
- 敏捷开发
- 掌握企业开发流程
- 项目相关面试题
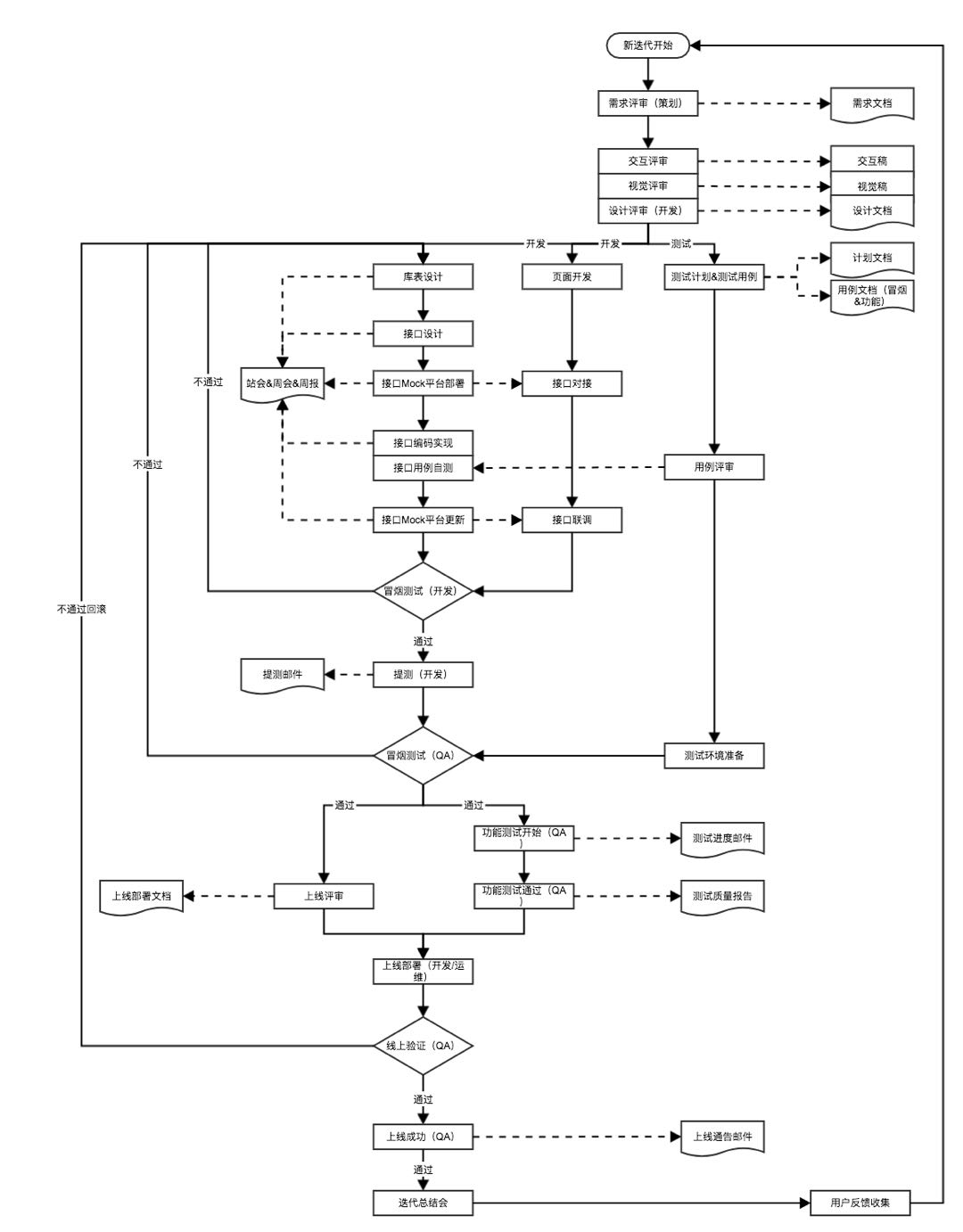
- 项目开发流程
- 设计阶段
- 类图设计–StarUML
- 项目开发(5人)
- 个人开发
- 需求文档
- 需求评审
- 数据库设计-PowerDesign
- 界面伪代码要求
- swagger—接口文档
- 实施阶段
- 答辩阶段
- 项目产出
敏捷开发
流程
阶段
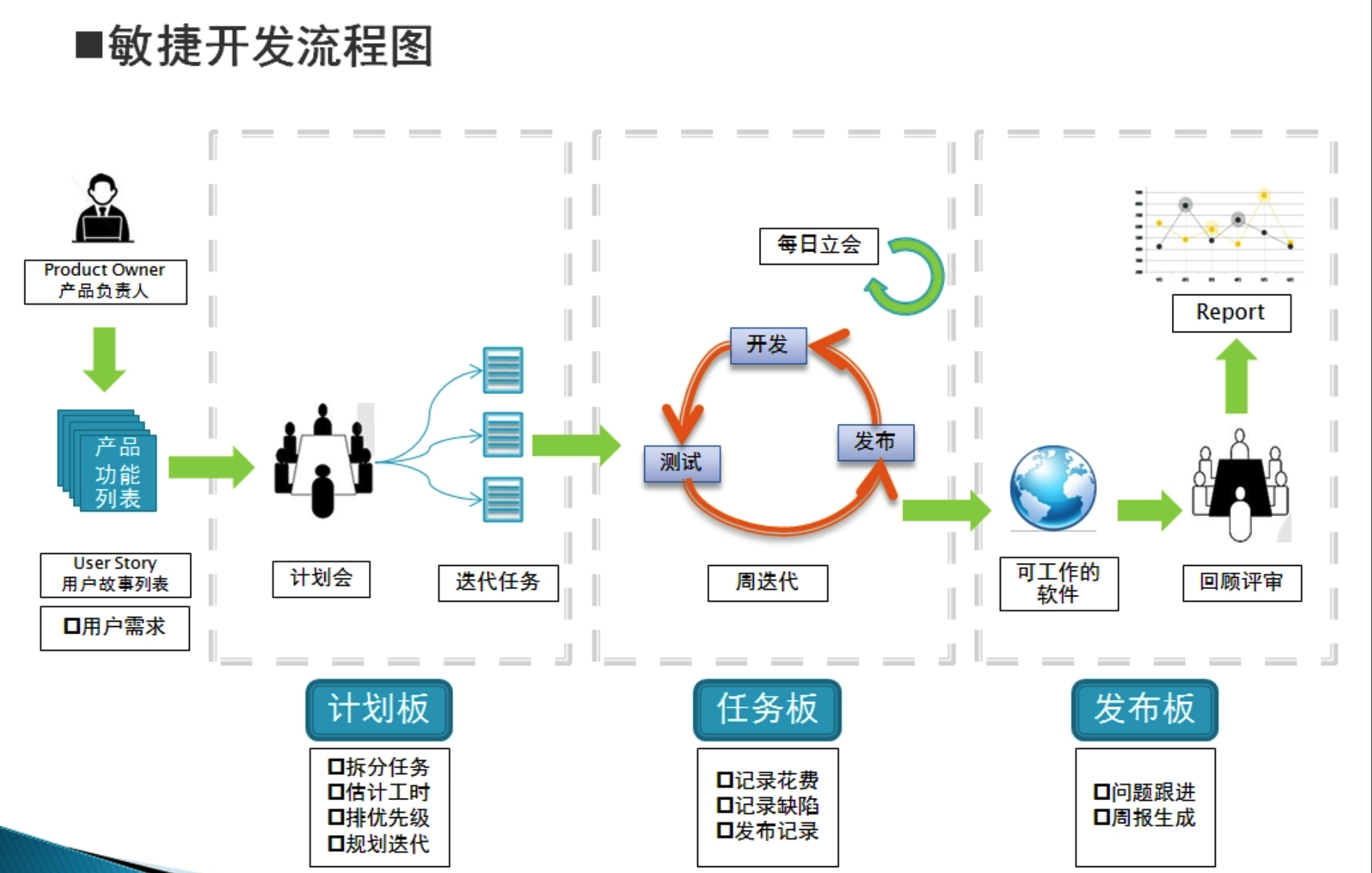
掌握企业开发流程
学校的项目流程时为了保证大家都能把项目做出来.
企业中的项目开发流程和盖房子相似,有需求,设计,开发,测试,上线,运维等流程.
项目相关面试题
面试题1:团队中有几个人,每个人做什么?你做什么?
面试题2:做项目过程中遇到什么难点?如何解决?
面试题3:你的项目上线了吗?
项目开发流程
设计阶段
类图设计–StarUML
包结构
类图详解
StarUML是一款很全面,很好用的UML画图工具。相比PlantUML那种使用代码画图方式,StarUML的拖拽式更简单易用。
StarUML支持类图、时序图、用例图等十几种图形模式。
一. 版本
目前官网http://staruml.io上的最新版本是3.X系列,可进入官网进行下载。下载后理论上是要付费使用的,但是不付费也不太影响使用。
注意,非官方途径可用会发现有5.0版本的starUML,那是比较老的开源版本,建议使用官网上最新版的。
二. 界面说明

说明:默认打开starUML后,会默认进入类图模式,各模块区域功能如下:
1.菜单栏: 最上方是菜单栏,新建工程啥的,具体不详细介绍;
2.已经建类图列表:左上方列表显示已经创建的图,比如类图,时序图等;
3.工具箱:左下方工具箱,显示当前类型的图可以使用的工具,主要是各种连线或者图形,是最常用的区域;
4.绘图区域:中间白色格子区域,就是绘图区域;
5.工程区:右上方区域是工程区,显示工程,model和各种已经绘出的图形;
6.属性编辑区域:当画出来一个图形或者一根线时,这个区域会显示这个图形的各种属性,可以修改;
三. 画图种类介绍
下面介绍各种图的创建和画法。
1. 类图(Class Diagram)
1.打开StarUML
打开后,默认就是画类图的模式

默认创建了一个untitled项目
2.修改工程名字
** 鼠标双击** 【Untitled】
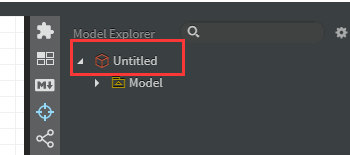
在这里进行填写相关信息

修改后,就变成了你修改的那个名字

3.创建类图
右键 右侧的名字,选择Add Diagram—>ClassDiagram

附上其他的图的意思

此时的目录结构

4.开始画图
拖拽左侧的class到画布上
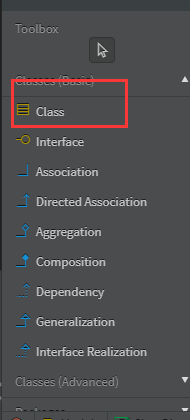
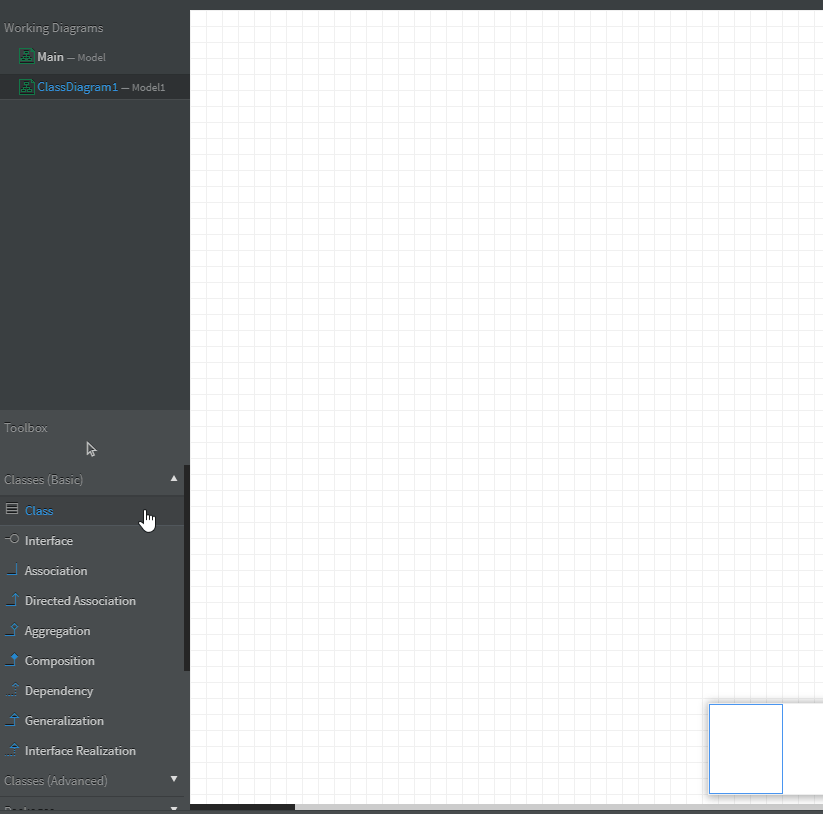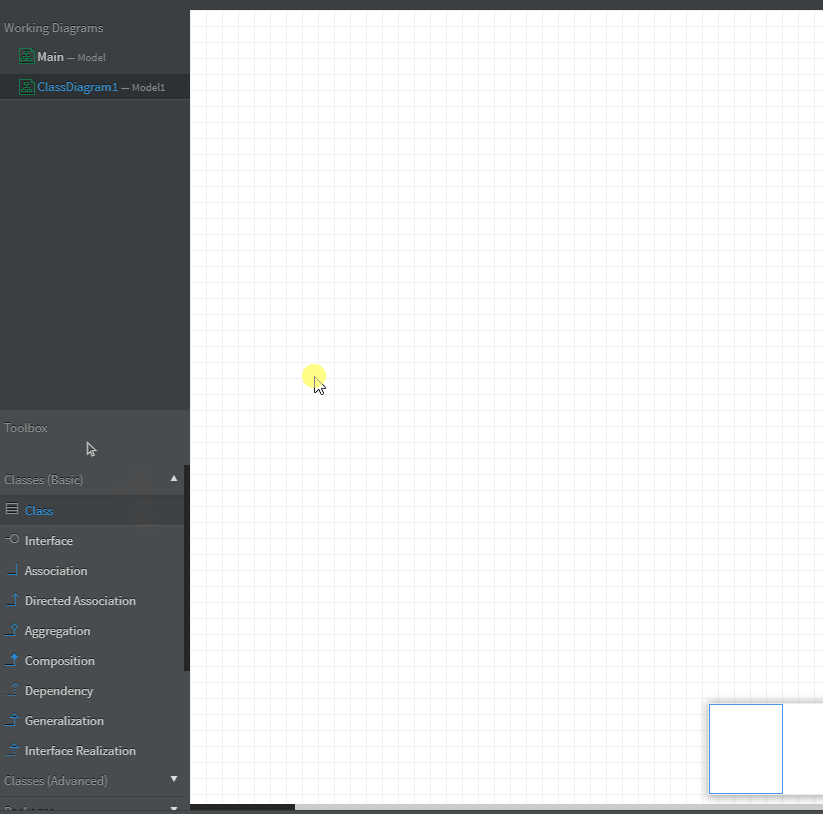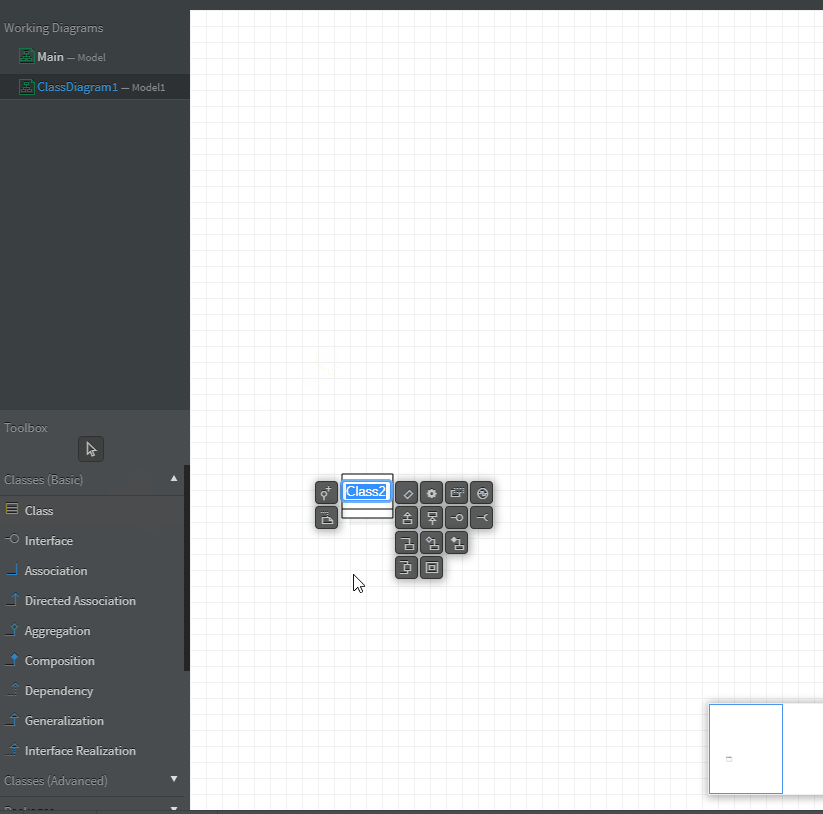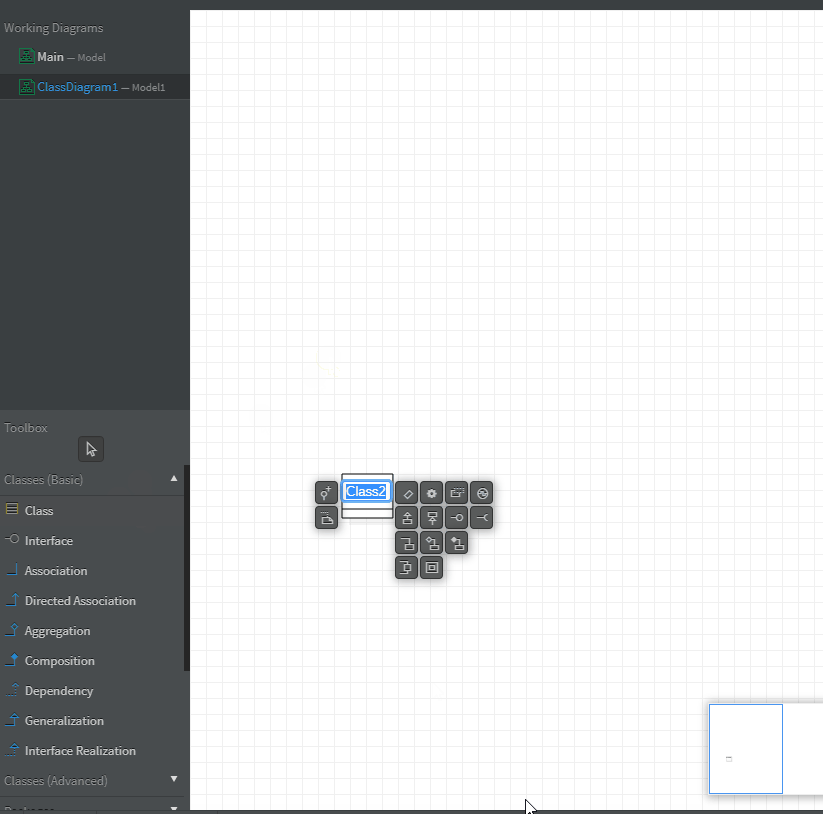
附上其他工具翻译
①命名Class
双击,修改名字

②添加属性
选中类后,右键Add—>Atrribute

在右下角出现的属性进行编辑


③添加方法
同样选中类后,右键Add–>Operation

在右下角出现的编辑框进行编辑

创建完成后,填写方法属性
选中方才创建的方法,右键Add—>Parameter


继续在右下角进行编辑

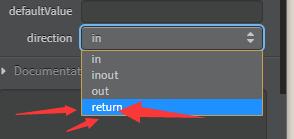
④填写方法返回值
继续上一步骤,添加一个属性,修改type和direction

drection选择retrun
这样一个基本的类图就创建好了,其他的就可以直接根据所需,按照上面进行同样操作即可
附上一个我刚才画好的
 \
\
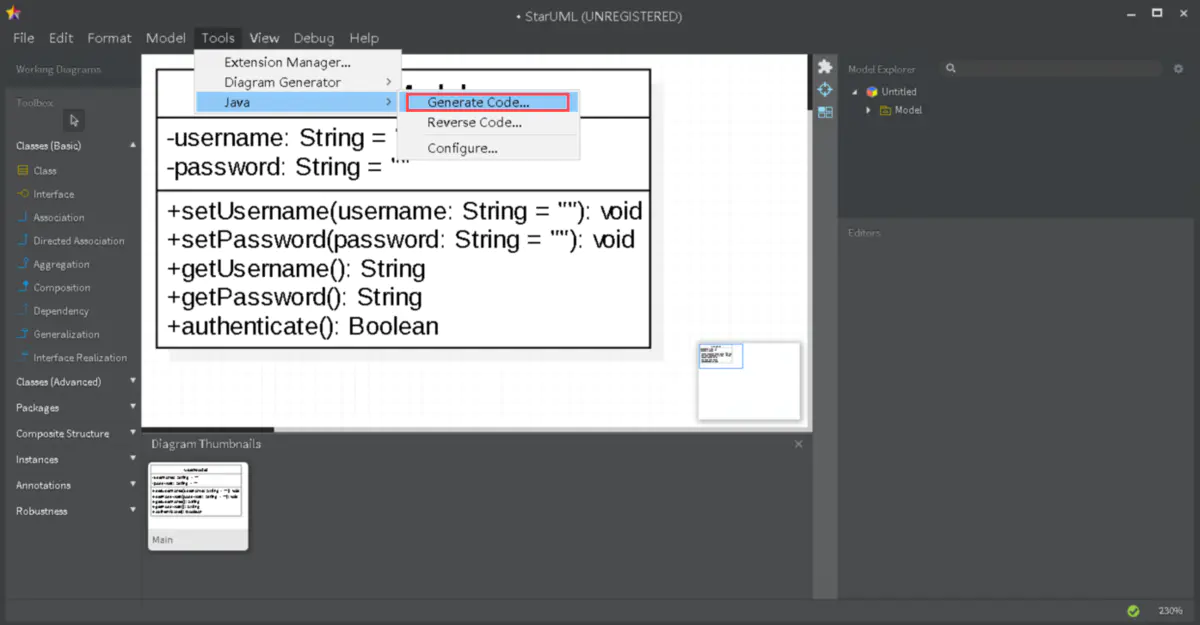
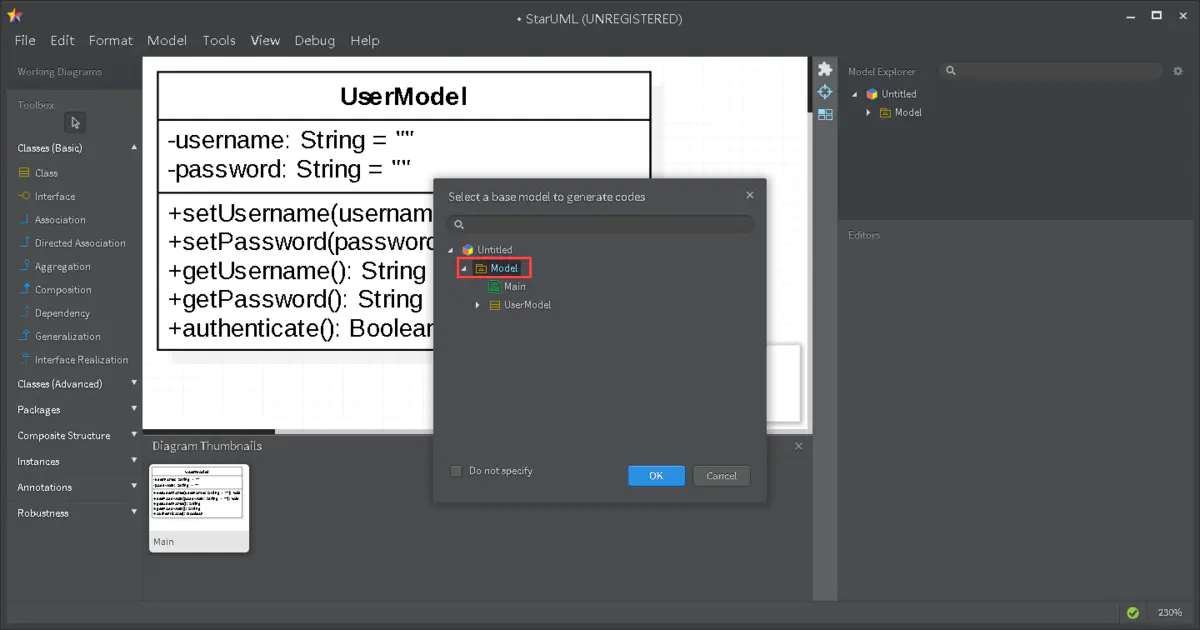
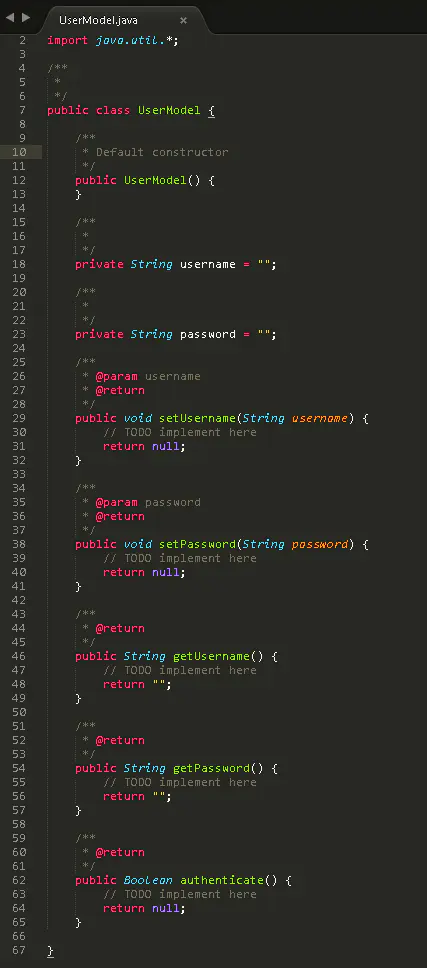
5.导出 Java 代码
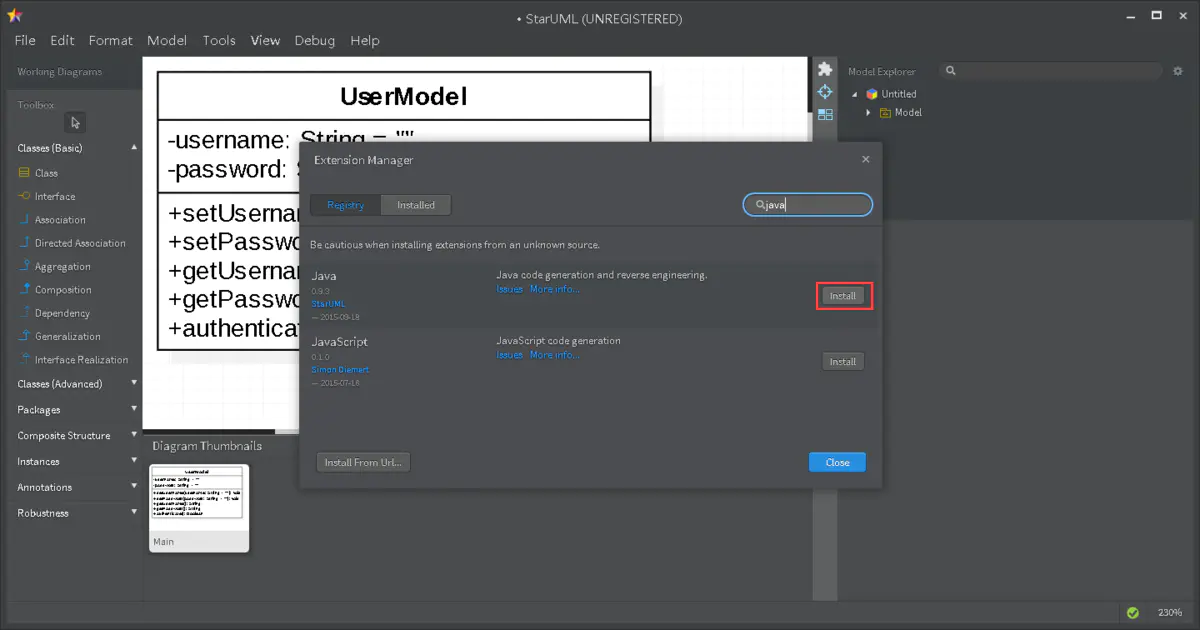
首先在第一次安装 StarUML 的时候是默认不会有导出 Java 代码的功能的
StarUML 的所有扩展功能都通过插件来实现 , 其维护了一个插件商店
需要的插件可以通过在插件商店中搜索得到 , 例如 : Java插件 , php插件 等
首先,下面是一张典型的UML类图:
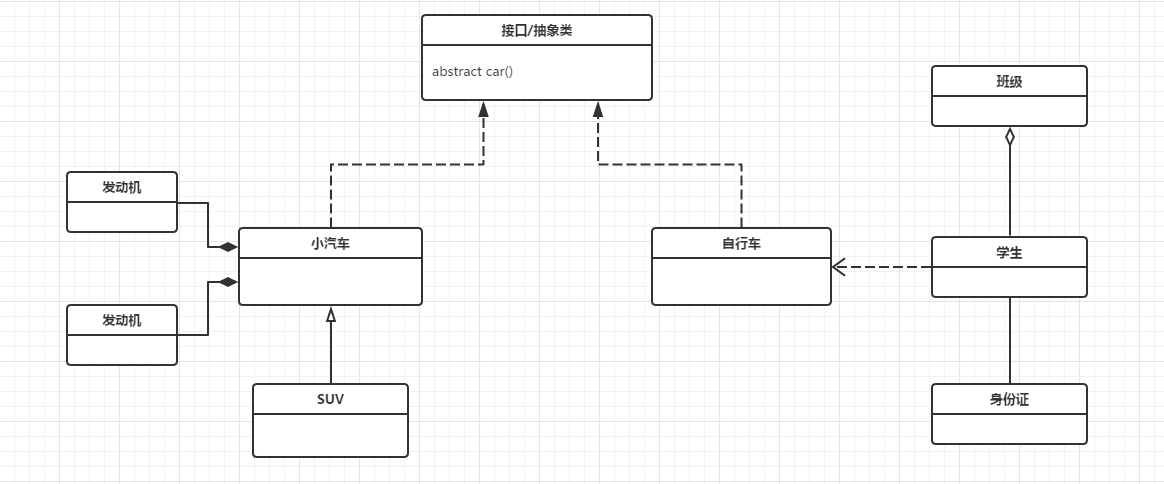
车的类图结构为<>,表示车是一个抽象类;
它有两个继承类:小汽车和自行车;它们之间的关系为实现关系,使用带实心箭头的虚线表示;
小汽车为与SUV之间也是继承关系,它们之间的关系为泛化关系,使用带空心箭头的实线表示;
小汽车与发动机之间是组合关系,使用带实心菱形的实线表示;
学生与班级之间是聚合关系,使用带空心菱形的实线表示;
学生与身份证之间为关联关系,使用一根实线表示;
学生上学需要用到自行车,与自行车是一种依赖关系,使用带箭头的虚线表示;
–上述描述参考: Graphic Design Patterns
UML 类图与类的关系
部分内容参考:UML类图与类的关系详解
向大家推荐一个在线UML类图制作工具:processon
类的关系有泛化(Generalization)、实现(Realization)、依赖(Dependency)和关联(Association)。其中关联又分为一般关联关系和聚合关系(Aggregation),合成关系(Composition)
类图(Class Diagram): 类图是面向对象系统建模中最常用和最重要的图,是定义其它图的基础。类图主要是用来显示系统中的类、接口以及它们之间的静态结构和关系的一种静态模型。
类图的3个基本组件:类名、属性、方法。

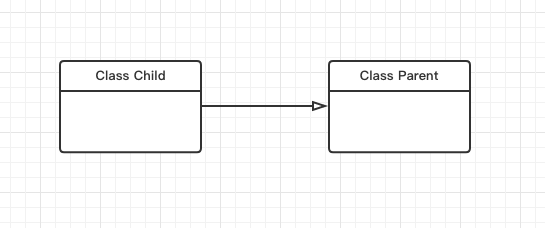
泛化(generalization)
表示is-a的关系,是对象之间耦合度最大的一种关系,子类继承父类的所有细节。直接使用语言中的继承表达。在类图中使用带三角空心箭头的实线表示,箭头从子类指向父类。
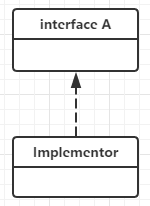
实现(Realization)
在类图中就是接口和实现的关系。在类图中使用带三角实心箭头的虚线表示,箭头从实现类指向接口。
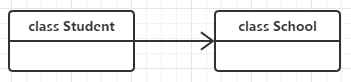
关联关系(association)
关联关系是用一条带箭头的直线表示的;它描述不同类的对象之间的结构关系;它是一种静态关系, 通常与运行状态无关,一般由常识等因素决定的;它一般用来定义对象之间静态的、天然的结构; 所以,关联关系是一种“强关联”的关系;
学生与学校是一种关联关系。
依赖(Dependency)
依赖关系是用一套带箭头的虚线表示的;如下图表示A依赖于B;他描述一个对象在运行期间会用到另一个对象的关系;
对象之间最弱的一种关联方式,是临时性的关联。代码中一般指由局部变量、函数参数、返回值建立的对于其他对象的调用关系。一个类调用被依赖类中的某些方法而得以完成这个类的一些职责。在类图使用带箭头的虚线表示,箭头从使用类指向被依赖的类。
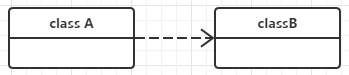
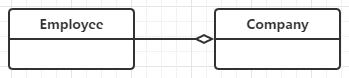
聚合(Aggregation)
表示has-a的关系,是一种不稳定的包含关系。较强于一般关联,有整体与局部的关系,并且没有了整体,局部也可单独存在。如公司和员工的关系,公司包含员工,但如果公司倒闭,员工依然可以换公司。在类图使用空心的菱形表示,菱形从局部指向整体。
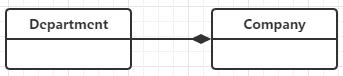
组合(Composition)
表示contains-a的关系,是一种强烈的包含关系。组合类负责被组合类的生命周期。是一种更强的聚合关系。部分不能脱离整体存在。如公司和部门的关系,没有了公司,部门也不能存在了;调查问卷中问题和选项的关系;订单和订单选项的关系。在类图使用实心的菱形表示,菱形从局部指向整体。
聚合和组合的区别
这两个比较难理解,重点说一下。聚合和组合的区别在于:聚合关系是“has-a”关系,组合关系是“contains-a”关系;聚合关系表示整体与部分的关系比较弱,而组合比较强;聚合关系中代表部分事物的对象与代表聚合事物的对象的生存期无关,一旦删除了聚合对象不一定就删除了代表部分事物的对象。组合中一旦删除了组合对象,同时也就删除了代表部分事物的对象。
2. 用例图(Use Case Diagram)
有了上面类图的介绍,创建一个用例图流程,就很简单了:
工程区-》选择Model-》右键-》选择【Add Diagram】-》选择【Use Case Diagram】,然后你就会发现,左下角工具箱变成了用例图的模式:

下面是随便画的用例图:

3. 时序图(Sequence Diagram)
工程区-》选择Model-》右键-》选择【Add Diagram】-》选择【Sequence Diagram】,然后你就会发现,左下角工具箱变成了时序图的模式:

下面是随便画的时序图:

4. 组件图(Component Diagram)
下面是随便画的组件图:

5. 部署图(Deployment Diagram)
下面是随便画的部署图:
6. 协作图(Comunication Diagram)
下面是随便画的协作图:

7. 对象图(Object Diagram)
下面是随便画的对象图:

8. 活动图(Activity Diagram)
下面是随便画的活动图:

项目开发(5人)
选出组长----技术好,管理,沟通,责任
第一版功能必须简单,5张表,一人一张表.
第二版加功能.
个人开发
个人能力强:自己写需求,写设计.边写边设计.
需求文档

原型
制作原型的步骤
1.分析需求
罗列出原型需要实现的需求。
2.了解功能分布
功能的层级关系。
3.明确页面层级
页面之间有明确存在的层级关系,每一层实现的功能与存在的元素。
4.绘制基本原型
5.检验,修改原型
往往第一次制作的都会被打回,做好心理准备吧。

需求文档

1.需求背景与目标说明
你得让别人知道你为什么要做,要做到什么程度,用户检验功能完成情况。
2.特性列表
所谓特性,其实就是功能模块,把需要做的功能模块都罗列出来,主要用于明确需要做的功能有哪些,用图表体现更佳
拆分标准:
1.内部逻辑(不同的功能模块,不同的页面)
2.重要的特性单独列出,例如提示语
3.主要逻辑
每个特性之下的操作逻辑,简单特性可以文字说明,复杂特性建议用流程图表现。
帮助梳理逻辑,减少细节遗留。
4.特性功能点
补充每个功能点的相关细节描述,是开发,与测试工作的重要依据。
包括:
1.流程细节描述。
2.正常逻辑表现,异常逻辑表现。
3.文案内容,性能需求。
4.交互图(可无)
5.特性需求,性能需求,数据上报
这一部分类似备注,说明了做这个功能要达到怎样的程度,需要再哪些地方进行数据埋点。
6.版本号记录,迭代说明
便于回顾整个过程,进行复盘。
撰写需求文档四步走
1.想-需求
三思而后行,下笔之前想清楚你的需求,需求就是一份文字版的问题解决方案:
你想做什么功能?
这个功能主要的用户是谁?
这个功能重要吗?优先级高吗?
这个功能的流程想清楚了吗?还有极端情况没有考虑吗?
…
2.列-特性
性清楚后,列出你需要做的所有功能特性:
功能特性
界面特性
性能要求
数据上报
操作流程
3.写-初稿
根据特性点,开始写初稿,按照一定的逻辑分特性,遵循MECE原则,要求做到:
需求结构完整
逻辑清晰
描述准确
4.补-细节
重读整份文档,找出不足之处进行补充。把自己代入各个相关负责人的职位当中,看看自己能否准确明白文档的内容。
需求评审
数据库设计-PowerDesign
前端数据库设计
后台管理系统数据库设计
项目整体功能结构
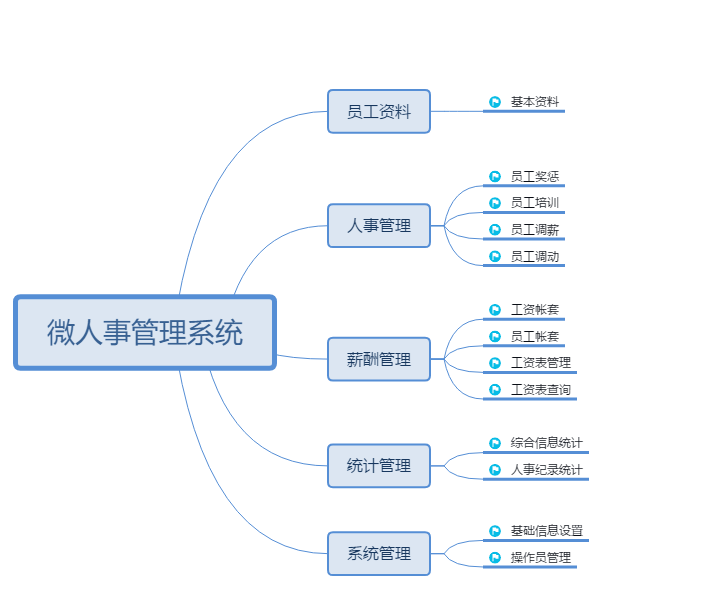
项目总共分为五大功能模块,分别是员工资料、人事管理、薪酬管理、统计管理和系统管理, 各个功能模块有很多小的功能,本次课程将按照各个功能模块来依次实现它们的功能。
后端 vhr 源码(本次课程只需要用到这个后端代码,前端代码已经生成添加到其中了,具体的启动流程在这次实验中有详细讲解):
wget https://labfile.oss.aliyuncs.com/courses/1346/vhr.zip
前端 vuehr 源码(本次实验主要讲解后端 java 代码,前端代码提供给大家作参考,实验中不会用到,也可以进行二次开发,二次开发流程在这次实验中有详细讲解):
wget https://labfile.oss.aliyuncs.com/courses/1346/vuehr.zip
重要数据库设计
这里我们将讲解一些重要数据库的设计,主要是权限管理相关的数据库和部门数据库的讲解,其它的数据库都属于一些比较常规设计,大家可以下载源码在vhr.sql中查看。
配合项目,我们需要创建 vhr 数据库,具体命令如下:
进入 mysql
mysql -u root
创建数据库 vhr
create database vhr;
然后进入 vhr 数据库,根据 vhr.sql 的内容完成数据库的表设计以及数据。
权限数据库设计
权限数据库主要包含了五张表,分别是资源表、角色表、用户表、资源角色表、用户角色表,数据库关系模型如下:
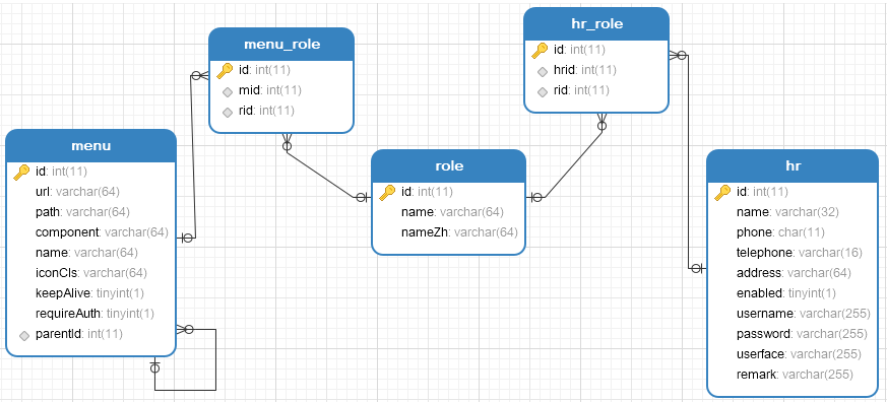
关于这个表,我说如下几点:
1.hr 表是用户表,存放了用户的基本信息。
2.role 是角色表,name 字段表示角色的英文名称,按照 SpringSecurity 的规范,将以 ROLE_开始,nameZh 字段表示角色的中文名称。
3.menu 表是一个资源表,该表涉及到的字段有点多,由于我的前端采用了 Vue 来做,因此当用户登录成功之后,系统将根据用户的角色动态加载需要的模块,所有模块的信息将保存在 menu 表中,menu 表中的 path、component、iconCls、keepAlive、requireAuth 等字段都是 Vue-Router 中需要的字段,也就是说 menu 中的数据到时候会以 json 的形式返回给前端,再由 vue 动态更新 router,menu 中还有一个字段 url,表示一个 url pattern,即路径匹配规则,假设有一个路径匹配规则为/admin/** 那么当用户在客户端发起一个/admin/user 的请求,将被/admin/** 拦截到,系统再去查看这个规则对应的角色是哪些,然后再去查看该用户是否具备相应的角色,进而判断该请求是否合法。
部门数据库设计
部门数据库整体来说还是比较简单的,如下:
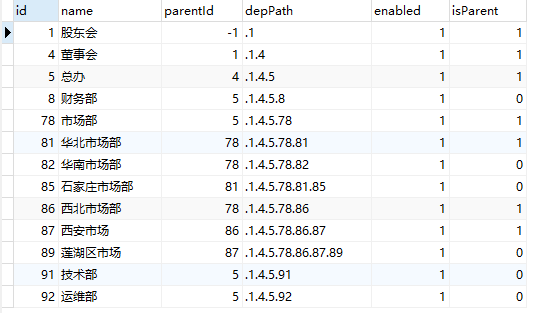
depPath 是为了查询方便,isParent 表示该条是否是父部门。为了简化程序中的逻辑,depPath 的设置和 isParent 的设置我都在存储过程中完成。如果大家不了解 MySQL 的存储过程可以去看一下这个链接中的教程 https://www.runoob.com/w3cnote/mysql-stored-procedure.html
2.2.1 添加部门存储过程
添加部门存储过程如下:
DROP PROCEDURE IF EXISTS `addDep`;
delimiter ;;
CREATE DEFINER=`root`@`localhost` PROCEDURE `addDep`(in depName varchar(32),in parentId int,in enabled boolean,out result int,out result2 int)
begin
declare did int;
declare pDepPath varchar(64);
insert into department set name=depName,parentId=parentId,enabled=enabled;
select row_count() into result;
select last_insert_id() into did;
set result2=did;
select depPath into pDepPath from department where id=parentId;
update department set depPath=concat(pDepPath,'.',did) where id=did;
update department set isParent=true where id=parentId;
end
;;
delimiter ;
关于这个存储过程,我说如下几点:
1.该存储过程接收五个参数,三个输入参数分别是部门名称、父部门 Id,该部门是否启用,两个输出参数分别表示受影响的行数和插入成功后 id 的值。
2.存储过程首先执行插入操作,插入完成后,将受影响行数赋值给 result。
3.然后通过 last_insert_id()获取刚刚插入的 id,赋给 result2。
4.接下来查询父部门的 depPath,并且和刚刚生成的 id 组合后作为刚刚插入部门的 depPath。
5.将父部门的 isParent 字段更新为 true。
将这些逻辑写在存储过程中,可以简化我们代码中的逻辑。
2.2.2 删除部门存储过程
删除部门也被我写成了存储过程,主要是因为删除过程也要做好几件事,核心代码如下:
DROP PROCEDURE IF EXISTS `deleteDep`;
delimiter ;;
CREATE DEFINER=`root`@`localhost` PROCEDURE `deleteDep`(in did int,out result int)
begin
declare ecount int;
declare pid int;
declare pcount int;
select count(*) into ecount from employee where departmentId=did;
if ecount>0 then set result=-1;
else
select parentId into pid from department where id=did;
delete from department where id=did and isParent=false;
select row_count() into result;
select count(*) into pcount from department where parentId=pid;
if pcount=0 then update department set isParent=false where id=pid;
end if;
end if;
end
;;
delimiter ;
关于这个存储过程,我说如下几点:
1.一个输入参数表示要删除数据的 id,一个输出参数表示删除结果。
2.如果该部门下有员工,则该部门不能被删除。
3.删除该部门时注意加上条件 isParent=false,即父部门不能被删除,这一点我在前端已经做了判断,正常情况下父部门的删除请求不会被发送,但是考虑到前端的数据不能被信任,所以后台我们也要限制。
4.删除成功之后,查询删除部门的父部门是否还有其他子部门,如果没有,则将父部门的 isParent 修改为 false。
界面伪代码要求
swagger—接口文档
Swagger 是一个规范且完整的框架,用于生成、描述、调用和可视化 RESTful 风格的 Web 服务。
Swagger 的目标是对 REST API 定义一个标准且和语言无关的接口,可以让人和计算机拥有无须访问源码、文档或网络流量监测就可以发现和理解服务的能力。当通过 Swagger 进行正确定义,用户可以理解远程服务并使用最少实现逻辑与远程服务进行交互。与为底层编程所实现的接口类似,Swagger 消除了调用服务时可能会有的猜测。
swagger,一款致力于解决接口规范化、标准化、文档化的开源库,一款真正的开发神器。
Swagger是一款RESTFUL接口的文档在线自动生成+功能测试功能软件。Swagger是一个规范和完整的框架,用于生成、描述、调用和可视化RESTful风格的Web服务。目标是使客户端和文件系统作为服务器以同样的速度来更新文件的方法,参数和模型紧密集成到服务器。
这个解释简单点来讲就是说,swagger是一款可以根据resutful风格生成的生成的接口开发文档,并且支持做测试的一款中间软件。
Swagger 的优势
- 支持 API 自动生成同步的在线文档:使用 Swagger 后可以直接通过代码生成文档,不再需要自己手动编写接口文档了,对程序员来说非常方便,可以节约写文档的时间去学习新技术。
- 提供 Web 页面在线测试 API:光有文档还不够,Swagger 生成的文档还支持在线测试。参数和格式都定好了,直接在界面上输入参数对应的值即可在线测试接口。
对于后端开发人员来说
- 不用再手写WiKi接口拼大量的参数,避免手写错误
- 对代码侵入性低,采用全注解的方式,开发简单
- 方法参数名修改、增加、减少参数都可以直接生效,不用手动维护
- 缺点:增加了开发成本,写接口还得再写一套参数配置
对于前端开发来说
- 后端只需要定义好接口,会自动生成文档,接口功能、参数一目了然
- 联调方便,如果出问题,直接测试接口,实时检查参数和返回值,就可以快速定位是前端还是后端的问题
对于测试
- 对于某些没有前端界面UI的功能,可以用它来测试接口
- 操作简单,不用了解具体代码就可以操作
- 操作简单,不用了解具体代码就可以操作
集成 Swagger 管理 API 文档
1)项目中集成 Swagger
集成 Swagger 我们使用封装好了的 Starter 包,代码如下所示。
<!-- Swagger -->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.7.0</version>
</dependency>
在启动类中使用 @EnableSwagger2Doc 开启 Swagger,代码如下所示。
@Configuration
@EnableSwagger2
public class SwaggerConfig {
@Bean
public Docket productApi() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
.apis(RequestHandlerSelectors.withMethodAnnotation(ApiOperation.class)) //添加ApiOperiation注解的被扫描
.paths(PathSelectors.any())
.build();
}
private ApiInfo apiInfo() {
return new ApiInfoBuilder().title(”swagger和springBoot整合“).description(”swagger的API文档")
.version("1.0").build();
}
}
使用的时候直接粘贴到启动类中,修改title中的信息即可.
2)使用 Swagger 生成文档
Swagger 是通过注解的方式来生成对应的 API,在接口上我们需要加上各种注解来描述这个接口,关于 Swagger 注解的使用在教程后面会有详细讲解,本节只是带大家快速使用 Swagger,使用方法代码如下所示。
@ApiOperation(value = "新增用户")
@ApiResponses({ @ApiResponse(code = 200, message = "OK", response = UserDto.class) })
@PostMapping("/user")
public UserDto addUser(@RequestBody AddUserParam param) {
System.err.println(param.getName());
return new UserDto();
}
参数类定义代码如下所示。
@Data
@ApiModel(value = "com.biancheng.auth.param.AddUserParam", description = "新增用户参数")
public class AddUserParam {
@ApiModelProperty(value = "ID")
private String id;
@ApiModelProperty(value = "名称")
private String name;
@ApiModelProperty(value = "年龄")
private int age;
}
在线测试接口
接口查看地址可以通过服务地址 /swagger-ui.html 来访问
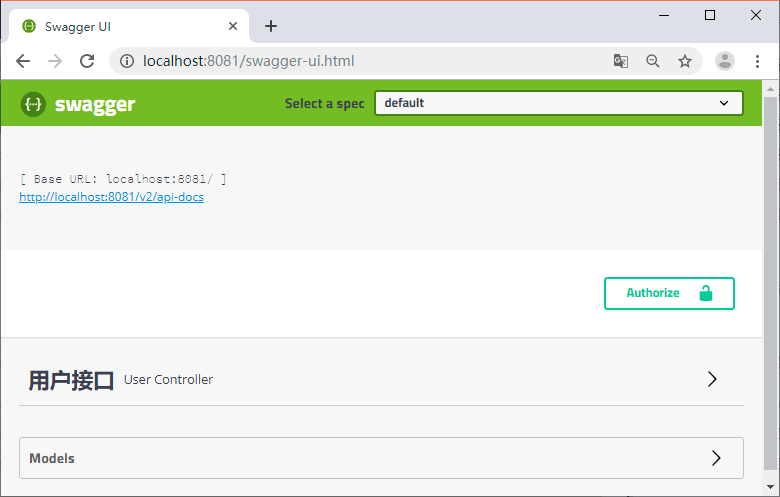
可以展开看详情
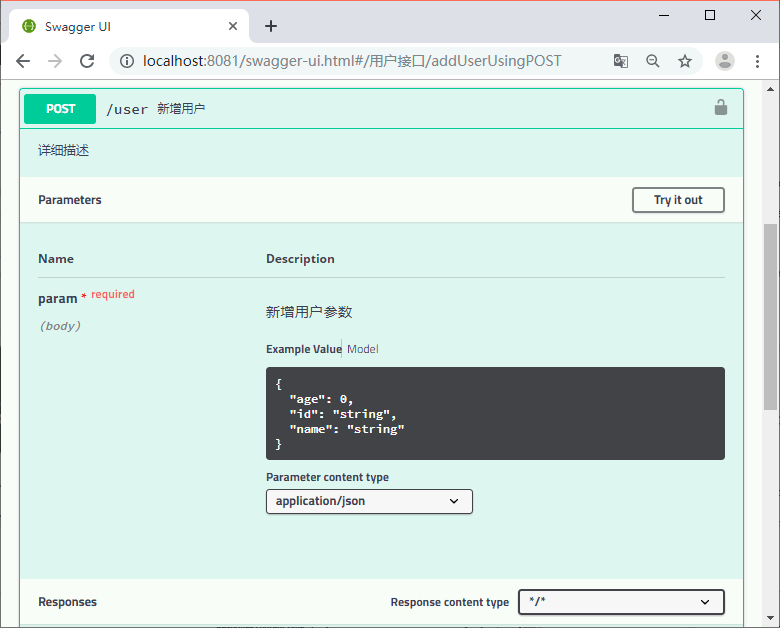
在 param 中输入参数,点击 Try it out 按钮可以调用接口
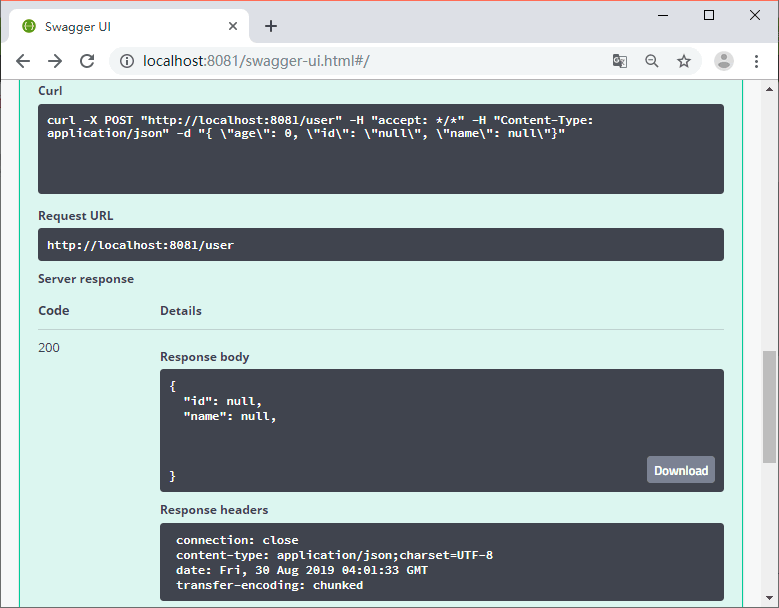
接口调用
请求方法
请求参数
返回的JSON数据包
实施阶段
版本控制系统使用
每个程序员负责一个包.
程序员只提交自己负责的包,程序员不要提交公共文件夹,否则公共文件夹中的文件会发生冲突,项目经理第一次可以提交公共文件夹.
如果代码冲突了,先下载代码,手动解决冲突.
不能下载代码或不能上传代码,解决方法是重新clone项目.
编码进度
安装配置手册
答辩阶段
答辩文档
项目产出
-
需求和评审文档
-
数据库设计和评审文档
-
类图设计文档
-
伪代码
-
接口文档
本文由 liyunfei 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Aug 19,2022