
课前复习
启动 Spark
切换到 hadoop 用户:
$ su -l hadoop #密码为:hadoop
在 /home/hadoop 目录下创建一个 data 文件夹方便我们存放实验数据:
$ mkdir data
进入 data 目录后,创建一个文本文件供后面案例使用:
$ vim wordcount.txt
输入下面文本然后保存即可。按退出键,然后输入 :wq 回车即可:
spark hadoop
spark hdfs
yarn
storm mapreduce
hadoop
启动 Spark:
$ spark-shell
如下图所示:
WordCount 案例实战
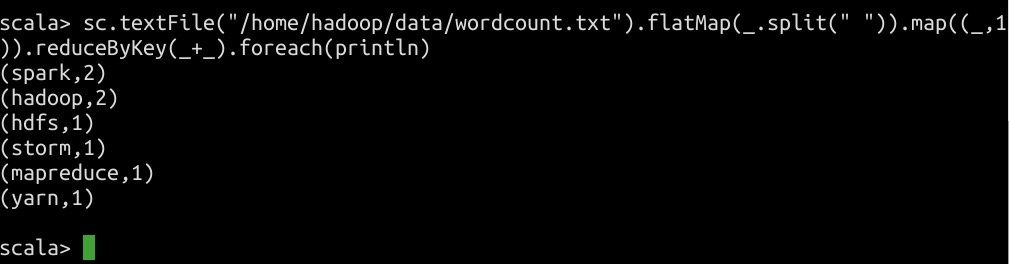
在启动 Spark 之后,我们来简单的做一个 wordcount 案例,温故一下前面的 Spark 的知识:
sc.textFile("/home/hadoop/data/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
Spark SQL 概述与架构
简单的复习了 Spark 的使用之后,在这一节中我们来认识一下 Spark 的一个重要模块 Spark SQL,在 Spark 生态系统中,有众多的模块,它们形成了一站式的大数据解决方案,深受开发者的喜爱,如下图所示:
概述
Spark SQL 是 Spark 的一个结构化数据处理模块,提供了一个 DataFrame 的抽象模型,在 Spark 1.6.0 之后,又加入了 DataSet 的抽象模型,具体后面的章节会详细讲解。因此它是一个分布式 SQL 查询引擎,Spark SQL 主要由 Catalyst 优化,Spark SQL 内核,Hive 支持三部分组成。
- Catalyst 优化处理查询语句的整个过程,包括解析,绑定,优化,物理计划等,主要由关系代数、表达式以及查询优化组成。
- Spark SQL 内核处理数据的输入输出,从不同的数据源(结构化 Parquet 文件和 JSON 文件、Hive 表、外部数据库,创建 RDD)获取数据,执行查询,并将结果输出成 DataFrame。
- Hive 支持是只对 Hive 数据的处理,主要包括 HiveSQL、MetaStore、SerDes、UDFS 等。
Spark SQL 的架构
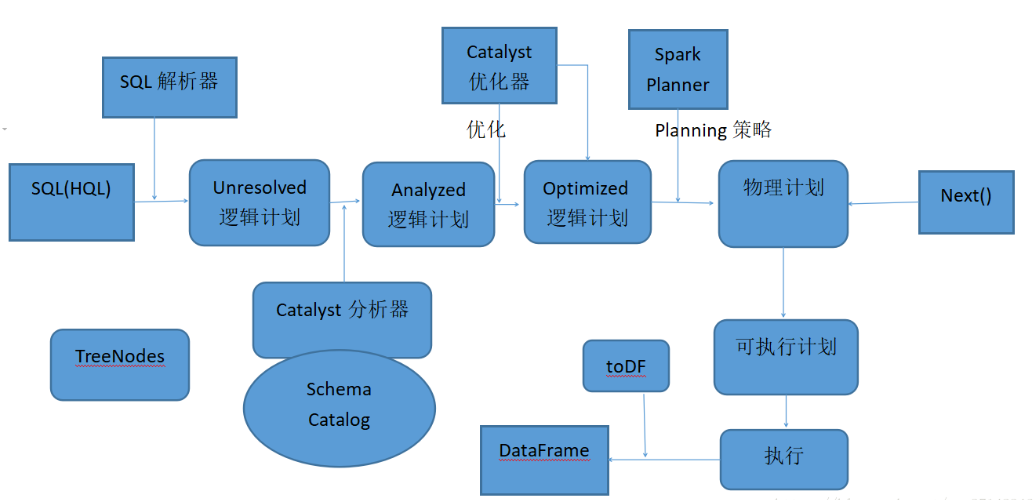
架构图如上所示,虽然有点复杂,但是并不影响我们的学习,下面简单概述一下其架构原理:
- 使用 SqlParser 对 SQL 语句进行解析,生成 Unresolved 逻辑计划,没有提取 schema 信息)。
- 使用 Catalyst 分析器,结合数据字典(catalog)进行绑定,生成 Analyzed 逻辑计划,在此过程中,Schema Catalog 则要提取 schema 信息。
- 使用 Catalyst 优化器对 Analyzed 逻辑计划进行优化,按照优化规则得到 Optimized 逻辑计划。
- 接着和 Spark Planner 交互,使用相应的策略将逻辑计划转换为物理计划,然后调用 next 函数,生成可执行物理计划。
- 调用 toDF,最后生成 DataFrame。
Spark SQL 的优点
Spark SQL 有以下优点:
- 兼容多种数据格式,如上面所说的 parquet 文件,HIve 表,JSON 文件等等。
- 方便扩展,它的优化器,解析器都可以重新定义。
- 性能优化方面:采用了内存列式存储,动态字节码生成等技术,还采用了内存缓存数据。
- 支持多种语言操作,包括 java、scala、python、R 语言等。
Spark SQL 的简单使用
下面,我们通过简单的例子入门 Spark SQL。
首先,创建一个 json 文件:
$ vim /home/hadoop/data/person.json
并向其中写入以下内容:
{"name":"Mirckel"}
{"name":"Andy","age":30}
{"name":"Jsutin","age":13}
下面运行 Spark SQL 案例:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().appName("Spark_SQL_First").getOrCreate()
// 加入隐式转换,将 RDD 转换为 DataFrame
import spark.implicits._
// 读取 json 文件
val df = spark.read.json("/home/hadoop/data/person.json")
df.show()
结果如下图所示:

也可以打印其表结构:
df.printSchema()
结果如下:

Spark SQL 功能丰富,我们也可以像关系型数据库一样进行一些特定的操作,如下所示:
// 使用 select 函数查询特定的列,格式$"列名"
// 将 age 列的值加 1
df.select($"name", $"age" + 1).show()
// 过滤年龄大于 21 岁的
df.filter($"age" > 21).show()
// 按照年龄进行分组
df.groupBy("age").count().show()
结果如下图所示:
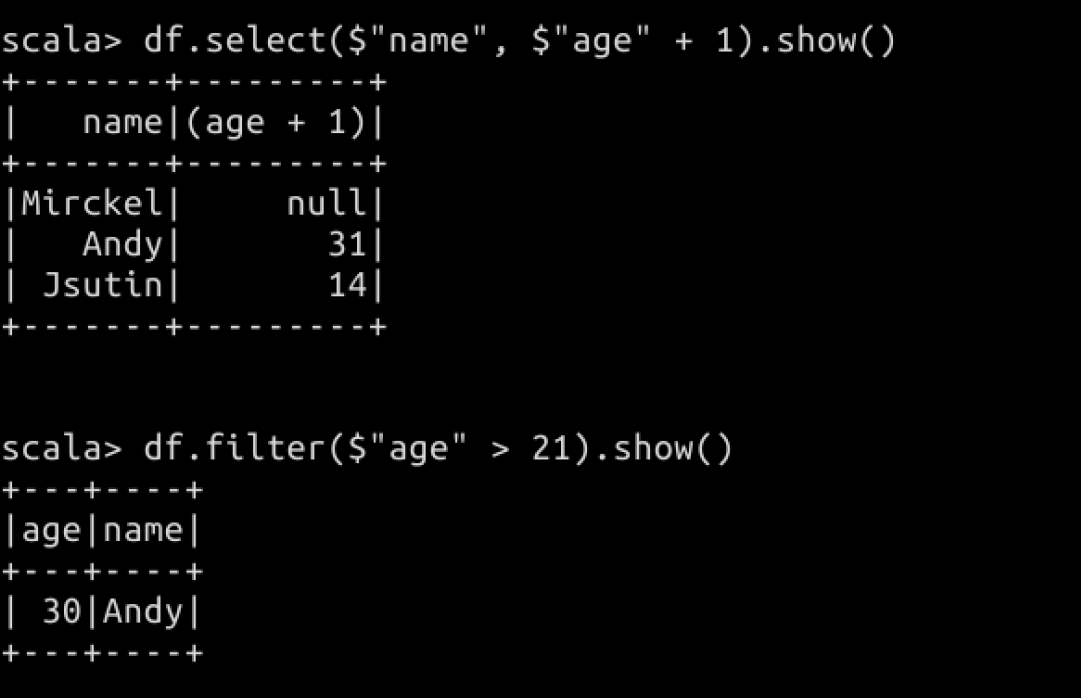
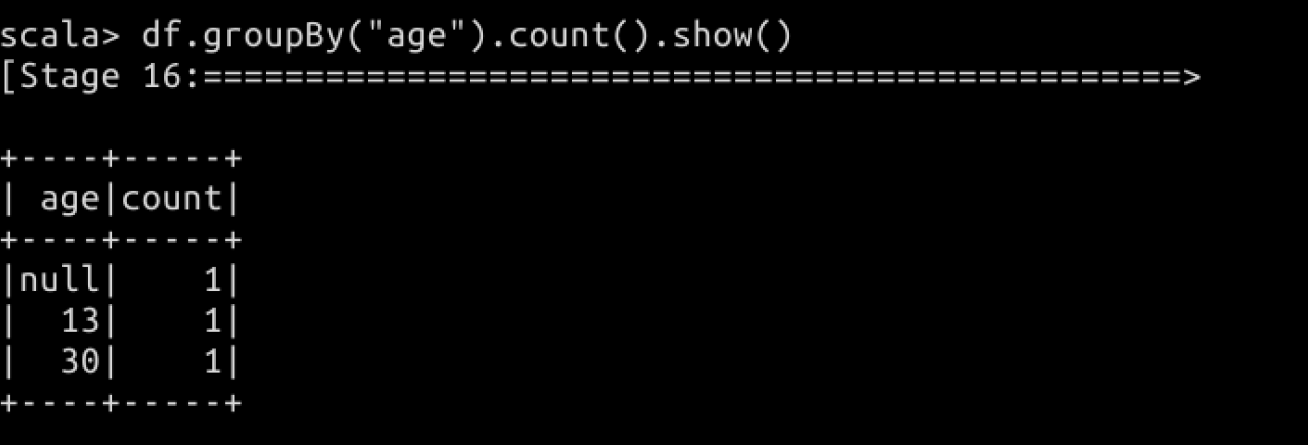
以上是使用 Spark SQL 的一些算子函数来操作,我们也可以像操作关系型数据一样编写 SQL 来操作数据库。
首先将上面的 schema 注册为一张临时表,表名为 people:
df.createOrReplaceTempView("people")
执行 SQL 语句:
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
结果如下:

// 选择年龄小于 20 岁的
spark.sql("SELECT * FROM people where age<20").show()

DataFrames&DataSets
DataFrame
自从 Spark 1.3.0 之后,在原有的 RDD 的基础上,增加了类似 R 风格 DataFrame API,DataFrame 是以指定列(name columns)组织的分布式数据集合,它相当于关系型数据库中的一个表,或者 R/Python 中的 data frame,DataFrame 支持多种数据源的构建。比如,我们可以通过结构化数据文件、Parquet 文件、JSON 文件、外部数据库、Hive 表等外部数据源来操作数据。
DataFrame 和 RDD 的区别
为了便于理解,DataFrame 的数据结构与 RDD 数据结构比较如下图所示:
DataFrame(Person):
| Name | Age | Height |
|---|---|---|
| String | Int | Double |
RDD(Person):
| Person |
|---|
| Person |
不过,DataFrame 也和 RDD 一样,使用惰性加载的特性,它们不直接计算结果,而是将各种变换组装成与 RDD DAG 类似的逻辑查询计划,经过优化的逻辑执行计划被翻译为物理执行计划,并最终落实为 RDD。
DataFrame 操作
在之前介绍 Spark SQL 的使用中,实际上我们已经创建了一个 DataFrame,在这里我们对前面的操作复习一下。
import org.apache.spark.sql.SparkSession
// 创建 Spark Session
val spark = SparkSession.builder().appName("Spark_SQL_First").getOrCreate()
// 读取 json 文件
val df = spark.read.json("/home/hadoop/data/person.json")
df.show()
DataFrame 操作分为 Action,基础 DataFrame 函数,集成语言查询,Output 操作,RDD 操作等。
Action 操作
常用的 DataFrame 的 Action 操作包括 collect、count、first、head、take 等。下面我们来一一动手操作讲解一下。
// 使用 collect 以 Array 形式返回 DataFrame 的所有 Rows
df.collect()

// 使用 count 返回 DataFrame 的所有 Rows 数目
df.count()

// 使用 first 与 head 返回第一行数据
df.first()
df.head()
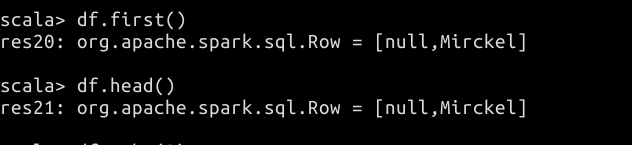
// 使用 take 函数取前 N 条数据,这里取前两条
df.take(2)

DataFrame 基础函数
基础函数包括 cache、columns、dtypes、explain、persist、printSchema 等函数,下面来动手做一做吧。
// 使用 columns 函数查询列名,传入参数为列的索引,从 0 开始
df.columns(0)
df.columns(1)
查询结果如下:

// 使用 dtypes 函数以 Array 形式返回全部的列名和数据结构
df.dtypes
// 也可以指定参数,参数为列名的索引,从0开始,返回指定索引的数据
df.dtypes(0)
df.dtypes(1)
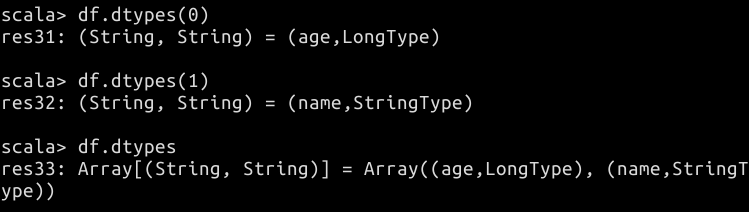
// 使用 explain 打印执行计划到控制台
df.explain()

// 使用 persist 函数数据持久化
df.persist()
在这里需要说明一下,Spark 数据持久化有几种简单的方案。默认的不指定是内存级别的,即 StorageLevel,当内存不够了,可以使用内存加磁盘级别的,最后也可以全部持久化到磁盘,当然默认情况下的性能最优。因此,在内存足够的情况下,我们尽量使用内存级别的持久化方式,这样避免磁盘 IO 带来的性能消耗。
// 打印树形结构的 schema
df.printSchema()

集成语言查询
集成语言查询类似于 SQL 函数,可以参照 SQL,如 filter、intersect、select、sort、where、limit 等操作。
// 使用指定 SQL 进行过滤
df.filter($"age">20).show()
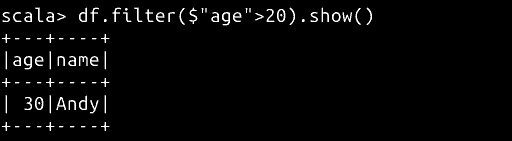
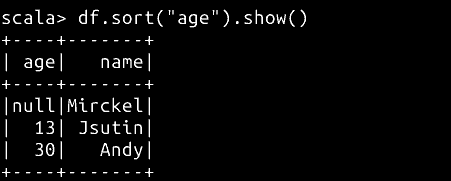
// 使用 sort 按照 age 排序
df.sort("age").show()
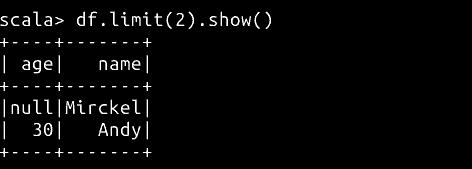
// 使用 Limit 限制打印的条数
df.limit(2).show()
使用 intersect 求与另一个 DataFrame 的交集。
重新打开一个终端,在 /home/hadoop/data 目录下创建一个新的文件 person2.json 并向其中写入如下代码:
{"name":"shinelon","age":20}
{"name":"Andy","age":30}
{"name":"Tome","age":13}
重新创建一个 DataFrame:
val df2 = spark.read.json("/home/hadoop/data/person2.json")
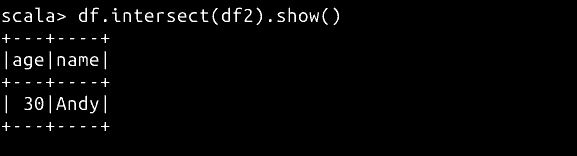
使用 intersect 求两个 DataFrame 的交集:
df.intersect(df2).show()
RDD 转换为 DataFrame
Spark SQL 支持两种不同的方法将现有的 RDD 转换为 DataFrame。
第一种方式使用反射机制来推断一个包含特定类型对象的 RDD 模式,如果能提前知道 Spark 应用程序的 schema,基于这种反射方式让代码变的更为简洁。Spark SQL 反射机制的核心思想是通过特定的 RDD 自动转换为 DataFrame。
第二种方式是通过一个编程接口,允许构建一个 Schema,然后应用到现有的 RDD,这种基于编程接口的方法,允许运行之前,列名及其列类型未知时构建 DataFrame。
以反射机制推断 RDD 模式
在 /home/hadoop/data 目录下创建一个 people.txt 并向其中写入如下代码:
Michael, 29
Andy, 30
Justin, 19
创建好测试数据后开始如下操作:
// 将一个 RDD 隐式转换为一个 DataFrame
import spark.implicits._
// 从文本文件中创建一个 RDD,并且将其转换为 DataFrame
case class Person(name:String,age:Int)
val peopleDF = spark.sparkContext.textFile("/home/hadoop/data/people.txt").map(_.split(",")).map(attr => Person(attr(0), attr(1).trim.toInt)).toDF()
// 注册一张临时表,表名为 people
peopleDF.createOrReplaceTempView("people")
// 使用SQL语句查询 13 到 19 岁之间的 people
val teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19")
// 通过索引查询一条记录
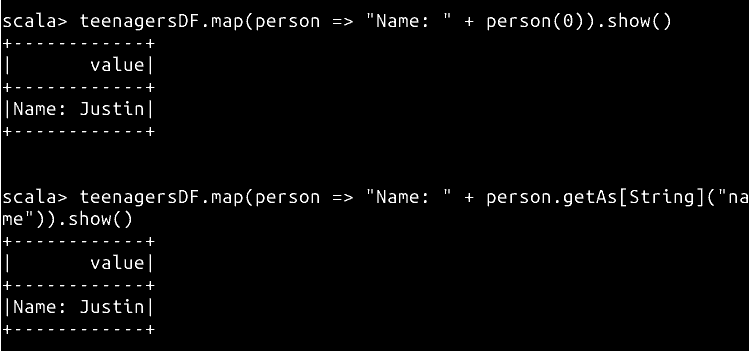
teenagersDF.map(person => "Name: " + person(0)).show()
// 也可以通过字段名来查询
teenagersDF.map(person => "Name: " + person.getAs[String]("name")).show()
// 使用隐式转换 ncoder[Map[String, Any]] = ExpressionEncoder()
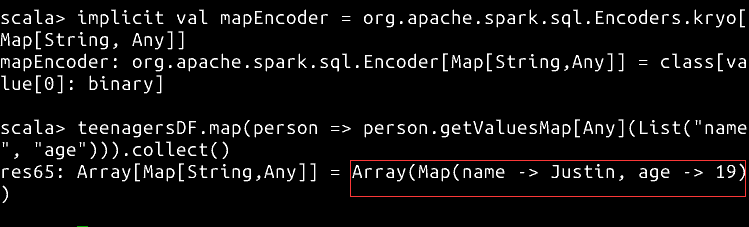
implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]]
// 将所有列按照 list 指定的元素放入一个 map 中
teenagersDF.map(person => person.getValuesMap[Any](List("name", "age"))).collect()
使用编程方式定义 RDD 模式
主要分为以下三个步骤来创建:
- 从原始 RDD 中创建一个 Rows 的 RDD。
- 创建一个表示为 StructType 类型的 Shema,匹配在第一步创建的 RDD 的 Rows 的结构。
- 通过 SparkSession 提供的 createDataFrame 方法,应用 Schema 到 Rows 的 RDD。
代码如下:
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
// 创建一个 RDD
val peopleRDD = spark.sparkContext.textFile("/home/hadoop/data/people.txt")
// 创建一个包含 Schema 的字符串
val schemaString = "name age"
// 创建一个 StructType 类型的 Schema
val fields = schemaString.split(" ").map(fieldName => StructField(fieldName,StringType, nullable = true))
val schema = StructType(fields)
// 将 RDD 转换为 Row
val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim))
// 使用 Row 和 Schema 创建一个 DataFrame
val peopleDF = spark.createDataFrame(rowRDD, schema)
// 创建一张临时表
peopleDF.createOrReplaceTempView("people")
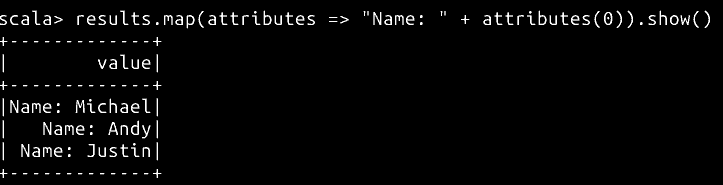
val results = spark.sql("SELECT name FROM people")
// 展示查询的第一个字段的结果
results.map(attributes => "Name: " + attributes(0)).show()
DataSet
DataSet 是在 Spark 1.6.0 之后提出的一个新的接口依赖于 RDD 和 Spark SQL 的 optimized 执行引擎。它是一个分布式的数据集,一个 DataSet 能够通过一个 JVM 对象来构造,然后使用一系列的 transform 操作进行操作(比如 map,filter 等算子)。DataSet 仅仅提供了 java 和 scala 的 API,对 Python 和 R 并没有直接提供 API,但是由于 python 语言的动态性的发展,渐渐的也对 python 支持了 DataSet API。
创建 DataSet
// 创建一个 scala 样例类,类似于 java bean
case class Person(name: String, age: Long)
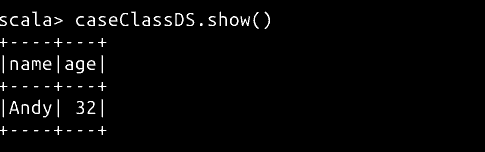
// 创建 DataSet
val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS.show()
// 使用普通的列表来创建一个 DataSet
val seqDS = Seq(1, 2, 3).toDS()
// 使用 map 操作对每个元素迭代计算
seqDS.map(_ *2).collect()

DataFrame 转换为 DataSet
// 将 DataFrame 转换为 DataSet
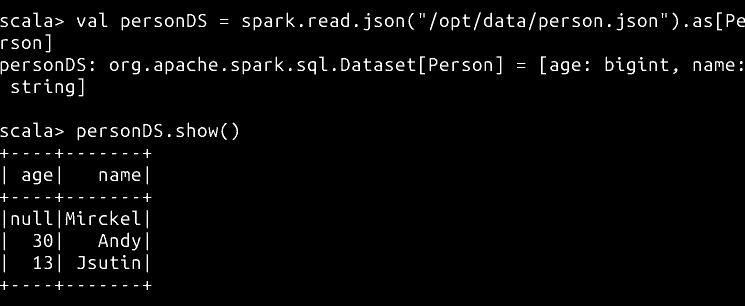
val personDS = spark.read.json("/home/hadoop/data/person.json").as[Person]
personDS.show()
本文由 liyunfei 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jun 24,2022