window。最后,可以将处理后的数据推送到文件系统,数据库或实时展示。并且,您还可以在数据流上应用Spark的 机器学习和 图形处理算法。
添加pom依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
12345
安装NetCat
代码示例
package cn.tedu.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* SparkStreaming
*/
object WordCount {
def main(args: Array[String]): Unit = {
//1.初始化执行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//定义采集周期(微批)
val ssc = new StreamingContext(sparkConf, Seconds(3))
//2.构建DAG
val streamSource = ssc.socketTextStream("localhost", 9999)
streamSource.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()
//3.释放资源
// ssc.stop()
ssc.start()
ssc.awaitTermination()
}
}
项目实战
统计热销商品TOP10
1.统计商品点击量排名
2.统计商品订单量排名
3.统计商品支付量排名
4.统计综合排名: 热度 = 点击量 * 20% + 订单量 * 30% + 支付量 * 50%
数据准备及字段解释

上面的数据图是从数据文件中截取的一部分内容,表示为电商网站的用户行为数据,主
要包含用户的 4 种行为:搜索,点击,下单,支付。数据规则如下:
➢ 数据文件中每行数据采用下划线分隔数据
➢ 每一行数据表示用户的一次行为,这个行为只能是 4 种行为的一种
➢ 如果搜索关键字为 null,表示数据不是搜索数据
➢ 如果点击的品类 ID 和产品 ID 为-1,表示数据不是点击数据
➢ 针对于下单行为,一次可以下单多个商品,所以品类 ID 和产品 ID 可以是多个,id 之
间采用逗号分隔,如果本次不是下单行为,则数据采用 null 表示
➢ 支付行为和下单行为类似

业务实现
pom文件
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
1234567
核心代码
package cn.tedu.project
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 项目实战
* 统计TOP10热门商品
*/
object HotSaleTop10 {
def main(args: Array[String]): Unit = {
//1.初始化环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10")
val sc = new SparkContext(sparkConf)
//2.构建DAG
//2.1 读取日志数据
val logsRDD = sc.textFile("datas/user_visit_action.txt")
//2.2 统计商品的点击数量
//2.2.1 过滤
val clickRDD = logsRDD.filter(log => {
val fields = log.split("_")
fields(7) != "-1"
})
//2.2.2 转化数据为Tuple
val tupledClickRDD = clickRDD.map(
click => {
val fields = click.split("_")
(fields(7), 1)
}
)
//2.2.3 统计点击量
val clickCountRDD = tupledClickRDD.reduceByKey(_ + _)
clickCountRDD.sortBy(_._2, false)
.coalesce(1).saveAsTextFile("top10/click")
//2.3 统计商品的下单数量
//2.3.1 过滤数据
val orderRDD = logsRDD.filter(_.split("_")(9) != "null")
//2.3.2 转化数据为Tuple
val tupledOrderRDD = orderRDD.flatMap(
log => {
val fields = log.split("_")
val productIds = fields(9).split(",")
productIds.map(
(_, 1)
)
}
)
//2.3.3 统计下单数量
val orderCountRDD = tupledOrderRDD.reduceByKey(_ + _)
// orderCountRDD.collect().foreach(println)
orderCountRDD.sortBy(_._2,false).coalesce(1).saveAsTextFile("top10/order")
//2.4 统计商品的支付数量
//2.4.1 过滤数据
val payRDD = logsRDD.filter(_.split("_")(11) != "null")
//2.4.2 转化数据为Tuple
val tupledPayRDD = payRDD.flatMap(
log => {
val fields = log.split("_")
val productIds = fields(11).split(",")
productIds.map(
(_, 1)
)
}
)
//2.4.3 统计支付数量
val payCountRDD = tupledPayRDD.reduceByKey(_ + _)
// payCountRDD.collect().foreach(println)
payCountRDD.sortBy(_._2).repartition(1).saveAsTextFile("top10/pay")
//2.5 将商品点击\下单\成交量进行权重排序,并且取TOP10
//热度 = 点击量 * 20% + 下单量 * 30% + 成交量 * 50%
//2.5.1 整合数据,cogroup
val cogroupRDD: RDD[(String, (Iterable[Int], Iterable[Int], Iterable[Int]))] =
clickCountRDD.cogroup(orderCountRDD, payCountRDD)
//2.5.2 权重转换
val countedRDD = cogroupRDD.mapValues {
info => {
info._1.sum * 0.2 + info._2.sum * 0.3 + info._3.sum * 0.5
}
}
//2.5.3 排序并获取TOP10
val resultRDD = countedRDD.sortBy(_._2, false).take(10)
//2.6 收集输出结果
// resultRDD.foreach(println)
sc.makeRDD(resultRDD,1).saveAsTextFile("top10/top10")
//3.释放资源
sc.stop()
}
}
本文由 liyunfei 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jun 24,2022